 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Before You Act: Intention-Guided Reasoning for LLM-Based Location Prediction
Jun 06, 2026Predicting a user's next Point-of-Interest (POI) based on their historical check-in records is a fundamental task in location-based services. While recent methods incorporating large language models have shown strong reasoning capabilities and promising results, they typically formulate the prediction task as a one-step trajectory-to-location mapping problem, making predictions prone to shallow trajectory correlations and historical frequency bias. We argue that users rarely choose locations directly and instead, they usually first form a traveling intention and then accordingly select specific POIs. Motivated by this insight, we propose IntentPOI, a two-stage intention-guided reasoning framework. In the thinking stage, we infer users' intermediate intentions by incorporating historical mobility patterns, similar peer behaviors, and the temporal contexts. In the acting stage, we first construct a compact candidate pool, and then perform intention-guided reasoning to identify locations that best align with the inferred intention. By explicitly decoupling intention inference from location prediction, IntentPOI transforms the next POI prediction from direct trajectory matching into intention-guided reasoning. Extensive experiments on three real-world datasets demonstrate that IntentPOI consistently outperforms eleven state-of-the-art baselines.
ActivityEditor: Learning to Synthesize Physically Valid Human Mobility
Apr 07, 2026Human mobility modeling is indispensable for diverse urban applications. However, existing data-driven methods often suffer from data scarcity, limiting their applicability in regions where historical trajectories are unavailable or restricted. To bridge this gap, we propose \textbf{ActivityEditor}, a novel dual-LLM-agent framework designed for zero-shot cross-regional trajectory generation. Our framework decomposes the complex synthesis task into two collaborative stages. Specifically, an intention-based agent, which leverages demographic-driven priors to generate structured human intentions and coarse activity chains to ensure high-level socio-semantic coherence. These outputs are then refined by editor agent to obtain mobility trajectories through iteratively revisions that enforces human mobility law. This capability is acquired through reinforcement learning with multiple rewards grounded in real-world physical constraints, allowing the agent to internalize mobility regularities and ensure high-fidelity trajectory generation. Extensive experiments demonstrate that \textbf{ActivityEditor} achieves superior zero-shot performance when transferred across diverse urban contexts. It maintains high statistical fidelity and physical validity, providing a robust and highly generalizable solution for mobility simulation in data-scarce scenarios. Our code is available at: https://anonymous.4open.science/r/ActivityEditor-066B.
ICAR: Image-based Complementary Auto Reasoning
Aug 17, 2023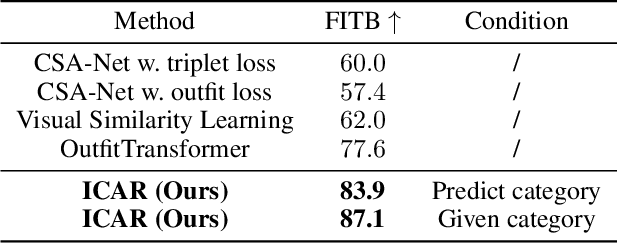
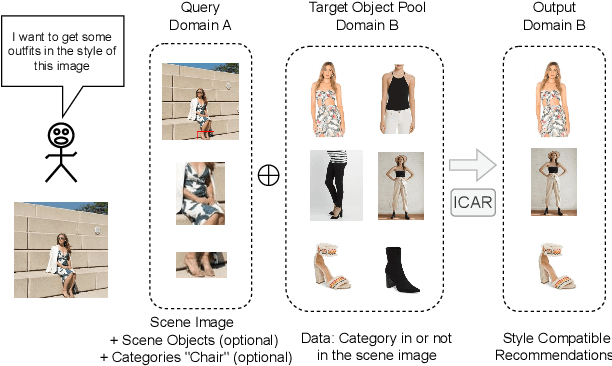
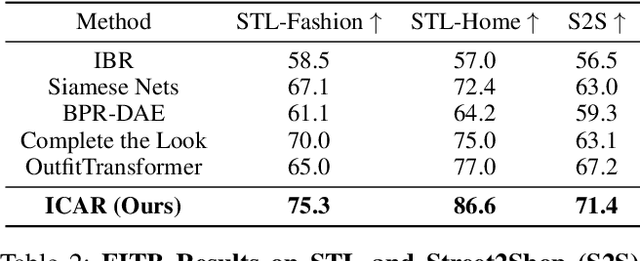
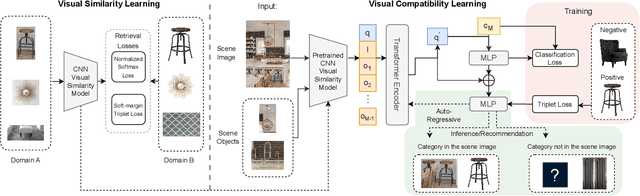
Scene-aware Complementary Item Retrieval (CIR) is a challenging task which requires to generate a set of compatible items across domains. Due to the subjectivity, it is difficult to set up a rigorous standard for both data collection and learning objectives. To address this challenging task, we propose a visual compatibility concept, composed of similarity (resembling in color, geometry, texture, and etc.) and complementarity (different items like table vs chair completing a group). Based on this notion, we propose a compatibility learning framework, a category-aware Flexible Bidirectional Transformer (FBT), for visual "scene-based set compatibility reasoning" with the cross-domain visual similarity input and auto-regressive complementary item generation. We introduce a "Flexible Bidirectional Transformer (FBT)" consisting of an encoder with flexible masking, a category prediction arm, and an auto-regressive visual embedding prediction arm. And the inputs for FBT are cross-domain visual similarity invariant embeddings, making this framework quite generalizable. Furthermore, our proposed FBT model learns the inter-object compatibility from a large set of scene images in a self-supervised way. Compared with the SOTA methods, this approach achieves up to 5.3% and 9.6% in FITB score and 22.3% and 31.8% SFID improvement on fashion and furniture, respectively.
CA$^2$T-Net: Category-Agnostic 3D Articulation Transfer from Single Image
Jan 05, 2023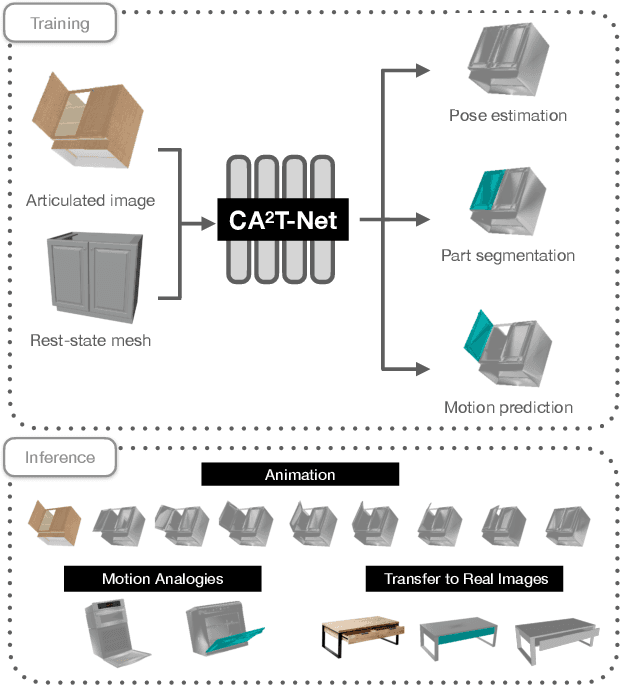
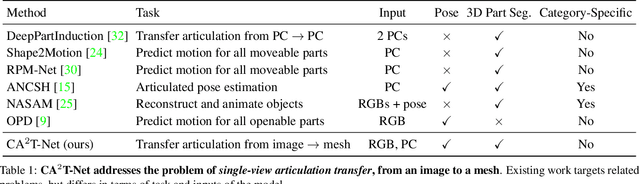
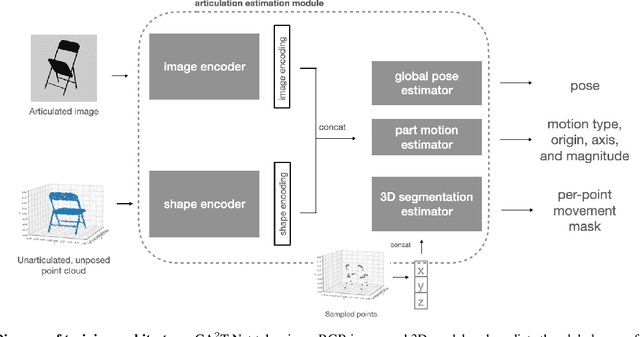
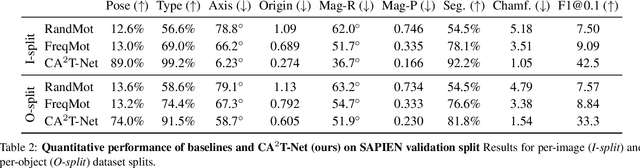
We present a neural network approach to transfer the motion from a single image of an articulated object to a rest-state (i.e., unarticulated) 3D model. Our network learns to predict the object's pose, part segmentation, and corresponding motion parameters to reproduce the articulation shown in the input image. The network is composed of three distinct branches that take a shared joint image-shape embedding and is trained end-to-end. Unlike previous methods, our approach is independent of the topology of the object and can work with objects from arbitrary categories. Our method, trained with only synthetic data, can be used to automatically animate a mesh, infer motion from real images, and transfer articulation to functionally similar but geometrically distinct 3D models at test time.