 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrchestrating Specialized Agents for Trustworthy Enterprise RAG
Jan 26, 2026Retrieval-Augmented Generation (RAG) shows promise for enterprise knowledge work, yet it often underperforms in high-stakes decision settings that require deep synthesis, strict traceability, and recovery from underspecified prompts. One-pass retrieval-and-write pipelines frequently yield shallow summaries, inconsistent grounding, and weak mechanisms for completeness verification. We introduce ADORE (Adaptive Deep Orchestration for Research in Enterprise), an agentic framework that replaces linear retrieval with iterative, user-steered investigation coordinated by a central orchestrator and a set of specialized agents. ADORE's key insight is that a structured Memory Bank (a curated evidence store with explicit claim-evidence linkage and section-level admissible evidence) enables traceable report generation and systematic checks for evidence completeness. Our contributions are threefold: (1) Memory-locked synthesis - report generation is constrained to a structured Memory Bank (Claim-Evidence Graph) with section-level admissible evidence, enabling traceable claims and grounded citations; (2) Evidence-coverage-guided execution - a retrieval-reflection loop audits section-level evidence coverage to trigger targeted follow-up retrieval and terminates via an evidence-driven stopping criterion; (3) Section-packed long-context grounding - section-level packing, pruning, and citation-preserving compression make long-form synthesis feasible under context limits. Across our evaluation suite, ADORE ranks first on DeepResearch Bench (52.65) and achieves the highest head-to-head preference win rate on DeepConsult (77.2%) against commercial systems.
Spatial Cognition from Egocentric Video: Out of Sight, Not Out of Mind
Apr 07, 2024



As humans move around, performing their daily tasks, they are able to recall where they have positioned objects in their environment, even if these objects are currently out of sight. In this paper, we aim to mimic this spatial cognition ability. We thus formulate the task of Out of Sight, Not Out of Mind - 3D tracking active objects using observations captured through an egocentric camera. We introduce Lift, Match and Keep (LMK), a method which lifts partial 2D observations to 3D world coordinates, matches them over time using visual appearance, 3D location and interactions to form object tracks, and keeps these object tracks even when they go out-of-view of the camera - hence keeping in mind what is out of sight. We test LMK on 100 long videos from EPIC-KITCHENS. Our results demonstrate that spatial cognition is critical for correctly locating objects over short and long time scales. E.g., for one long egocentric video, we estimate the 3D location of 50 active objects. Of these, 60% can be correctly positioned in 3D after 2 minutes of leaving the camera view.
The More You See in 2D, the More You Perceive in 3D
Apr 04, 2024



Humans can infer 3D structure from 2D images of an object based on past experience and improve their 3D understanding as they see more images. Inspired by this behavior, we introduce SAP3D, a system for 3D reconstruction and novel view synthesis from an arbitrary number of unposed images. Given a few unposed images of an object, we adapt a pre-trained view-conditioned diffusion model together with the camera poses of the images via test-time fine-tuning. The adapted diffusion model and the obtained camera poses are then utilized as instance-specific priors for 3D reconstruction and novel view synthesis. We show that as the number of input images increases, the performance of our approach improves, bridging the gap between optimization-based prior-less 3D reconstruction methods and single-image-to-3D diffusion-based methods. We demonstrate our system on real images as well as standard synthetic benchmarks. Our ablation studies confirm that this adaption behavior is key for more accurate 3D understanding.
Humans in 4D: Reconstructing and Tracking Humans with Transformers
May 31, 2023We present an approach to reconstruct humans and track them over time. At the core of our approach, we propose a fully "transformerized" version of a network for human mesh recovery. This network, HMR 2.0, advances the state of the art and shows the capability to analyze unusual poses that have in the past been difficult to reconstruct from single images. To analyze video, we use 3D reconstructions from HMR 2.0 as input to a tracking system that operates in 3D. This enables us to deal with multiple people and maintain identities through occlusion events. Our complete approach, 4DHumans, achieves state-of-the-art results for tracking people from monocular video. Furthermore, we demonstrate the effectiveness of HMR 2.0 on the downstream task of action recognition, achieving significant improvements over previous pose-based action recognition approaches. Our code and models are available on the project website: https://shubham-goel.github.io/4dhumans/.
ABO: Dataset and Benchmarks for Real-World 3D Object Understanding
Oct 12, 2021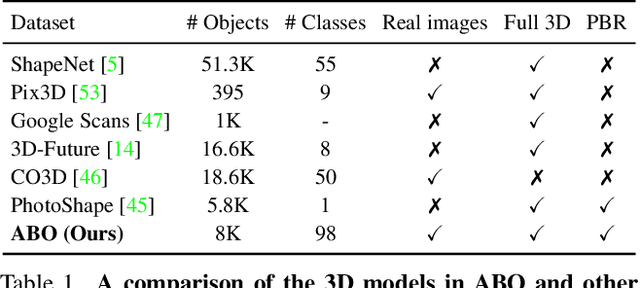
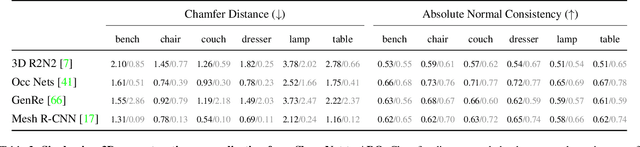
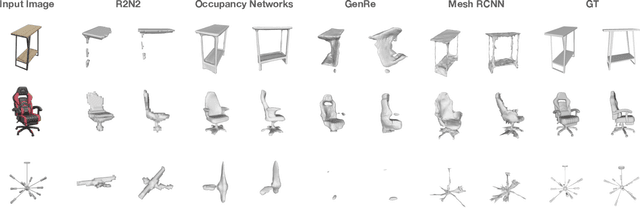
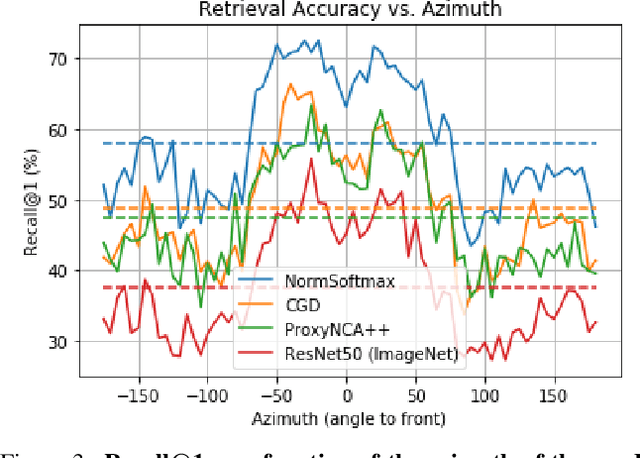
We introduce Amazon-Berkeley Objects (ABO), a new large-scale dataset of product images and 3D models corresponding to real household objects. We use this realistic, object-centric 3D dataset to measure the domain gap for single-view 3D reconstruction networks trained on synthetic objects. We also use multi-view images from ABO to measure the robustness of state-of-the-art metric learning approaches to different camera viewpoints. Finally, leveraging the physically-based rendering materials in ABO, we perform single- and multi-view material estimation for a variety of complex, real-world geometries. The full dataset is available for download at https://amazon-berkeley-objects.s3.amazonaws.com/index.html.
Differentiable Stereopsis: Meshes from multiple views using differentiable rendering
Oct 11, 2021
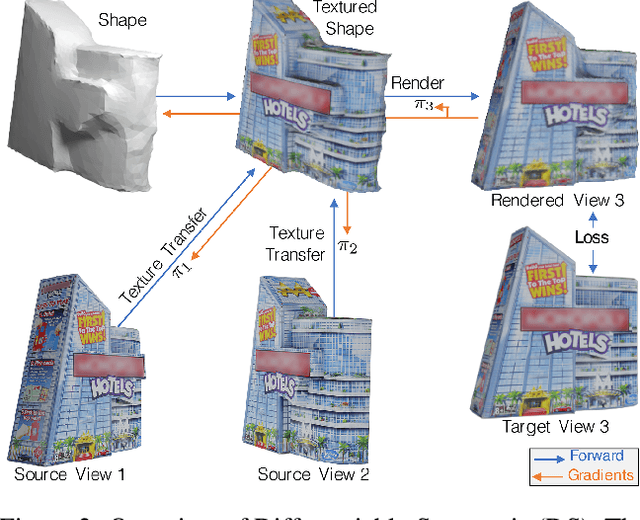
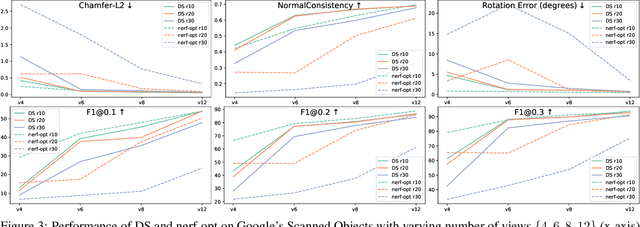

We propose Differentiable Stereopsis, a multi-view stereo approach that reconstructs shape and texture from few input views and noisy cameras. We pair traditional stereopsis and modern differentiable rendering to build an end-to-end model which predicts textured 3D meshes of objects with varying topologies and shape. We frame stereopsis as an optimization problem and simultaneously update shape and cameras via simple gradient descent. We run an extensive quantitative analysis and compare to traditional multi-view stereo techniques and state-of-the-art learning based methods. We show compelling reconstructions on challenging real-world scenes and for an abundance of object types with complex shape, topology and texture. Project webpage: https://shubham-goel.github.io/ds/
Shape and Viewpoint without Keypoints
Jul 21, 2020

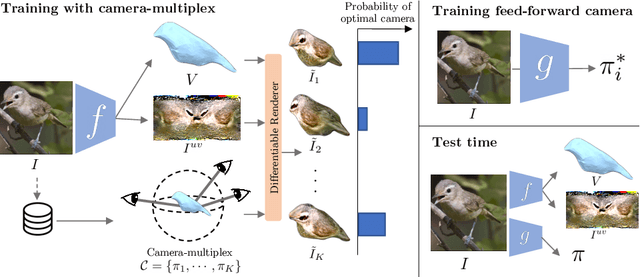
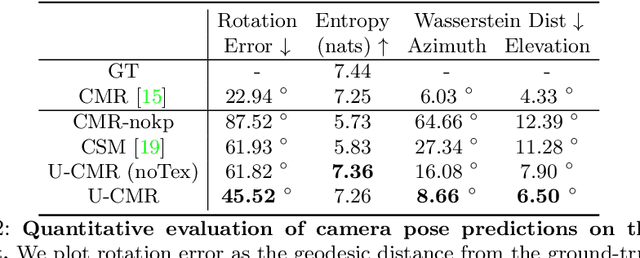
We present a learning framework that learns to recover the 3D shape, pose and texture from a single image, trained on an image collection without any ground truth 3D shape, multi-view, camera viewpoints or keypoint supervision. We approach this highly under-constrained problem in a "analysis by synthesis" framework where the goal is to predict the likely shape, texture and camera viewpoint that could produce the image with various learned category-specific priors. Our particular contribution in this paper is a representation of the distribution over cameras, which we call "camera-multiplex". Instead of picking a point estimate, we maintain a set of camera hypotheses that are optimized during training to best explain the image given the current shape and texture. We call our approach Unsupervised Category-Specific Mesh Reconstruction (U-CMR), and present qualitative and quantitative results on CUB, Pascal 3D and new web-scraped datasets. We obtain state-of-the-art camera prediction results and show that we can learn to predict diverse shapes and textures across objects using an image collection without any keypoint annotations or 3D ground truth. Project page: https://shubham-goel.github.io/ucmr