 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOfficeQA Pro: An Enterprise Benchmark for End-to-End Grounded Reasoning
Mar 09, 2026We introduce OfficeQA Pro, a benchmark for evaluating AI agents on grounded, multi-document reasoning over a large and heterogeneous document corpus. The corpus consists of U.S. Treasury Bulletins spanning nearly 100 years, comprising 89,000 pages and over 26 million numerical values. OfficeQA Pro consists of 133 questions that require precise document parsing, retrieval, and analytical reasoning across both unstructured text and tabular data. Frontier LLMs including Claude Opus 4.6, GPT-5.4, and Gemini 3.1 Pro Preview achieve less than 5% accuracy on OfficeQA Pro when relying on parametric knowledge, and less than 12% with additional access to the web. When provided directly with the document corpus, frontier agents still struggle on over half of questions, scoring 34.1% on average. We find that providing agents with a structured document representation produced by Databricks' ai_parse_document yields a 16.1% average relative performance gain across agents. We conduct additional ablations to study the effects of model selection, table representation, retrieval strategy, and test-time scaling on performance. Despite these improvements, significant headroom remains before agents can be considered reliable at enterprise-grade grounded reasoning.
What Makes a Good Generated Image? Investigating Human and Multimodal LLM Image Preference Alignment
Sep 16, 2025
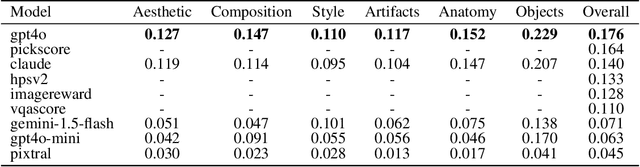

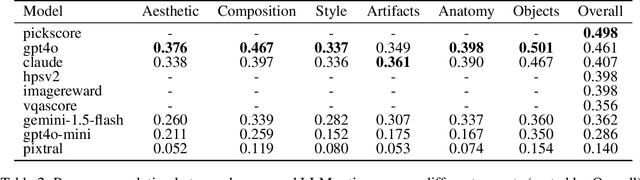
Automated evaluation of generative text-to-image models remains a challenging problem. Recent works have proposed using multimodal LLMs to judge the quality of images, but these works offer little insight into how multimodal LLMs make use of concepts relevant to humans, such as image style or composition, to generate their overall assessment. In this work, we study what attributes of an image--specifically aesthetics, lack of artifacts, anatomical accuracy, compositional correctness, object adherence, and style--are important for both LLMs and humans to make judgments on image quality. We first curate a dataset of human preferences using synthetically generated image pairs. We use inter-task correlation between each pair of image quality attributes to understand which attributes are related in making human judgments. Repeating the same analysis with LLMs, we find that the relationships between image quality attributes are much weaker. Finally, we study individual image quality attributes by generating synthetic datasets with a high degree of control for each axis. Humans are able to easily judge the quality of an image with respect to all of the specific image quality attributes (e.g. high vs. low aesthetic image), however we find that some attributes, such as anatomical accuracy, are much more difficult for multimodal LLMs to learn to judge. Taken together, these findings reveal interesting differences between how humans and multimodal LLMs perceive images.
CommonCanvas: An Open Diffusion Model Trained with Creative-Commons Images
Oct 25, 2023



We assemble a dataset of Creative-Commons-licensed (CC) images, which we use to train a set of open diffusion models that are qualitatively competitive with Stable Diffusion 2 (SD2). This task presents two challenges: (1) high-resolution CC images lack the captions necessary to train text-to-image generative models; (2) CC images are relatively scarce. In turn, to address these challenges, we use an intuitive transfer learning technique to produce a set of high-quality synthetic captions paired with curated CC images. We then develop a data- and compute-efficient training recipe that requires as little as 3% of the LAION-2B data needed to train existing SD2 models, but obtains comparable quality. These results indicate that we have a sufficient number of CC images (~70 million) for training high-quality models. Our training recipe also implements a variety of optimizations that achieve ~3X training speed-ups, enabling rapid model iteration. We leverage this recipe to train several high-quality text-to-image models, which we dub the CommonCanvas family. Our largest model achieves comparable performance to SD2 on a human evaluation, despite being trained on our CC dataset that is significantly smaller than LAION and using synthetic captions for training. We release our models, data, and code at https://github.com/mosaicml/diffusion/blob/main/assets/common-canvas.md
CA$^2$T-Net: Category-Agnostic 3D Articulation Transfer from Single Image
Jan 05, 2023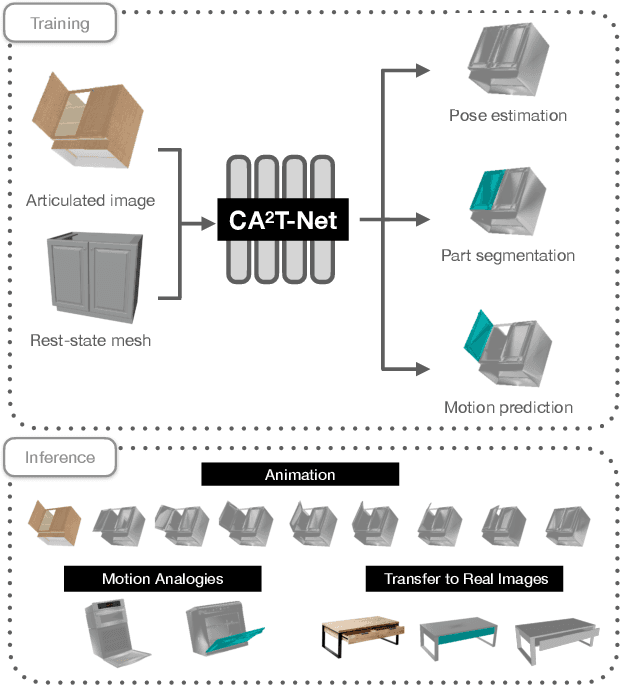
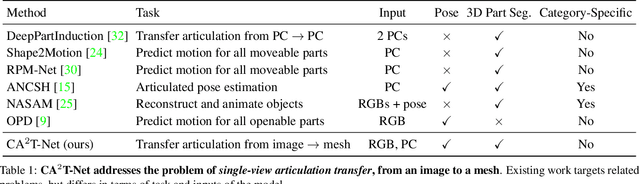
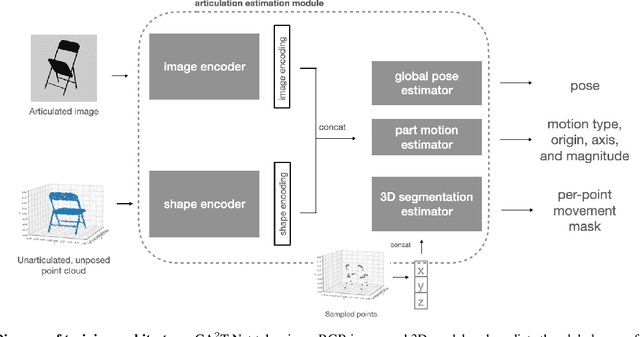
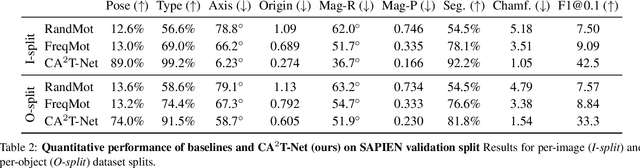
We present a neural network approach to transfer the motion from a single image of an articulated object to a rest-state (i.e., unarticulated) 3D model. Our network learns to predict the object's pose, part segmentation, and corresponding motion parameters to reproduce the articulation shown in the input image. The network is composed of three distinct branches that take a shared joint image-shape embedding and is trained end-to-end. Unlike previous methods, our approach is independent of the topology of the object and can work with objects from arbitrary categories. Our method, trained with only synthetic data, can be used to automatically animate a mesh, infer motion from real images, and transfer articulation to functionally similar but geometrically distinct 3D models at test time.
Towards Understanding How Machines Can Learn Causal Overhypotheses
Jun 16, 2022
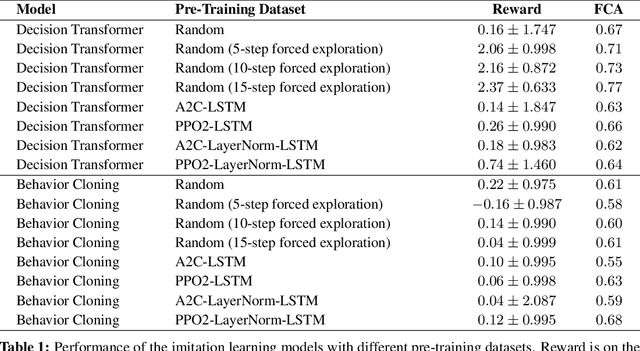

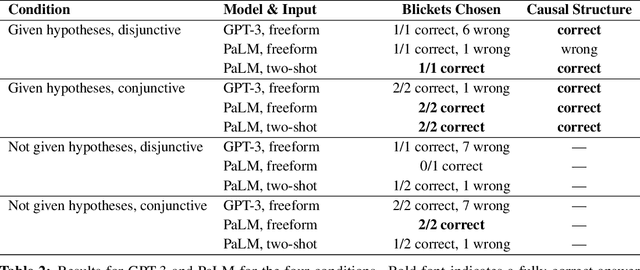
Recent work in machine learning and cognitive science has suggested that understanding causal information is essential to the development of intelligence. The extensive literature in cognitive science using the ``blicket detector'' environment shows that children are adept at many kinds of causal inference and learning. We propose to adapt that environment for machine learning agents. One of the key challenges for current machine learning algorithms is modeling and understanding causal overhypotheses: transferable abstract hypotheses about sets of causal relationships. In contrast, even young children spontaneously learn and use causal overhypotheses. In this work, we present a new benchmark -- a flexible environment which allows for the evaluation of existing techniques under variable causal overhypotheses -- and demonstrate that many existing state-of-the-art methods have trouble generalizing in this environment. The code and resources for this benchmark are available at https://github.com/CannyLab/casual_overhypotheses.
Learning Causal Overhypotheses through Exploration in Children and Computational Models
Feb 21, 2022

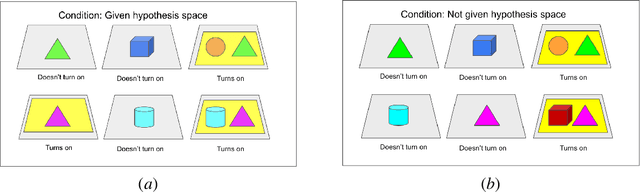
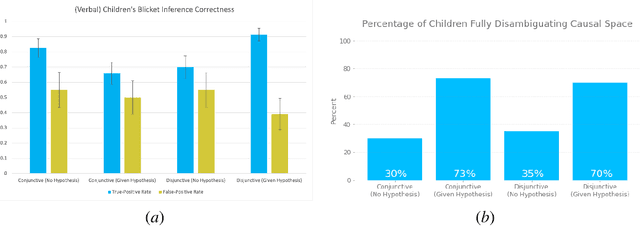
Despite recent progress in reinforcement learning (RL), RL algorithms for exploration still remain an active area of research. Existing methods often focus on state-based metrics, which do not consider the underlying causal structures of the environment, and while recent research has begun to explore RL environments for causal learning, these environments primarily leverage causal information through causal inference or induction rather than exploration. In contrast, human children - some of the most proficient explorers - have been shown to use causal information to great benefit. In this work, we introduce a novel RL environment designed with a controllable causal structure, which allows us to evaluate exploration strategies used by both agents and children in a unified environment. In addition, through experimentation on both computation models and children, we demonstrate that there are significant differences between information-gain optimal RL exploration in causal environments and the exploration of children in the same environments. We conclude with a discussion of how these findings may inspire new directions of research into efficient exploration and disambiguation of causal structures for RL algorithms.
GANmouflage: 3D Object Nondetection with Texture Fields
Jan 18, 2022



We propose a method that learns to camouflage 3D objects within scenes. Given an object's shape and a distribution of viewpoints from which it will be seen, we estimate a texture that will make it difficult to detect. Successfully solving this task requires a model that can accurately reproduce textures from the scene, while simultaneously dealing with the highly conflicting constraints imposed by each viewpoint. We address these challenges with a model based on texture fields and adversarial learning. Our model learns to camouflage a variety of object shapes from randomly sampled locations and viewpoints within the input scene, and is the first to address the problem of hiding complex object shapes. Using a human visual search study, we find that our estimated textures conceal objects significantly better than previous methods. Project site: https://rrrrrguo.github.io/ganmouflage/
ABO: Dataset and Benchmarks for Real-World 3D Object Understanding
Oct 12, 2021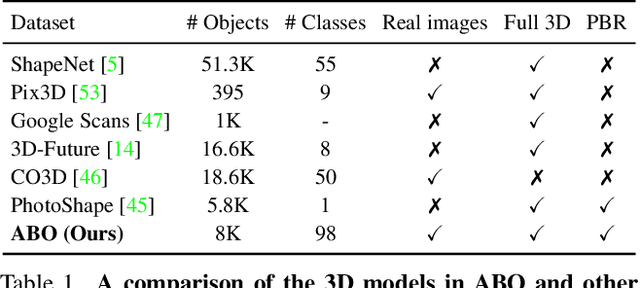
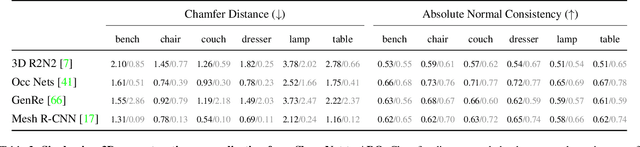
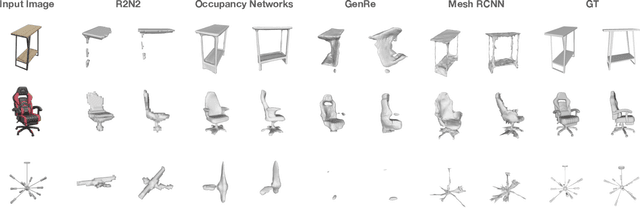
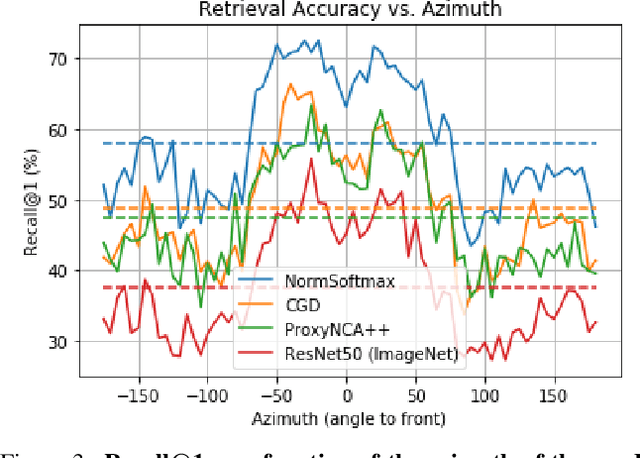
We introduce Amazon-Berkeley Objects (ABO), a new large-scale dataset of product images and 3D models corresponding to real household objects. We use this realistic, object-centric 3D dataset to measure the domain gap for single-view 3D reconstruction networks trained on synthetic objects. We also use multi-view images from ABO to measure the robustness of state-of-the-art metric learning approaches to different camera viewpoints. Finally, leveraging the physically-based rendering materials in ABO, we perform single- and multi-view material estimation for a variety of complex, real-world geometries. The full dataset is available for download at https://amazon-berkeley-objects.s3.amazonaws.com/index.html.
Exploring Exploration: Comparing Children with RL Agents in Unified Environments
May 06, 2020
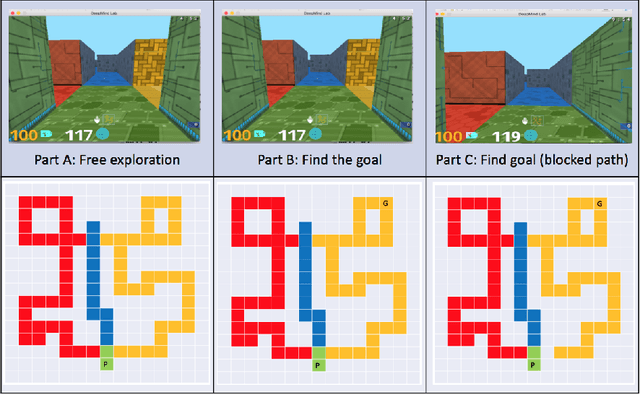
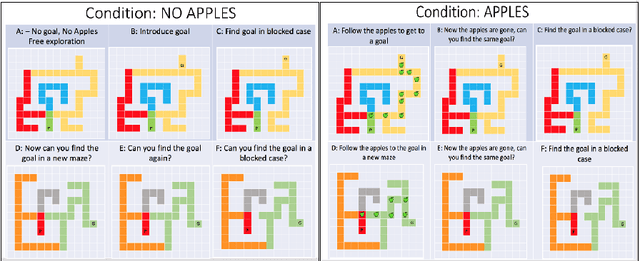
Research in developmental psychology consistently shows that children explore the world thoroughly and efficiently and that this exploration allows them to learn. In turn, this early learning supports more robust generalization and intelligent behavior later in life. While much work has gone into developing methods for exploration in machine learning, artificial agents have not yet reached the high standard set by their human counterparts. In this work we propose using DeepMind Lab (Beattie et al., 2016) as a platform to directly compare child and agent behaviors and to develop new exploration techniques. We outline two ongoing experiments to demonstrate the effectiveness of a direct comparison, and outline a number of open research questions that we believe can be tested using this methodology.
Accelerating Training of Deep Neural Networks with a Standardization Loss
Mar 03, 2019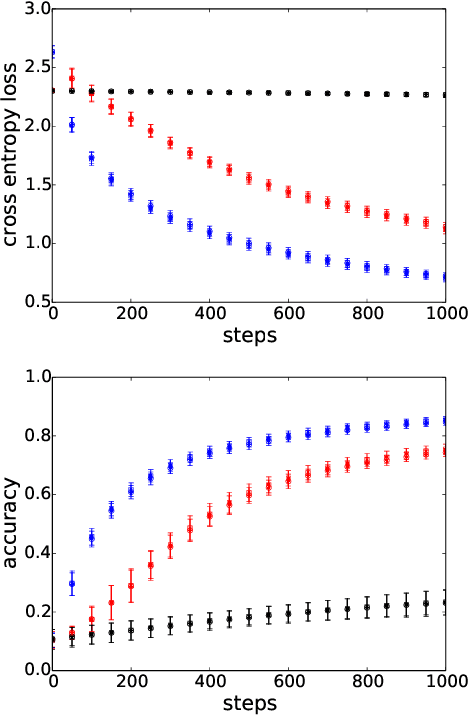
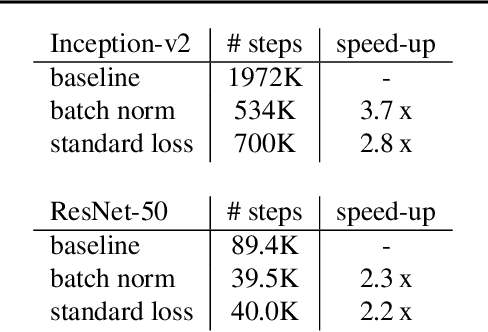
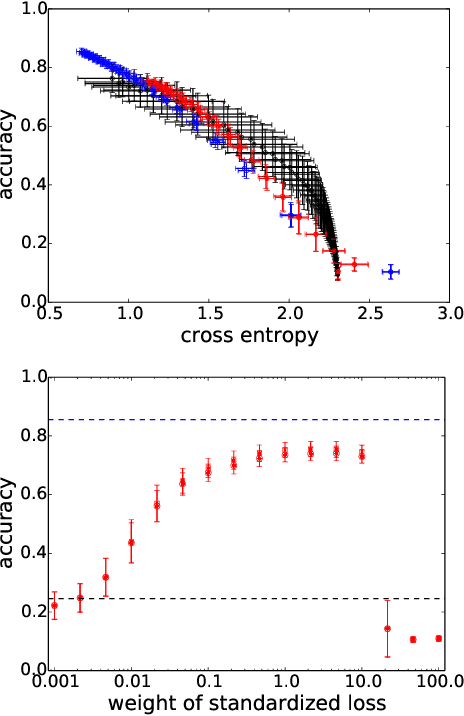
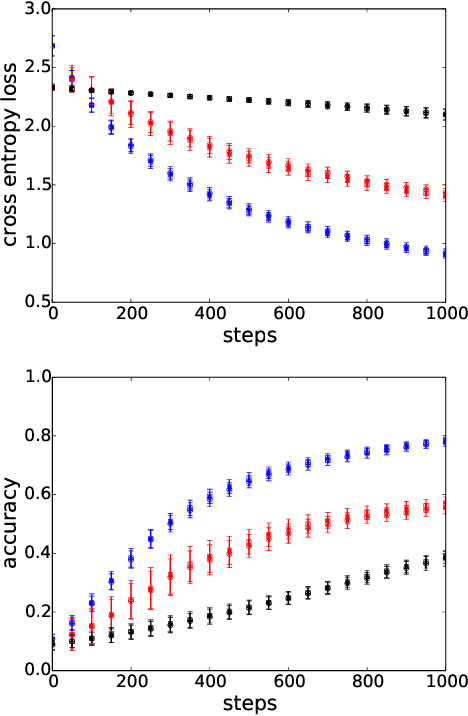
A significant advance in accelerating neural network training has been the development of normalization methods, permitting the training of deep models both faster and with better accuracy. These advances come with practical challenges: for instance, batch normalization ties the prediction of individual examples with other examples within a batch, resulting in a network that is heavily dependent on batch size. Layer normalization and group normalization are data-dependent and thus must be continually used, even at test-time. To address the issues that arise from using explicit normalization techniques, we propose to replace existing normalization methods with a simple, secondary objective loss that we term a standardization loss. This formulation is flexible and robust across different batch sizes and surprisingly, this secondary objective accelerates learning on the primary training objective. Because it is a training loss, it is simply removed at test-time, and no further effort is needed to maintain normalized activations. We find that a standardization loss accelerates training on both small- and large-scale image classification experiments, works with a variety of architectures, and is largely robust to training across different batch sizes.