 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViPS: Video-informed Pose Spaces for Auto-Rigged Meshes
Apr 19, 2026Kinematic rigs provide a structured interface for articulating 3D meshes, but they lack an inherent representation of the plausible manifold of joint configurations for a given asset. Without such a pose space, stochastic sampling or manual manipulation of raw rig parameters often leads to semantic or geometric violations, such as anatomical hyperextension and non-physical self-intersections. We propose Video-informed Pose Spaces (ViPS), a feed-forward framework that discovers the latent distribution of valid articulations for auto-rigged meshes by distilling motion priors from a pretrained video diffusion model. Unlike existing methods that rely on scarce artist-authored 4D datasets, ViPS transfers generative video priors into a universal distribution over a given rig parameterization. Differentiable geometric validators applied to the skinned mesh enforce asset-specific validity without requiring manual regularizers. Our model learns a smooth, compact, and controllable pose space that supports diverse sampling, manifold projection for inverse kinematics, and temporally coherent trajectories for keyframing. Furthermore, the distilled 3D pose samples serve as precise semantic proxies for guiding video diffusion, effectively closing the loop between generative 2D priors and structured 3D kinematic control. Our evaluations show that ViPS, trained solely on video priors, matches the performance of state-of-the-art methods trained on synthetic artist-created 4D data in both plausibility and diversity. Most importantly, as a universal model, ViPS demonstrates robust zero-shot generalization to out-of-distribution species and unseen skeletal topologies.
TokenLight: Precise Lighting Control in Images using Attribute Tokens
Apr 16, 2026This paper presents a method for image relighting that enables precise and continuous control over multiple illumination attributes in a photograph. We formulate relighting as a conditional image generation task and introduce attribute tokens to encode distinct lighting factors such as intensity, color, ambient illumination, diffuse level, and 3D light positions. The model is trained on a large-scale synthetic dataset with ground-truth lighting annotations, supplemented by a small set of real captures to enhance realism and generalization. We validate our approach across a variety of relighting tasks, including controlling in-scene lighting fixtures and editing environment illumination using virtual light sources, on synthetic and real images. Our method achieves state-of-the-art quantitative and qualitative performance compared to prior work. Remarkably, without explicit inverse rendering supervision, the model exhibits an inherent understanding of how light interacts with scene geometry, occlusion, and materials, yielding convincing lighting effects even in traditionally challenging scenarios such as placing lights within objects or relighting transparent materials plausibly. Project page: vrroom.github.io/tokenlight/
OmniRoam: World Wandering via Long-Horizon Panoramic Video Generation
Mar 31, 2026Modeling scenes using video generation models has garnered growing research interest in recent years. However, most existing approaches rely on perspective video models that synthesize only limited observations of a scene, leading to issues of completeness and global consistency. We propose OmniRoam, a controllable panoramic video generation framework that exploits the rich per-frame scene coverage and inherent long-term spatial and temporal consistency of panoramic representation, enabling long-horizon scene wandering. Our framework begins with a preview stage, where a trajectory-controlled video generation model creates a quick overview of the scene from a given input image or video. Then, in the refine stage, this video is temporally extended and spatially upsampled to produce long-range, high-resolution videos, thus enabling high-fidelity world wandering. To train our model, we introduce two panoramic video datasets that incorporate both synthetic and real-world captured videos. Experiments show that our framework consistently outperforms state-of-the-art methods in terms of visual quality, controllability, and long-term scene consistency, both qualitatively and quantitatively. We further showcase several extensions of this framework, including real-time video generation and 3D reconstruction. Code is available at https://github.com/yuhengliu02/OmniRoam.
LightMover: Generative Light Movement with Color and Intensity Controls
Mar 28, 2026We present LightMover, a framework for controllable light manipulation in single images that leverages video diffusion priors to produce physically plausible illumination changes without re-rendering the scene. We formulate light editing as a sequence-to-sequence prediction problem in visual token space: given an image and light-control tokens, the model adjusts light position, color, and intensity together with resulting reflections, shadows, and falloff from a single view. This unified treatment of spatial (movement) and appearance (color, intensity) controls improves both manipulation and illumination understanding. We further introduce an adaptive token-pruning mechanism that preserves spatially informative tokens while compactly encoding non-spatial attributes, reducing control sequence length by 41% while maintaining editing fidelity. To train our framework, we construct a scalable rendering pipeline that generates large numbers of image pairs across varied light positions, colors, and intensities while keeping the scene content consistent with the original image. LightMover enables precise, independent control over light position, color, and intensity, and achieves high PSNR and strong semantic consistency (DINO, CLIP) across different tasks.
GimbalDiffusion: Gravity-Aware Camera Control for Video Generation
Dec 09, 2025



Recent progress in text-to-video generation has achieved remarkable realism, yet fine-grained control over camera motion and orientation remains elusive. Existing approaches typically encode camera trajectories through relative or ambiguous representations, limiting explicit geometric control. We introduce GimbalDiffusion, a framework that enables camera control grounded in physical-world coordinates, using gravity as a global reference. Instead of describing motion relative to previous frames, our method defines camera trajectories in an absolute coordinate system, allowing precise and interpretable control over camera parameters without requiring an initial reference frame. We leverage panoramic 360-degree videos to construct a wide variety of camera trajectories, well beyond the predominantly straight, forward-facing trajectories seen in conventional video data. To further enhance camera guidance, we introduce null-pitch conditioning, an annotation strategy that reduces the model's reliance on text content when conflicting with camera specifications (e.g., generating grass while the camera points towards the sky). Finally, we establish a benchmark for camera-aware video generation by rebalancing SpatialVID-HQ for comprehensive evaluation under wide camera pitch variation. Together, these contributions advance the controllability and robustness of text-to-video models, enabling precise, gravity-aligned camera manipulation within generative frameworks.
IntrinsicEdit: Precise generative image manipulation in intrinsic space
May 15, 2025



Generative diffusion models have advanced image editing with high-quality results and intuitive interfaces such as prompts and semantic drawing. However, these interfaces lack precise control, and the associated methods typically specialize on a single editing task. We introduce a versatile, generative workflow that operates in an intrinsic-image latent space, enabling semantic, local manipulation with pixel precision for a range of editing operations. Building atop the RGB-X diffusion framework, we address key challenges of identity preservation and intrinsic-channel entanglement. By incorporating exact diffusion inversion and disentangled channel manipulation, we enable precise, efficient editing with automatic resolution of global illumination effects -- all without additional data collection or model fine-tuning. We demonstrate state-of-the-art performance across a variety of tasks on complex images, including color and texture adjustments, object insertion and removal, global relighting, and their combinations.
GaSLight: Gaussian Splats for Spatially-Varying Lighting in HDR
Apr 15, 2025We present GaSLight, a method that generates spatially-varying lighting from regular images. Our method proposes using HDR Gaussian Splats as light source representation, marking the first time regular images can serve as light sources in a 3D renderer. Our two-stage process first enhances the dynamic range of images plausibly and accurately by leveraging the priors embedded in diffusion models. Next, we employ Gaussian Splats to model 3D lighting, achieving spatially variant lighting. Our approach yields state-of-the-art results on HDR estimations and their applications in illuminating virtual objects and scenes. To facilitate the benchmarking of images as light sources, we introduce a novel dataset of calibrated and unsaturated HDR to evaluate images as light sources. We assess our method using a combination of this novel dataset and an existing dataset from the literature. The code to reproduce our method will be available upon acceptance.
WorldPrompter: Traversable Text-to-Scene Generation
Apr 02, 2025



Scene-level 3D generation is a challenging research topic, with most existing methods generating only partial scenes and offering limited navigational freedom. We introduce WorldPrompter, a novel generative pipeline for synthesizing traversable 3D scenes from text prompts. We leverage panoramic videos as an intermediate representation to model the 360{\deg} details of a scene. WorldPrompter incorporates a conditional 360{\deg} panoramic video generator, capable of producing a 128-frame video that simulates a person walking through and capturing a virtual environment. The resulting video is then reconstructed as Gaussian splats by a fast feedforward 3D reconstructor, enabling a true walkable experience within the 3D scene. Experiments demonstrate that our panoramic video generation model achieves convincing view consistency across frames, enabling high-quality panoramic Gaussian splat reconstruction and facilitating traversal over an area of the scene. Qualitative and quantitative results also show it outperforms the state-of-the-art 360{\deg} video generators and 3D scene generation models.
MatSwap: Light-aware material transfers in images
Feb 11, 2025
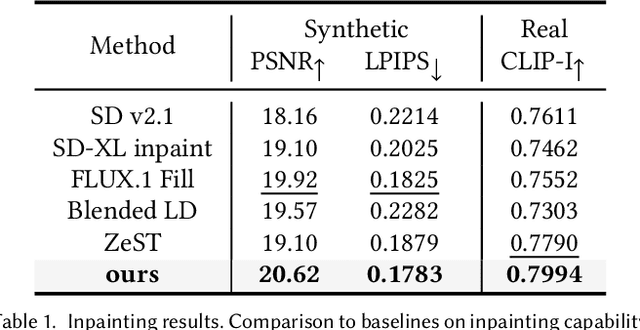
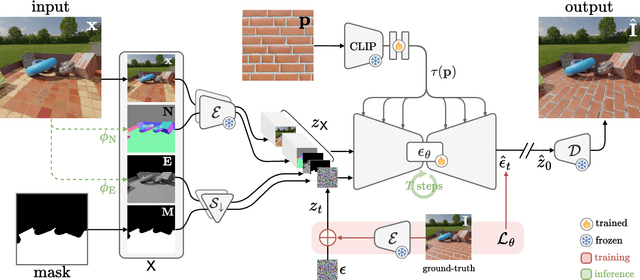
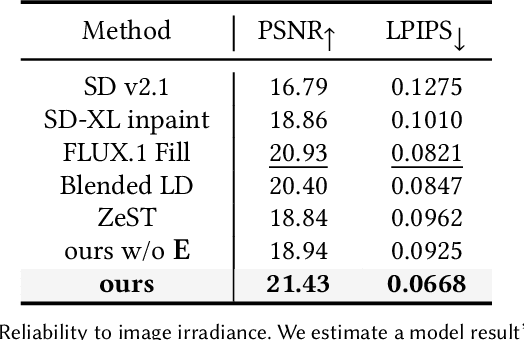
We present MatSwap, a method to transfer materials to designated surfaces in an image photorealistically. Such a task is non-trivial due to the large entanglement of material appearance, geometry, and lighting in a photograph. In the literature, material editing methods typically rely on either cumbersome text engineering or extensive manual annotations requiring artist knowledge and 3D scene properties that are impractical to obtain. In contrast, we propose to directly learn the relationship between the input material -- as observed on a flat surface -- and its appearance within the scene, without the need for explicit UV mapping. To achieve this, we rely on a custom light- and geometry-aware diffusion model. We fine-tune a large-scale pre-trained text-to-image model for material transfer using our synthetic dataset, preserving its strong priors to ensure effective generalization to real images. As a result, our method seamlessly integrates a desired material into the target location in the photograph while retaining the identity of the scene. We evaluate our method on synthetic and real images and show that it compares favorably to recent work both qualitatively and quantitatively. We will release our code and data upon publication.
SynthLight: Portrait Relighting with Diffusion Model by Learning to Re-render Synthetic Faces
Jan 16, 2025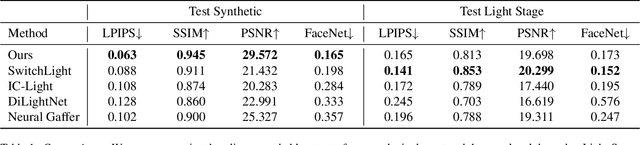

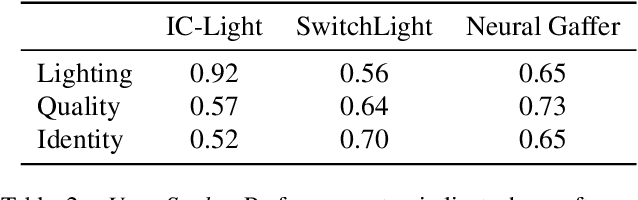
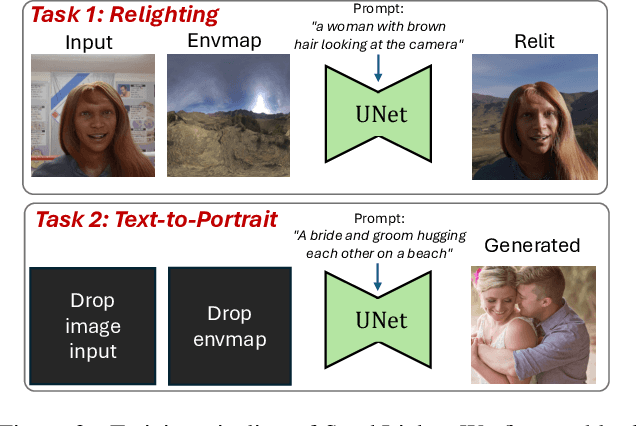
We introduce SynthLight, a diffusion model for portrait relighting. Our approach frames image relighting as a re-rendering problem, where pixels are transformed in response to changes in environmental lighting conditions. Using a physically-based rendering engine, we synthesize a dataset to simulate this lighting-conditioned transformation with 3D head assets under varying lighting. We propose two training and inference strategies to bridge the gap between the synthetic and real image domains: (1) multi-task training that takes advantage of real human portraits without lighting labels; (2) an inference time diffusion sampling procedure based on classifier-free guidance that leverages the input portrait to better preserve details. Our method generalizes to diverse real photographs and produces realistic illumination effects, including specular highlights and cast shadows, while preserving the subject's identity. Our quantitative experiments on Light Stage data demonstrate results comparable to state-of-the-art relighting methods. Our qualitative results on in-the-wild images showcase rich and unprecedented illumination effects. Project Page: \url{https://vrroom.github.io/synthlight/}