 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenFS: Multi-Hand-Capable Fingerspelling Recognition with Implicit Signing-Hand Detection and Frame-Wise Letter-Conditioned Synthesis
Feb 26, 2026Fingerspelling is a component of sign languages in which words are spelled out letter by letter using specific hand poses. Automatic fingerspelling recognition plays a crucial role in bridging the communication gap between Deaf and hearing communities, yet it remains challenging due to the signing-hand ambiguity issue, the lack of appropriate training losses, and the out-of-vocabulary (OOV) problem. Prior fingerspelling recognition methods rely on explicit signing-hand detection, which often leads to recognition failures, and on a connectionist temporal classification (CTC) loss, which exhibits the peaky behavior problem. To address these issues, we develop OpenFS, an open-source approach for fingerspelling recognition and synthesis. We propose a multi-hand-capable fingerspelling recognizer that supports both single- and multi-hand inputs and performs implicit signing-hand detection by incorporating a dual-level positional encoding and a signing-hand focus (SF) loss. The SF loss encourages cross-attention to focus on the signing hand, enabling implicit signing-hand detection during recognition. Furthermore, without relying on the CTC loss, we introduce a monotonic alignment (MA) loss that enforces the output letter sequence to follow the temporal order of the input pose sequence through cross-attention regularization. In addition, we propose a frame-wise letter-conditioned generator that synthesizes realistic fingerspelling pose sequences for OOV words. This generator enables the construction of a new synthetic benchmark, called FSNeo. Through comprehensive experiments, we demonstrate that our approach achieves state-of-the-art performance in recognition and validate the effectiveness of the proposed recognizer and generator. Codes and data are available in: https://github.com/JunukCha/OpenFS.
CoT-Pose: Chain-of-Thought Reasoning for 3D Pose Generation from Abstract Prompts
Aug 11, 2025Recent advances in multi-modal large language models (MLLMs) and chain-of-thought (CoT) reasoning have led to significant progress in image and text generation tasks. However, the field of 3D human pose generation still faces critical limitations. Most existing text-to-pose models rely heavily on detailed (low-level) prompts that explicitly describe joint configurations. In contrast, humans tend to communicate actions and intentions using abstract (high-level) language. This mismatch results in a practical challenge for deploying pose generation systems in real-world scenarios. To bridge this gap, we introduce a novel framework that incorporates CoT reasoning into the pose generation process, enabling the interpretation of abstract prompts into accurate 3D human poses. We further propose a data synthesis pipeline that automatically generates triplets of abstract prompts, detailed prompts, and corresponding 3D poses for training process. Experimental results demonstrate that our reasoning-enhanced model, CoT-Pose, can effectively generate plausible and semantically aligned poses from abstract textual inputs. This work highlights the importance of high-level understanding in pose generation and opens new directions for reasoning-enhanced approach for human pose generation.
BIGS: Bimanual Category-agnostic Interaction Reconstruction from Monocular Videos via 3D Gaussian Splatting
Apr 12, 2025Reconstructing 3Ds of hand-object interaction (HOI) is a fundamental problem that can find numerous applications. Despite recent advances, there is no comprehensive pipeline yet for bimanual class-agnostic interaction reconstruction from a monocular RGB video, where two hands and an unknown object are interacting with each other. Previous works tackled the limited hand-object interaction case, where object templates are pre-known or only one hand is involved in the interaction. The bimanual interaction reconstruction exhibits severe occlusions introduced by complex interactions between two hands and an object. To solve this, we first introduce BIGS (Bimanual Interaction 3D Gaussian Splatting), a method that reconstructs 3D Gaussians of hands and an unknown object from a monocular video. To robustly obtain object Gaussians avoiding severe occlusions, we leverage prior knowledge of pre-trained diffusion model with score distillation sampling (SDS) loss, to reconstruct unseen object parts. For hand Gaussians, we exploit the 3D priors of hand model (i.e., MANO) and share a single Gaussian for two hands to effectively accumulate hand 3D information, given limited views. To further consider the 3D alignment between hands and objects, we include the interacting-subjects optimization step during Gaussian optimization. Our method achieves the state-of-the-art accuracy on two challenging datasets, in terms of 3D hand pose estimation (MPJPE), 3D object reconstruction (CDh, CDo, F10), and rendering quality (PSNR, SSIM, LPIPS), respectively.
Text2Relight: Creative Portrait Relighting with Text Guidance
Dec 18, 2024



We present a lighting-aware image editing pipeline that, given a portrait image and a text prompt, performs single image relighting. Our model modifies the lighting and color of both the foreground and background to align with the provided text description. The unbounded nature in creativeness of a text allows us to describe the lighting of a scene with any sensory features including temperature, emotion, smell, time, and so on. However, the modeling of such mapping between the unbounded text and lighting is extremely challenging due to the lack of dataset where there exists no scalable data that provides large pairs of text and relighting, and therefore, current text-driven image editing models does not generalize to lighting-specific use cases. We overcome this problem by introducing a novel data synthesis pipeline: First, diverse and creative text prompts that describe the scenes with various lighting are automatically generated under a crafted hierarchy using a large language model (*e.g.,* ChatGPT). A text-guided image generation model creates a lighting image that best matches the text. As a condition of the lighting images, we perform image-based relighting for both foreground and background using a single portrait image or a set of OLAT (One-Light-at-A-Time) images captured from lightstage system. Particularly for the background relighting, we represent the lighting image as a set of point lights and transfer them to other background images. A generative diffusion model learns the synthesized large-scale data with auxiliary task augmentation (*e.g.,* portrait delighting and light positioning) to correlate the latent text and lighting distribution for text-guided portrait relighting.
1st Place Solution to the 8th HANDS Workshop Challenge -- ARCTIC Track: 3DGS-based Bimanual Category-agnostic Interaction Reconstruction
Sep 28, 2024



This report describes our 1st place solution to the 8th HANDS workshop challenge (ARCTIC track) in conjunction with ECCV 2024. In this challenge, we address the task of bimanual category-agnostic hand-object interaction reconstruction, which aims to generate 3D reconstructions of both hands and the object from a monocular video, without relying on predefined templates. This task is particularly challenging due to the significant occlusion and dynamic contact between the hands and the object during bimanual manipulation. We worked to resolve these issues by introducing a mask loss and a 3D contact loss, respectively. Moreover, we applied 3D Gaussian Splatting (3DGS) to this task. As a result, our method achieved a value of 38.69 in the main metric, CD$_h$, on the ARCTIC test set.
Text2HOI: Text-guided 3D Motion Generation for Hand-Object Interaction
Apr 02, 2024This paper introduces the first text-guided work for generating the sequence of hand-object interaction in 3D. The main challenge arises from the lack of labeled data where existing ground-truth datasets are nowhere near generalizable in interaction type and object category, which inhibits the modeling of diverse 3D hand-object interaction with the correct physical implication (e.g., contacts and semantics) from text prompts. To address this challenge, we propose to decompose the interaction generation task into two subtasks: hand-object contact generation; and hand-object motion generation. For contact generation, a VAE-based network takes as input a text and an object mesh, and generates the probability of contacts between the surfaces of hands and the object during the interaction. The network learns a variety of local geometry structure of diverse objects that is independent of the objects' category, and thus, it is applicable to general objects. For motion generation, a Transformer-based diffusion model utilizes this 3D contact map as a strong prior for generating physically plausible hand-object motion as a function of text prompts by learning from the augmented labeled dataset; where we annotate text labels from many existing 3D hand and object motion data. Finally, we further introduce a hand refiner module that minimizes the distance between the object surface and hand joints to improve the temporal stability of the object-hand contacts and to suppress the penetration artifacts. In the experiments, we demonstrate that our method can generate more realistic and diverse interactions compared to other baseline methods. We also show that our method is applicable to unseen objects. We will release our model and newly labeled data as a strong foundation for future research. Codes and data are available in: https://github.com/JunukCha/Text2HOI.
VLM-PL: Advanced Pseudo Labeling approach Class Incremental Object Detection with Vision-Language Model
Mar 08, 2024



In the field of Class Incremental Object Detection (CIOD), creating models that can continuously learn like humans is a major challenge. Pseudo-labeling methods, although initially powerful, struggle with multi-scenario incremental learning due to their tendency to forget past knowledge. To overcome this, we introduce a new approach called Vision-Language Model assisted Pseudo-Labeling (VLM-PL). This technique uses Vision-Language Model (VLM) to verify the correctness of pseudo ground-truths (GTs) without requiring additional model training. VLM-PL starts by deriving pseudo GTs from a pre-trained detector. Then, we generate custom queries for each pseudo GT using carefully designed prompt templates that combine image and text features. This allows the VLM to classify the correctness through its responses. Furthermore, VLM-PL integrates refined pseudo and real GTs from upcoming training, effectively combining new and old knowledge. Extensive experiments conducted on the Pascal VOC and MS COCO datasets not only highlight VLM-PL's exceptional performance in multi-scenario but also illuminate its effectiveness in dual-scenario by achieving state-of-the-art results in both.
3D Reconstruction of Interacting Multi-Person in Clothing from a Single Image
Jan 12, 2024This paper introduces a novel pipeline to reconstruct the geometry of interacting multi-person in clothing on a globally coherent scene space from a single image. The main challenge arises from the occlusion: a part of a human body is not visible from a single view due to the occlusion by others or the self, which introduces missing geometry and physical implausibility (e.g., penetration). We overcome this challenge by utilizing two human priors for complete 3D geometry and surface contacts. For the geometry prior, an encoder learns to regress the image of a person with missing body parts to the latent vectors; a decoder decodes these vectors to produce 3D features of the associated geometry; and an implicit network combines these features with a surface normal map to reconstruct a complete and detailed 3D humans. For the contact prior, we develop an image-space contact detector that outputs a probability distribution of surface contacts between people in 3D. We use these priors to globally refine the body poses, enabling the penetration-free and accurate reconstruction of interacting multi-person in clothing on the scene space. The results demonstrate that our method is complete, globally coherent, and physically plausible compared to existing methods.
Dynamic Appearance Modeling of Clothed 3D Human Avatars using a Single Camera
Dec 28, 2023The appearance of a human in clothing is driven not only by the pose but also by its temporal context, i.e., motion. However, such context has been largely neglected by existing monocular human modeling methods whose neural networks often struggle to learn a video of a person with large dynamics due to the motion ambiguity, i.e., there exist numerous geometric configurations of clothes that are dependent on the context of motion even for the same pose. In this paper, we introduce a method for high-quality modeling of clothed 3D human avatars using a video of a person with dynamic movements. The main challenge comes from the lack of 3D ground truth data of geometry and its temporal correspondences. We address this challenge by introducing a novel compositional human modeling framework that takes advantage of both explicit and implicit human modeling. For explicit modeling, a neural network learns to generate point-wise shape residuals and appearance features of a 3D body model by comparing its 2D rendering results and the original images. This explicit model allows for the reconstruction of discriminative 3D motion features from UV space by encoding their temporal correspondences. For implicit modeling, an implicit network combines the appearance and 3D motion features to decode high-fidelity clothed 3D human avatars with motion-dependent geometry and texture. The experiments show that our method can generate a large variation of secondary motion in a physically plausible way.
HOReeNet: 3D-aware Hand-Object Grasping Reenactment
Nov 11, 2022
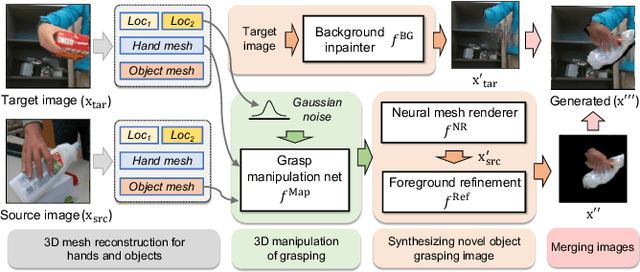

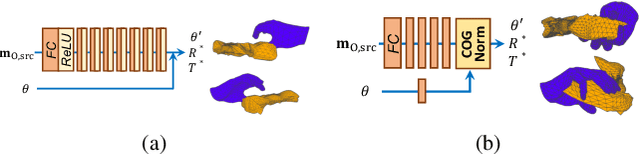
We present HOReeNet, which tackles the novel task of manipulating images involving hands, objects, and their interactions. Especially, we are interested in transferring objects of source images to target images and manipulating 3D hand postures to tightly grasp the transferred objects. Furthermore, the manipulation needs to be reflected in the 2D image space. In our reenactment scenario involving hand-object interactions, 3D reconstruction becomes essential as 3D contact reasoning between hands and objects is required to achieve a tight grasp. At the same time, to obtain high-quality 2D images from 3D space, well-designed 3D-to-2D projection and image refinement are required. Our HOReeNet is the first fully differentiable framework proposed for such a task. On hand-object interaction datasets, we compared our HOReeNet to the conventional image translation algorithms and reenactment algorithm. We demonstrated that our approach could achieved the state-of-the-art on the proposed task.