 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHD-EPIC: A Highly-Detailed Egocentric Video Dataset
Feb 06, 2025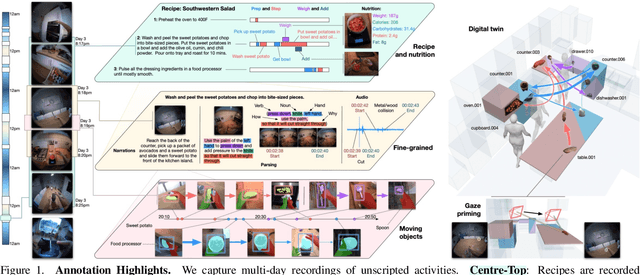
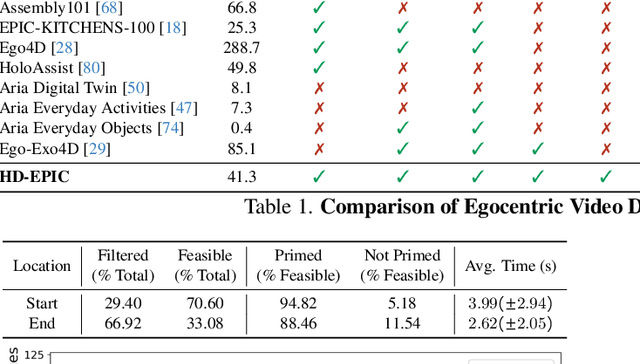

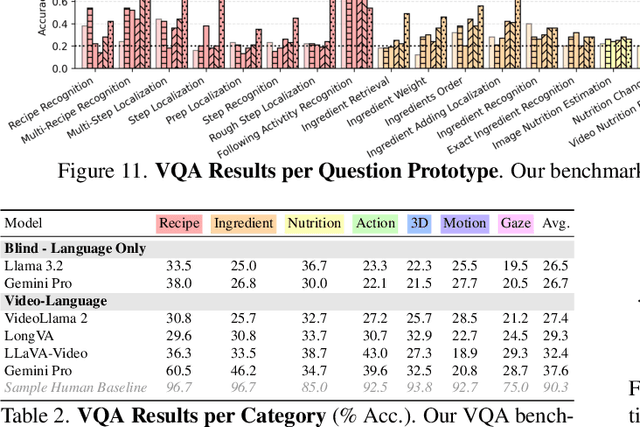
We present a validation dataset of newly-collected kitchen-based egocentric videos, manually annotated with highly detailed and interconnected ground-truth labels covering: recipe steps, fine-grained actions, ingredients with nutritional values, moving objects, and audio annotations. Importantly, all annotations are grounded in 3D through digital twinning of the scene, fixtures, object locations, and primed with gaze. Footage is collected from unscripted recordings in diverse home environments, making HDEPIC the first dataset collected in-the-wild but with detailed annotations matching those in controlled lab environments. We show the potential of our highly-detailed annotations through a challenging VQA benchmark of 26K questions assessing the capability to recognise recipes, ingredients, nutrition, fine-grained actions, 3D perception, object motion, and gaze direction. The powerful long-context Gemini Pro only achieves 38.5% on this benchmark, showcasing its difficulty and highlighting shortcomings in current VLMs. We additionally assess action recognition, sound recognition, and long-term video-object segmentation on HD-EPIC. HD-EPIC is 41 hours of video in 9 kitchens with digital twins of 413 kitchen fixtures, capturing 69 recipes, 59K fine-grained actions, 51K audio events, 20K object movements and 37K object masks lifted to 3D. On average, we have 263 annotations per minute of our unscripted videos.
It's Just Another Day: Unique Video Captioning by Discriminative Prompting
Oct 15, 2024



Long videos contain many repeating actions, events and shots. These repetitions are frequently given identical captions, which makes it difficult to retrieve the exact desired clip using a text search. In this paper, we formulate the problem of unique captioning: Given multiple clips with the same caption, we generate a new caption for each clip that uniquely identifies it. We propose Captioning by Discriminative Prompting (CDP), which predicts a property that can separate identically captioned clips, and use it to generate unique captions. We introduce two benchmarks for unique captioning, based on egocentric footage and timeloop movies - where repeating actions are common. We demonstrate that captions generated by CDP improve text-to-video R@1 by 15% for egocentric videos and 10% in timeloop movies.
Spatial Cognition from Egocentric Video: Out of Sight, Not Out of Mind
Apr 07, 2024



As humans move around, performing their daily tasks, they are able to recall where they have positioned objects in their environment, even if these objects are currently out of sight. In this paper, we aim to mimic this spatial cognition ability. We thus formulate the task of Out of Sight, Not Out of Mind - 3D tracking active objects using observations captured through an egocentric camera. We introduce Lift, Match and Keep (LMK), a method which lifts partial 2D observations to 3D world coordinates, matches them over time using visual appearance, 3D location and interactions to form object tracks, and keeps these object tracks even when they go out-of-view of the camera - hence keeping in mind what is out of sight. We test LMK on 100 long videos from EPIC-KITCHENS. Our results demonstrate that spatial cognition is critical for correctly locating objects over short and long time scales. E.g., for one long egocentric video, we estimate the 3D location of 50 active objects. Of these, 60% can be correctly positioned in 3D after 2 minutes of leaving the camera view.
Centre Stage: Centricity-based Audio-Visual Temporal Action Detection
Nov 28, 2023Previous one-stage action detection approaches have modelled temporal dependencies using only the visual modality. In this paper, we explore different strategies to incorporate the audio modality, using multi-scale cross-attention to fuse the two modalities. We also demonstrate the correlation between the distance from the timestep to the action centre and the accuracy of the predicted boundaries. Thus, we propose a novel network head to estimate the closeness of timesteps to the action centre, which we call the centricity score. This leads to increased confidence for proposals that exhibit more precise boundaries. Our method can be integrated with other one-stage anchor-free architectures and we demonstrate this on three recent baselines on the EPIC-Kitchens-100 action detection benchmark where we achieve state-of-the-art performance. Detailed ablation studies showcase the benefits of fusing audio and our proposed centricity scores. Code and models for our proposed method are publicly available at https://github.com/hanielwang/Audio-Visual-TAD.git
What can a cook in Italy teach a mechanic in India? Action Recognition Generalisation Over Scenarios and Locations
Jun 14, 2023



We propose and address a new generalisation problem: can a model trained for action recognition successfully classify actions when they are performed within a previously unseen scenario and in a previously unseen location? To answer this question, we introduce the Action Recognition Generalisation Over scenarios and locations dataset (ARGO1M), which contains 1.1M video clips from the large-scale Ego4D dataset, across 10 scenarios and 13 locations. We demonstrate recognition models struggle to generalise over 10 proposed test splits, each of an unseen scenario in an unseen location. We thus propose CIR, a method to represent each video as a Cross-Instance Reconstruction of videos from other domains. Reconstructions are paired with text narrations to guide the learning of a domain generalisable representation. We provide extensive analysis and ablations on ARGO1M that show CIR outperforms prior domain generalisation works on all test splits. Code and data: https://chiaraplizz.github.io/what-can-a-cook/.
Use Your Head: Improving Long-Tail Video Recognition
Apr 03, 2023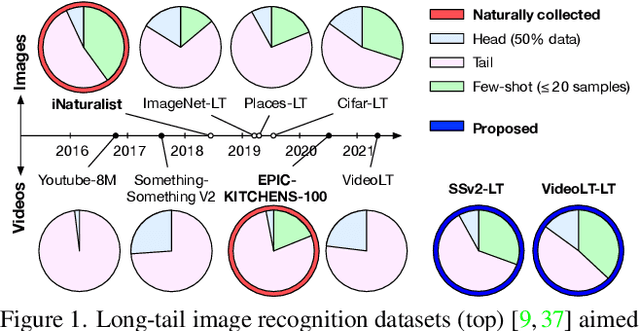
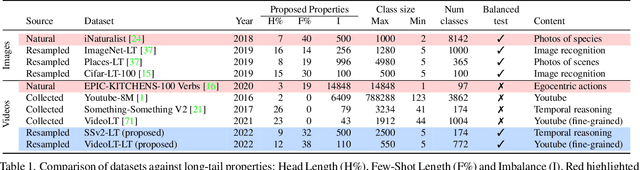
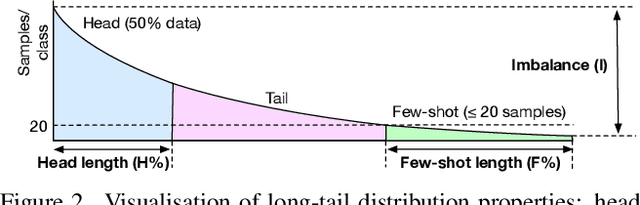

This paper presents an investigation into long-tail video recognition. We demonstrate that, unlike naturally-collected video datasets and existing long-tail image benchmarks, current video benchmarks fall short on multiple long-tailed properties. Most critically, they lack few-shot classes in their tails. In response, we propose new video benchmarks that better assess long-tail recognition, by sampling subsets from two datasets: SSv2 and VideoLT. We then propose a method, Long-Tail Mixed Reconstruction, which reduces overfitting to instances from few-shot classes by reconstructing them as weighted combinations of samples from head classes. LMR then employs label mixing to learn robust decision boundaries. It achieves state-of-the-art average class accuracy on EPIC-KITCHENS and the proposed SSv2-LT and VideoLT-LT. Benchmarks and code at: tobyperrett.github.io/lmr
Refining Action Boundaries for One-stage Detection
Oct 25, 2022Current one-stage action detection methods, which simultaneously predict action boundaries and the corresponding class, do not estimate or use a measure of confidence in their boundary predictions, which can lead to inaccurate boundaries. We incorporate the estimation of boundary confidence into one-stage anchor-free detection, through an additional prediction head that predicts the refined boundaries with higher confidence. We obtain state-of-the-art performance on the challenging EPIC-KITCHENS-100 action detection as well as the standard THUMOS14 action detection benchmarks, and achieve improvement on the ActivityNet-1.3 benchmark.
Inertial Hallucinations -- When Wearable Inertial Devices Start Seeing Things
Jul 14, 2022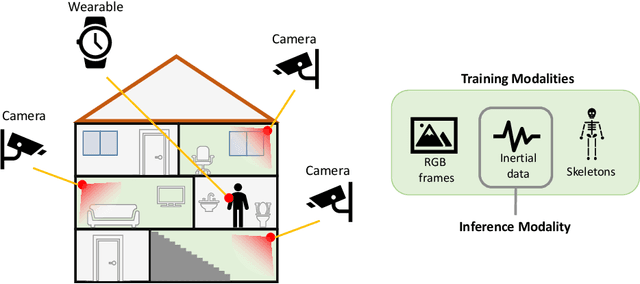

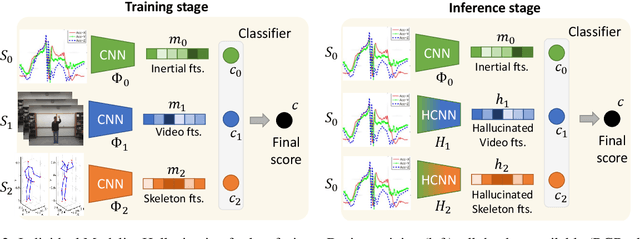
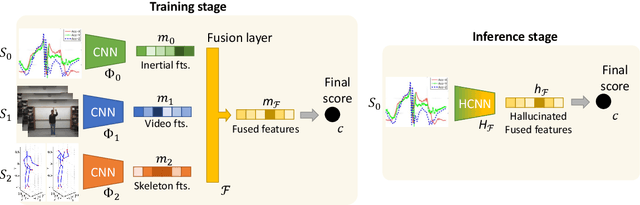
We propose a novel approach to multimodal sensor fusion for Ambient Assisted Living (AAL) which takes advantage of learning using privileged information (LUPI). We address two major shortcomings of standard multimodal approaches, limited area coverage and reduced reliability. Our new framework fuses the concept of modality hallucination with triplet learning to train a model with different modalities to handle missing sensors at inference time. We evaluate the proposed model on inertial data from a wearable accelerometer device, using RGB videos and skeletons as privileged modalities, and show an improvement of accuracy of an average 6.6% on the UTD-MHAD dataset and an average 5.5% on the Berkeley MHAD dataset, reaching a new state-of-the-art for inertial-only classification accuracy on these datasets. We validate our framework through several ablation studies.
An Evaluation of OCR on Egocentric Data
Jun 11, 2022
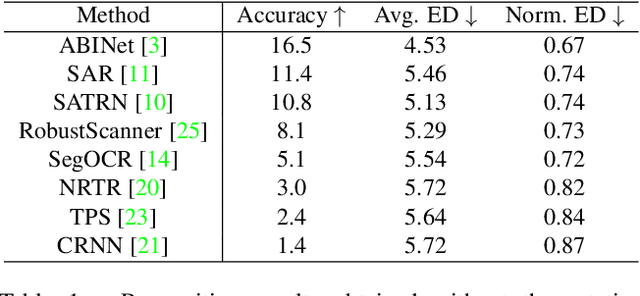
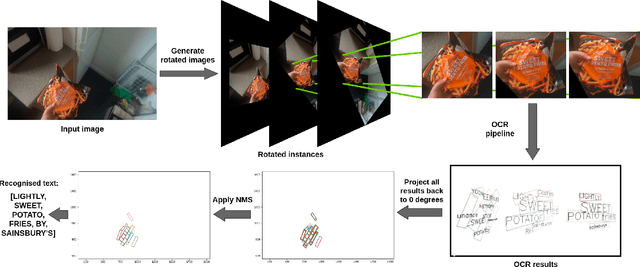
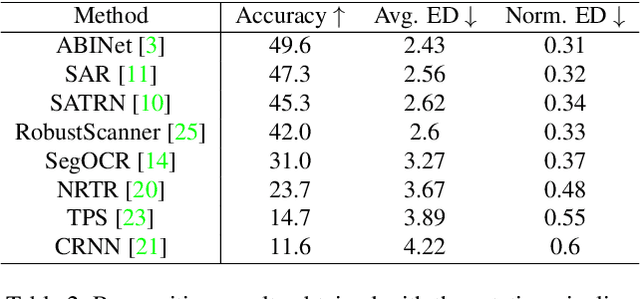
In this paper, we evaluate state-of-the-art OCR methods on Egocentric data. We annotate text in EPIC-KITCHENS images, and demonstrate that existing OCR methods struggle with rotated text, which is frequently observed on objects being handled. We introduce a simple rotate-and-merge procedure which can be applied to pre-trained OCR models that halves the normalized edit distance error. This suggests that future OCR attempts should incorporate rotation into model design and training procedures.
TVNet: Temporal Voting Network for Action Localization
Jan 02, 2022
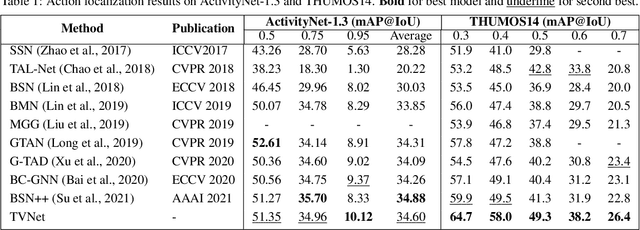
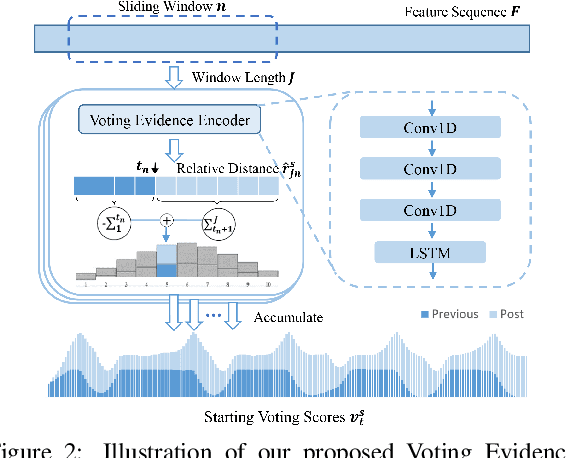
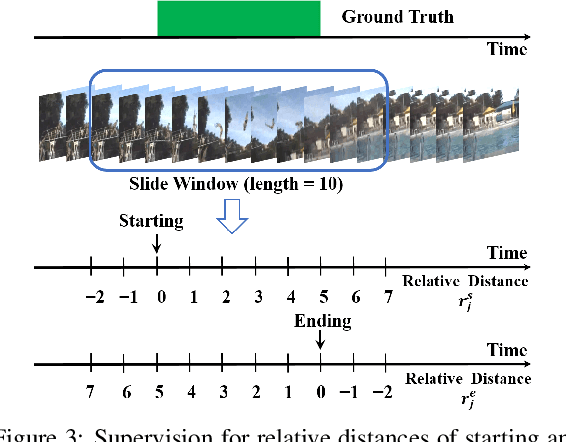
We propose a Temporal Voting Network (TVNet) for action localization in untrimmed videos. This incorporates a novel Voting Evidence Module to locate temporal boundaries, more accurately, where temporal contextual evidence is accumulated to predict frame-level probabilities of start and end action boundaries. Our action-independent evidence module is incorporated within a pipeline to calculate confidence scores and action classes. We achieve an average mAP of 34.6% on ActivityNet-1.3, particularly outperforming previous methods with the highest IoU of 0.95. TVNet also achieves mAP of 56.0% when combined with PGCN and 59.1% with MUSES at 0.5 IoU on THUMOS14 and outperforms prior work at all thresholds. Our code is available at https://github.com/hanielwang/TVNet.