 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLAP: Efficient Video-Language Alignment via Frame Prompting and Distilling for Video Question Answering
Dec 13, 2023In this work, we propose an efficient Video-Language Alignment via Frame-Prompting and Distilling (VLAP) network. Our VLAP model addresses both efficient frame sampling and effective cross-modal alignment in a unified way. In our VLAP network, we design a new learnable question-aware Frame-Prompter together with a new cross-modal distillation (QFormer-Distiller) module. Pre-trained large image-language models have shown promising results on problems such as visual question answering. However, how to efficiently and effectively sample image frames when adapting pre-trained large image-language model to video-language alignment is still the major challenge. Compared with prior work, our VLAP model demonstrates the capability of selecting key frames with critical contents, thus improving the video-language alignment accuracy while reducing the inference latency (+3.3% on NExT-QA Temporal with 3.0X speed up). Overall, our VLAP network outperforms (e.g. +4.6% on STAR Interaction and +2.2% on STAR average with 3.0X speed up, ours 2-frames out-perform SeViLA 4-frames on VLEP with 4.2X speed up) the state-of-the-art methods on the video question-answering benchmarks.
MeSa: Masked, Geometric, and Supervised Pre-training for Monocular Depth Estimation
Oct 06, 2023Pre-training has been an important ingredient in developing strong monocular depth estimation models in recent years. For instance, self-supervised learning (SSL) is particularly effective by alleviating the need for large datasets with dense ground-truth depth maps. However, despite these improvements, our study reveals that the later layers of the SOTA SSL method are actually suboptimal. By examining the layer-wise representations, we demonstrate significant changes in these later layers during fine-tuning, indicating the ineffectiveness of their pre-trained features for depth estimation. To address these limitations, we propose MeSa, a comprehensive framework that leverages the complementary strengths of masked, geometric, and supervised pre-training. Hence, MeSa benefits from not only general-purpose representations learnt via masked pre training but also specialized depth-specific features acquired via geometric and supervised pre-training. Our CKA layer-wise analysis confirms that our pre-training strategy indeed produces improved representations for the later layers, overcoming the drawbacks of the SOTA SSL method. Furthermore, via experiments on the NYUv2 and IBims-1 datasets, we demonstrate that these enhanced representations translate to performance improvements in both the in-distribution and out-of-distribution settings. We also investigate the influence of the pre-training dataset and demonstrate the efficacy of pre-training on LSUN, which yields significantly better pre-trained representations. Overall, our approach surpasses the masked pre-training SSL method by a substantial margin of 17.1% on the RMSE. Moreover, even without utilizing any recently proposed techniques, MeSa also outperforms the most recent methods and establishes a new state-of-the-art for monocular depth estimation on the challenging NYUv2 dataset.
ICAR: Image-based Complementary Auto Reasoning
Aug 17, 2023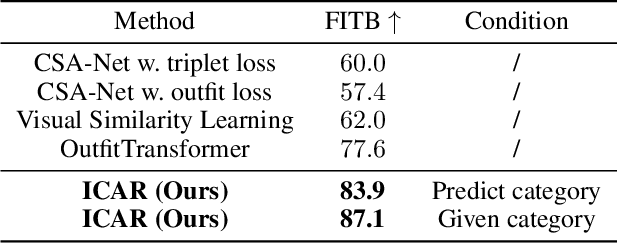
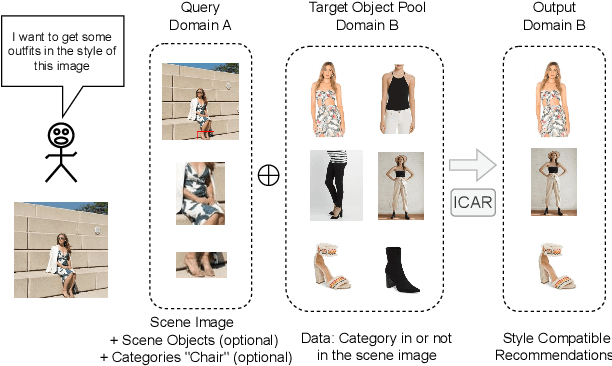
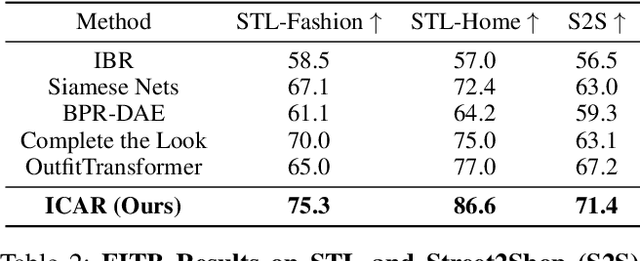
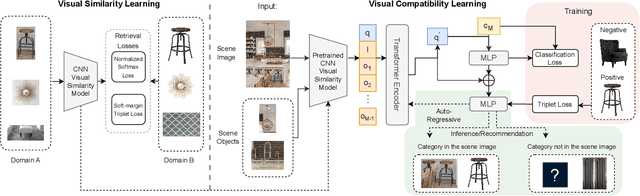
Scene-aware Complementary Item Retrieval (CIR) is a challenging task which requires to generate a set of compatible items across domains. Due to the subjectivity, it is difficult to set up a rigorous standard for both data collection and learning objectives. To address this challenging task, we propose a visual compatibility concept, composed of similarity (resembling in color, geometry, texture, and etc.) and complementarity (different items like table vs chair completing a group). Based on this notion, we propose a compatibility learning framework, a category-aware Flexible Bidirectional Transformer (FBT), for visual "scene-based set compatibility reasoning" with the cross-domain visual similarity input and auto-regressive complementary item generation. We introduce a "Flexible Bidirectional Transformer (FBT)" consisting of an encoder with flexible masking, a category prediction arm, and an auto-regressive visual embedding prediction arm. And the inputs for FBT are cross-domain visual similarity invariant embeddings, making this framework quite generalizable. Furthermore, our proposed FBT model learns the inter-object compatibility from a large set of scene images in a self-supervised way. Compared with the SOTA methods, this approach achieves up to 5.3% and 9.6% in FITB score and 22.3% and 31.8% SFID improvement on fashion and furniture, respectively.
Unsupervised Scene Sketch to Photo Synthesis
Sep 06, 2022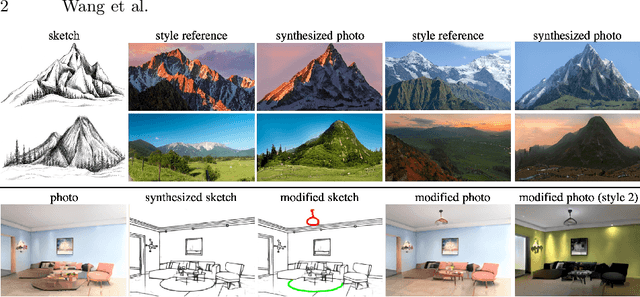
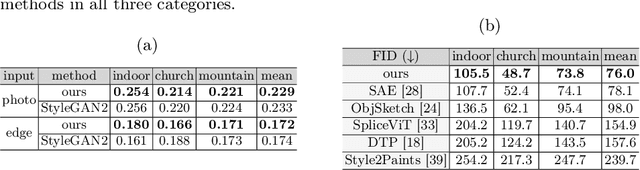
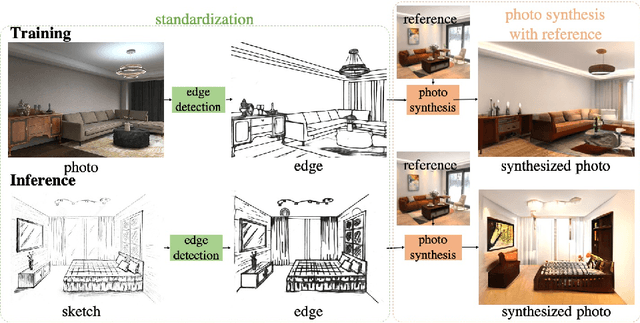

Sketches make an intuitive and powerful visual expression as they are fast executed freehand drawings. We present a method for synthesizing realistic photos from scene sketches. Without the need for sketch and photo pairs, our framework directly learns from readily available large-scale photo datasets in an unsupervised manner. To this end, we introduce a standardization module that provides pseudo sketch-photo pairs during training by converting photos and sketches to a standardized domain, i.e. the edge map. The reduced domain gap between sketch and photo also allows us to disentangle them into two components: holistic scene structures and low-level visual styles such as color and texture. Taking this advantage, we synthesize a photo-realistic image by combining the structure of a sketch and the visual style of a reference photo. Extensive experimental results on perceptual similarity metrics and human perceptual studies show the proposed method could generate realistic photos with high fidelity from scene sketches and outperform state-of-the-art photo synthesis baselines. We also demonstrate that our framework facilitates a controllable manipulation of photo synthesis by editing strokes of corresponding sketches, delivering more fine-grained details than previous approaches that rely on region-level editing.