 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Test-Time Training: Learning to Reason via Hardware-Efficient Optimal Control
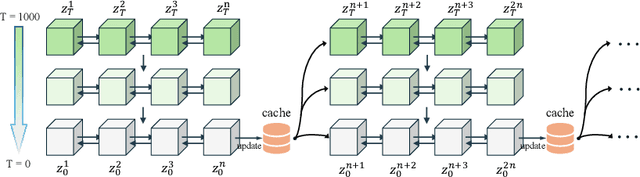
Mar 10, 2026Associative memory has long underpinned the design of sequential models. Beyond recall, humans reason by projecting future states and selecting goal-directed actions, a capability that modern language models increasingly require but do not natively encode. While prior work uses reinforcement learning or test-time training, planning remains external to the model architecture. We formulate reasoning as optimal control and introduce the Test-Time Control (TTC) layer, which performs finite-horizon LQR planning over latent states at inference time, represents a value function within neural architectures, and leverages it as the nested objective to enable planning before prediction. To ensure scalability, we derive a hardware-efficient LQR solver based on a symplectic formulation and implement it as a fused CUDA kernel, enabling parallel execution with minimal overhead. Integrated as an adapter into pretrained LLMs, TTC layers improve mathematical reasoning performance by up to +27.8% on MATH-500 and 2-3x Pass@8 improvements on AMC and AIME, demonstrating that embedding optimal control as an architectural component provides an effective and scalable mechanism for reasoning beyond test-time training.
CoCo-Fed: A Unified Framework for Memory- and Communication-Efficient Federated Learning at the Wireless Edge
Jan 02, 2026The deployment of large-scale neural networks within the Open Radio Access Network (O-RAN) architecture is pivotal for enabling native edge intelligence. However, this paradigm faces two critical bottlenecks: the prohibitive memory footprint required for local training on resource-constrained gNBs, and the saturation of bandwidth-limited backhaul links during the global aggregation of high-dimensional model updates. To address these challenges, we propose CoCo-Fed, a novel Compression and Combination-based Federated learning framework that unifies local memory efficiency and global communication reduction. Locally, CoCo-Fed breaks the memory wall by performing a double-dimension down-projection of gradients, adapting the optimizer to operate on low-rank structures without introducing additional inference parameters/latency. Globally, we introduce a transmission protocol based on orthogonal subspace superposition, where layer-wise updates are projected and superimposed into a single consolidated matrix per gNB, drastically reducing the backhaul traffic. Beyond empirical designs, we establish a rigorous theoretical foundation, proving the convergence of CoCo-Fed even under unsupervised learning conditions suitable for wireless sensing tasks. Extensive simulations on an angle-of-arrival estimation task demonstrate that CoCo-Fed significantly outperforms state-of-the-art baselines in both memory and communication efficiency while maintaining robust convergence under non-IID settings.
LiftVSR: Lifting Image Diffusion to Video Super-Resolution via Hybrid Temporal Modeling with Only 4$\times$RTX 4090s
Jun 10, 2025


Diffusion models have significantly advanced video super-resolution (VSR) by enhancing perceptual quality, largely through elaborately designed temporal modeling to ensure inter-frame consistency. However, existing methods usually suffer from limited temporal coherence and prohibitively high computational costs (e.g., typically requiring over 8 NVIDIA A100-80G GPUs), especially for long videos. In this work, we propose LiftVSR, an efficient VSR framework that leverages and elevates the image-wise diffusion prior from PixArt-$\alpha$, achieving state-of-the-art results using only 4$\times$RTX 4090 GPUs. To balance long-term consistency and efficiency, we introduce a hybrid temporal modeling mechanism that decomposes temporal learning into two complementary components: (i) Dynamic Temporal Attention (DTA) for fine-grained temporal modeling within short frame segment ($\textit{i.e.}$, low complexity), and (ii) Attention Memory Cache (AMC) for long-term temporal modeling across segments ($\textit{i.e.}$, consistency). Specifically, DTA identifies multiple token flows across frames within multi-head query and key tokens to warp inter-frame contexts in the value tokens. AMC adaptively aggregates historical segment information via a cache unit, ensuring long-term coherence with minimal overhead. To further stabilize the cache interaction during inference, we introduce an asymmetric sampling strategy that mitigates feature mismatches arising from different diffusion sampling steps. Extensive experiments on several typical VSR benchmarks have demonstrated that LiftVSR achieves impressive performance with significantly lower computational costs.
NTIRE 2025 Challenge on Short-form UGC Video Quality Assessment and Enhancement: KwaiSR Dataset and Study
Apr 21, 2025In this work, we build the first benchmark dataset for short-form UGC Image Super-resolution in the wild, termed KwaiSR, intending to advance the research on developing image super-resolution algorithms for short-form UGC platforms. This dataset is collected from the Kwai Platform, which is composed of two parts, i.e., synthetic and wild parts. Among them, the synthetic dataset, including 1,900 image pairs, is produced by simulating the degradation following the distribution of real-world low-quality short-form UGC images, aiming to provide the ground truth for training and objective comparison in the validation/testing. The wild dataset contains low-quality images collected directly from the Kwai Platform, which are filtered using the quality assessment method KVQ from the Kwai Platform. As a result, the KwaiSR dataset contains 1800 synthetic image pairs and 1900 wild images, which are divided into training, validation, and testing parts with a ratio of 8:1:1. Based on the KwaiSR dataset, we organize the NTIRE 2025 challenge on a second short-form UGC Video quality assessment and enhancement, which attracts lots of researchers to develop the algorithm for it. The results of this competition have revealed that our KwaiSR dataset is pretty challenging for existing Image SR methods, which is expected to lead to a new direction in the image super-resolution field. The dataset can be found from https://lixinustc.github.io/NTIRE2025-KVQE-KwaSR-KVQ.github.io/.
Using Attention Sinks to Identify and Evaluate Dormant Heads in Pretrained LLMs
Apr 04, 2025Multi-head attention is foundational to large language models (LLMs), enabling different heads to have diverse focus on relevant input tokens. However, learned behaviors like attention sinks, where the first token receives most attention despite limited semantic importance, challenge our understanding of multi-head attention. To analyze this phenomenon, we propose a new definition for attention heads dominated by attention sinks, known as dormant attention heads. We compare our definition to prior work in a model intervention study where we test whether dormant heads matter for inference by zeroing out the output of dormant attention heads. Using six pretrained models and five benchmark datasets, we find our definition to be more model and dataset-agnostic. Using our definition on most models, more than 4% of a model's attention heads can be zeroed while maintaining average accuracy, and zeroing more than 14% of a model's attention heads can keep accuracy to within 1% of the pretrained model's average accuracy. Further analysis reveals that dormant heads emerge early in pretraining and can transition between dormant and active states during pretraining. Additionally, we provide evidence that they depend on characteristics of the input text.
Learning Phase Distortion with Selective State Space Models for Video Turbulence Mitigation
Apr 03, 2025Atmospheric turbulence is a major source of image degradation in long-range imaging systems. Although numerous deep learning-based turbulence mitigation (TM) methods have been proposed, many are slow, memory-hungry, and do not generalize well. In the spatial domain, methods based on convolutional operators have a limited receptive field, so they cannot handle a large spatial dependency required by turbulence. In the temporal domain, methods relying on self-attention can, in theory, leverage the lucky effects of turbulence, but their quadratic complexity makes it difficult to scale to many frames. Traditional recurrent aggregation methods face parallelization challenges. In this paper, we present a new TM method based on two concepts: (1) A turbulence mitigation network based on the Selective State Space Model (MambaTM). MambaTM provides a global receptive field in each layer across spatial and temporal dimensions while maintaining linear computational complexity. (2) Learned Latent Phase Distortion (LPD). LPD guides the state space model. Unlike classical Zernike-based representations of phase distortion, the new LPD map uniquely captures the actual effects of turbulence, significantly improving the model's capability to estimate degradation by reducing the ill-posedness. Our proposed method exceeds current state-of-the-art networks on various synthetic and real-world TM benchmarks with significantly faster inference speed. The code is available at http://github.com/xg416/MambaTM.
Federated Learning for Diffusion Models
Mar 09, 2025Diffusion models are powerful generative models that can produce highly realistic samples for various tasks. Typically, these models are constructed using centralized, independently and identically distributed (IID) training data. However, in practical scenarios, data is often distributed across multiple clients and frequently manifests non-IID characteristics. Federated Learning (FL) can leverage this distributed data to train diffusion models, but the performance of existing FL methods is unsatisfactory in non-IID scenarios. To address this, we propose FedDDPM-Federated Learning with Denoising Diffusion Probabilistic Models, which leverages the data generative capability of diffusion models to facilitate model training. In particular, the server uses well-trained local diffusion models uploaded by each client before FL training to generate auxiliary data that can approximately represent the global data distribution. Following each round of model aggregation, the server further optimizes the global model using the auxiliary dataset to alleviate the impact of heterogeneous data on model performance. We provide a rigorous convergence analysis of FedDDPM and propose an enhanced algorithm, FedDDPM+, to reduce training overheads. FedDDPM+ detects instances of slow model learning and performs a one-shot correction using the auxiliary dataset. Experimental results validate that our proposed algorithms outperform the state-of-the-art FL algorithms on the MNIST, CIFAR10 and CIFAR100 datasets.
Large-Scale AI in Telecom: Charting the Roadmap for Innovation, Scalability, and Enhanced Digital Experiences
Mar 06, 2025



This white paper discusses the role of large-scale AI in the telecommunications industry, with a specific focus on the potential of generative AI to revolutionize network functions and user experiences, especially in the context of 6G systems. It highlights the development and deployment of Large Telecom Models (LTMs), which are tailored AI models designed to address the complex challenges faced by modern telecom networks. The paper covers a wide range of topics, from the architecture and deployment strategies of LTMs to their applications in network management, resource allocation, and optimization. It also explores the regulatory, ethical, and standardization considerations for LTMs, offering insights into their future integration into telecom infrastructure. The goal is to provide a comprehensive roadmap for the adoption of LTMs to enhance scalability, performance, and user-centric innovation in telecom networks.
Take What You Need: Flexible Multi-Task Semantic Communications with Channel Adaptation
Feb 12, 2025The growing demand for efficient semantic communication systems capable of managing diverse tasks and adapting to fluctuating channel conditions has driven the development of robust, resource-efficient frameworks. This article introduces a novel channel-adaptive and multi-task-aware semantic communication framework based on a masked auto-encoder architecture. Our framework optimizes the transmission of meaningful information by incorporating a multi-task-aware scoring mechanism that identifies and prioritizes semantically significant data across multiple concurrent tasks. A channel-aware extractor is employed to dynamically select relevant information in response to real-time channel conditions. By jointly optimizing semantic relevance and transmission efficiency, the framework ensures minimal performance degradation under resource constraints. Experimental results demonstrate the superior performance of our framework compared to conventional methods in tasks such as image reconstruction and object detection. These results underscore the framework's adaptability to heterogeneous channel environments and its scalability for multi-task applications, positioning it as a promising solution for next-generation semantic communication networks.
DAVE: Diverse Atomic Visual Elements Dataset with High Representation of Vulnerable Road Users in Complex and Unpredictable Environments
Dec 28, 2024



Most existing traffic video datasets including Waymo are structured, focusing predominantly on Western traffic, which hinders global applicability. Specifically, most Asian scenarios are far more complex, involving numerous objects with distinct motions and behaviors. Addressing this gap, we present a new dataset, DAVE, designed for evaluating perception methods with high representation of Vulnerable Road Users (VRUs: e.g. pedestrians, animals, motorbikes, and bicycles) in complex and unpredictable environments. DAVE is a manually annotated dataset encompassing 16 diverse actor categories (spanning animals, humans, vehicles, etc.) and 16 action types (complex and rare cases like cut-ins, zigzag movement, U-turn, etc.), which require high reasoning ability. DAVE densely annotates over 13 million bounding boxes (bboxes) actors with identification, and more than 1.6 million boxes are annotated with both actor identification and action/behavior details. The videos within DAVE are collected based on a broad spectrum of factors, such as weather conditions, the time of day, road scenarios, and traffic density. DAVE can benchmark video tasks like Tracking, Detection, Spatiotemporal Action Localization, Language-Visual Moment retrieval, and Multi-label Video Action Recognition. Given the critical importance of accurately identifying VRUs to prevent accidents and ensure road safety, in DAVE, vulnerable road users constitute 41.13% of instances, compared to 23.71% in Waymo. DAVE provides an invaluable resource for the development of more sensitive and accurate visual perception algorithms in the complex real world. Our experiments show that existing methods suffer degradation in performance when evaluated on DAVE, highlighting its benefit for future video recognition research.