 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICAR: Image-based Complementary Auto Reasoning
Paper and Code
Aug 17, 2023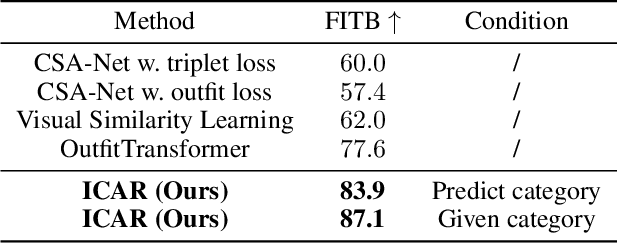
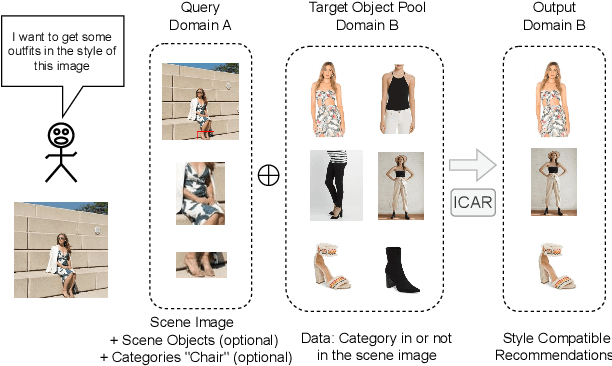
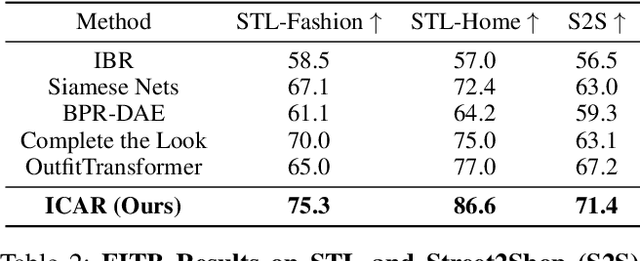
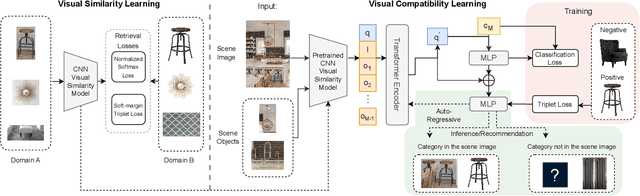
Scene-aware Complementary Item Retrieval (CIR) is a challenging task which requires to generate a set of compatible items across domains. Due to the subjectivity, it is difficult to set up a rigorous standard for both data collection and learning objectives. To address this challenging task, we propose a visual compatibility concept, composed of similarity (resembling in color, geometry, texture, and etc.) and complementarity (different items like table vs chair completing a group). Based on this notion, we propose a compatibility learning framework, a category-aware Flexible Bidirectional Transformer (FBT), for visual "scene-based set compatibility reasoning" with the cross-domain visual similarity input and auto-regressive complementary item generation. We introduce a "Flexible Bidirectional Transformer (FBT)" consisting of an encoder with flexible masking, a category prediction arm, and an auto-regressive visual embedding prediction arm. And the inputs for FBT are cross-domain visual similarity invariant embeddings, making this framework quite generalizable. Furthermore, our proposed FBT model learns the inter-object compatibility from a large set of scene images in a self-supervised way. Compared with the SOTA methods, this approach achieves up to 5.3% and 9.6% in FITB score and 22.3% and 31.8% SFID improvement on fashion and furniture, respectively.