 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI-Scene: 3D Instance Models are Implicit Generalizable Spatial Learners
Dec 15, 2025



Generalization remains the central challenge for interactive 3D scene generation. Existing learning-based approaches ground spatial understanding in limited scene dataset, restricting generalization to new layouts. We instead reprogram a pre-trained 3D instance generator to act as a scene level learner, replacing dataset-bounded supervision with model-centric spatial supervision. This reprogramming unlocks the generator transferable spatial knowledge, enabling generalization to unseen layouts and novel object compositions. Remarkably, spatial reasoning still emerges even when the training scenes are randomly composed objects. This demonstrates that the generator's transferable scene prior provides a rich learning signal for inferring proximity, support, and symmetry from purely geometric cues. Replacing widely used canonical space, we instantiate this insight with a view-centric formulation of the scene space, yielding a fully feed-forward, generalizable scene generator that learns spatial relations directly from the instance model. Quantitative and qualitative results show that a 3D instance generator is an implicit spatial learner and reasoner, pointing toward foundation models for interactive 3D scene understanding and generation. Project page: https://luling06.github.io/I-Scene-project/
Scenethesis: A Language and Vision Agentic Framework for 3D Scene Generation
May 05, 2025Synthesizing interactive 3D scenes from text is essential for gaming, virtual reality, and embodied AI. However, existing methods face several challenges. Learning-based approaches depend on small-scale indoor datasets, limiting the scene diversity and layout complexity. While large language models (LLMs) can leverage diverse text-domain knowledge, they struggle with spatial realism, often producing unnatural object placements that fail to respect common sense. Our key insight is that vision perception can bridge this gap by providing realistic spatial guidance that LLMs lack. To this end, we introduce Scenethesis, a training-free agentic framework that integrates LLM-based scene planning with vision-guided layout refinement. Given a text prompt, Scenethesis first employs an LLM to draft a coarse layout. A vision module then refines it by generating an image guidance and extracting scene structure to capture inter-object relations. Next, an optimization module iteratively enforces accurate pose alignment and physical plausibility, preventing artifacts like object penetration and instability. Finally, a judge module verifies spatial coherence. Comprehensive experiments show that Scenethesis generates diverse, realistic, and physically plausible 3D interactive scenes, making it valuable for virtual content creation, simulation environments, and embodied AI research.
Generative Photography: Scene-Consistent Camera Control for Realistic Text-to-Image Synthesis
Dec 03, 2024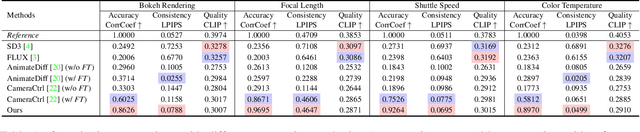



Image generation today can produce somewhat realistic images from text prompts. However, if one asks the generator to synthesize a particular camera setting such as creating different fields of view using a 24mm lens versus a 70mm lens, the generator will not be able to interpret and generate scene-consistent images. This limitation not only hinders the adoption of generative tools in photography applications but also exemplifies a broader issue of bridging the gap between the data-driven models and the physical world. In this paper, we introduce the concept of Generative Photography, a framework designed to control camera intrinsic settings during content generation. The core innovation of this work are the concepts of Dimensionality Lifting and Contrastive Camera Learning, which achieve continuous and consistent transitions for different camera settings. Experimental results show that our method produces significantly more scene-consistent photorealistic images than state-of-the-art models such as Stable Diffusion 3 and FLUX.
Floating No More: Object-Ground Reconstruction from a Single Image
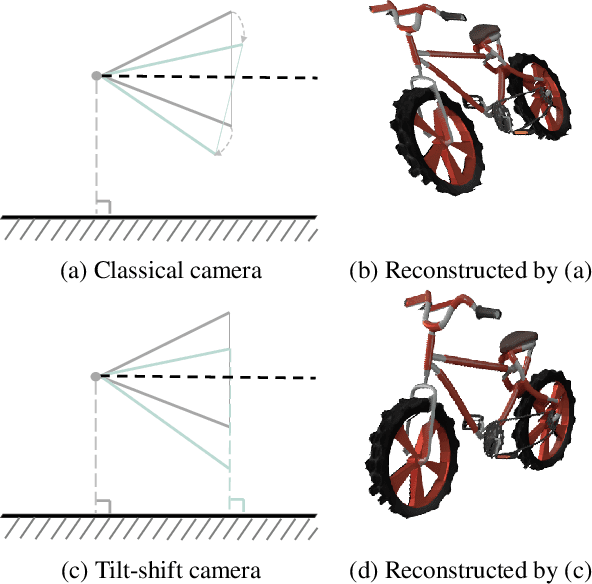
Jul 26, 2024Recent advancements in 3D object reconstruction from single images have primarily focused on improving the accuracy of object shapes. Yet, these techniques often fail to accurately capture the inter-relation between the object, ground, and camera. As a result, the reconstructed objects often appear floating or tilted when placed on flat surfaces. This limitation significantly affects 3D-aware image editing applications like shadow rendering and object pose manipulation. To address this issue, we introduce ORG (Object Reconstruction with Ground), a novel task aimed at reconstructing 3D object geometry in conjunction with the ground surface. Our method uses two compact pixel-level representations to depict the relationship between camera, object, and ground. Experiments show that the proposed ORG model can effectively reconstruct object-ground geometry on unseen data, significantly enhancing the quality of shadow generation and pose manipulation compared to conventional single-image 3D reconstruction techniques.
DL3DV-10K: A Large-Scale Scene Dataset for Deep Learning-based 3D Vision
Dec 29, 2023



We have witnessed significant progress in deep learning-based 3D vision, ranging from neural radiance field (NeRF) based 3D representation learning to applications in novel view synthesis (NVS). However, existing scene-level datasets for deep learning-based 3D vision, limited to either synthetic environments or a narrow selection of real-world scenes, are quite insufficient. This insufficiency not only hinders a comprehensive benchmark of existing methods but also caps what could be explored in deep learning-based 3D analysis. To address this critical gap, we present DL3DV-10K, a large-scale scene dataset, featuring 51.2 million frames from 10,510 videos captured from 65 types of point-of-interest (POI) locations, covering both bounded and unbounded scenes, with different levels of reflection, transparency, and lighting. We conducted a comprehensive benchmark of recent NVS methods on DL3DV-10K, which revealed valuable insights for future research in NVS. In addition, we have obtained encouraging results in a pilot study to learn generalizable NeRF from DL3DV-10K, which manifests the necessity of a large-scale scene-level dataset to forge a path toward a foundation model for learning 3D representation. Our DL3DV-10K dataset, benchmark results, and models will be publicly accessible at https://dl3dv-10k.github.io/DL3DV-10K/.
PixHt-Lab: Pixel Height Based Light Effect Generation for Image Compositing
Feb 28, 2023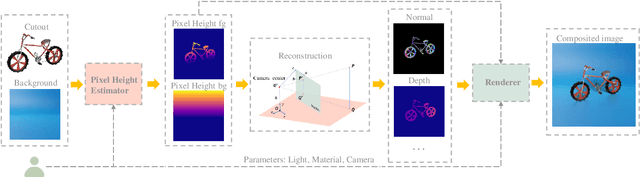

Lighting effects such as shadows or reflections are key in making synthetic images realistic and visually appealing. To generate such effects, traditional computer graphics uses a physically-based renderer along with 3D geometry. To compensate for the lack of geometry in 2D Image compositing, recent deep learning-based approaches introduced a pixel height representation to generate soft shadows and reflections. However, the lack of geometry limits the quality of the generated soft shadows and constrain reflections to pure specular ones. We introduce PixHt-Lab, a system leveraging an explicit mapping from pixel height representation to 3D space. Using this mapping, PixHt-Lab reconstructs both the cutout and background geometry and renders realistic, diverse, lighting effects for image compositing. Given a surface with physically-based materials, we can render reflections with varying glossiness. To generate more realistic soft shadows, we further propose to use 3D-aware buffer channels to guide a neural renderer. Both quantitative and qualitative evaluations demonstrate that PixHt-Lab significantly improves soft shadow generation.
Controllable Shadow Generation Using Pixel Height Maps
Jul 15, 2022

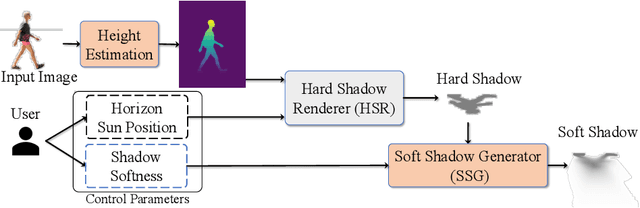
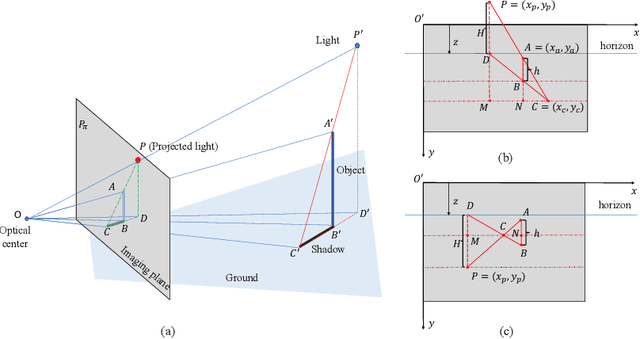
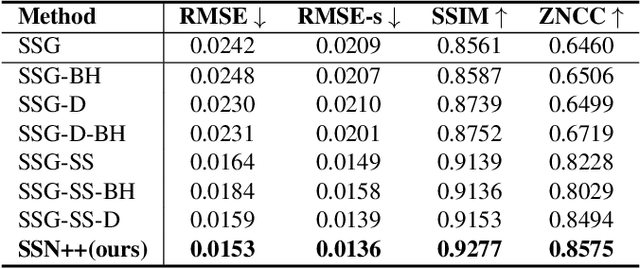
Shadows are essential for realistic image compositing. Physics-based shadow rendering methods require 3D geometries, which are not always available. Deep learning-based shadow synthesis methods learn a mapping from the light information to an object's shadow without explicitly modeling the shadow geometry. Still, they lack control and are prone to visual artifacts. We introduce pixel heigh, a novel geometry representation that encodes the correlations between objects, ground, and camera pose. The pixel height can be calculated from 3D geometries, manually annotated on 2D images, and can also be predicted from a single-view RGB image by a supervised approach. It can be used to calculate hard shadows in a 2D image based on the projective geometry, providing precise control of the shadows' direction and shape. Furthermore, we propose a data-driven soft shadow generator to apply softness to a hard shadow based on a softness input parameter. Qualitative and quantitative evaluations demonstrate that the proposed pixel height significantly improves the quality of the shadow generation while allowing for controllability.
SSN: Soft Shadow Network for Image Compositing
Jul 16, 2020

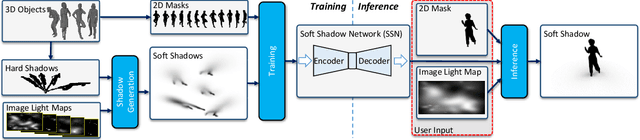

In image compositing tasks, objects from different sources are put together to form a new image. Artists often increase realism by adding object shadows to match the scene geometry and lighting. However, creating realistic soft shadows requires skill and is time-consuming. We introduce a Soft Shadow Network to generate convincing soft shadows for 2D object cutouts automatically. SSN takes an object cutout mask as input and thus is agnostic to image types such as painting and vector art. Although inferring the 3D shape of an object from its silhouette can be ambiguous, it is easy for humans to get the 3D geometry from a 2D projection when it is in an iconic view. We follow this intuition and train the SSN to render soft shadows for objects' iconic views. To train our model, we design an efficient pipeline to produce diverse soft shadow training data using 3D object models. Our pipeline first computes a set of soft shadow bases by sampling hard shadows. During training, environment lighting maps that cover a wide spectrum of possible configurations are used to calculate the soft shadow ground truth using the shadow bases. This enables our model to see a complex lighting pattern and to learn the interaction between the lights and 3D geometries. In addition, we propose an inverse shadow map representation, which makes the training focused on the shadow area and leads to much faster convergence and better performance. We show that our model produces realistic soft shadow details for objects of different shapes. A user study shows that SSN generated shadows are often indistinguishable from shadows calculated by physics-based rendering. Our SSN can produce a shadow in real-time and it allows real-time interactive shadow manipulation. We develop a simple user interface and a second user study shows that amateur users can easily use our tool to generate soft shadows matching a reference shadow.