 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrinsic Image Decomposition for Robust Self-supervised Monocular Depth Estimation on Reflective Surfaces
Mar 28, 2025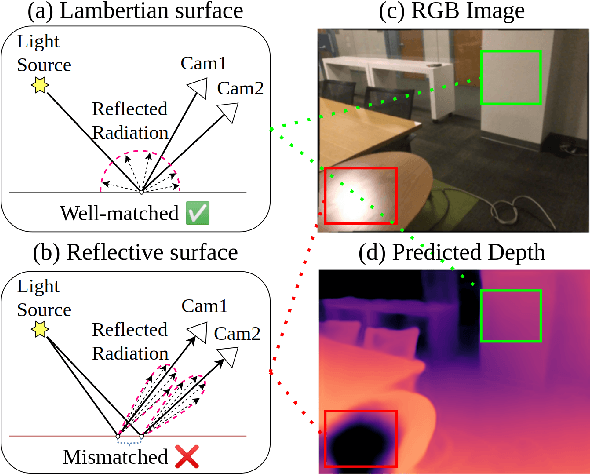
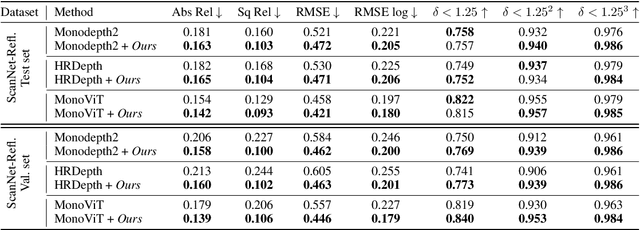
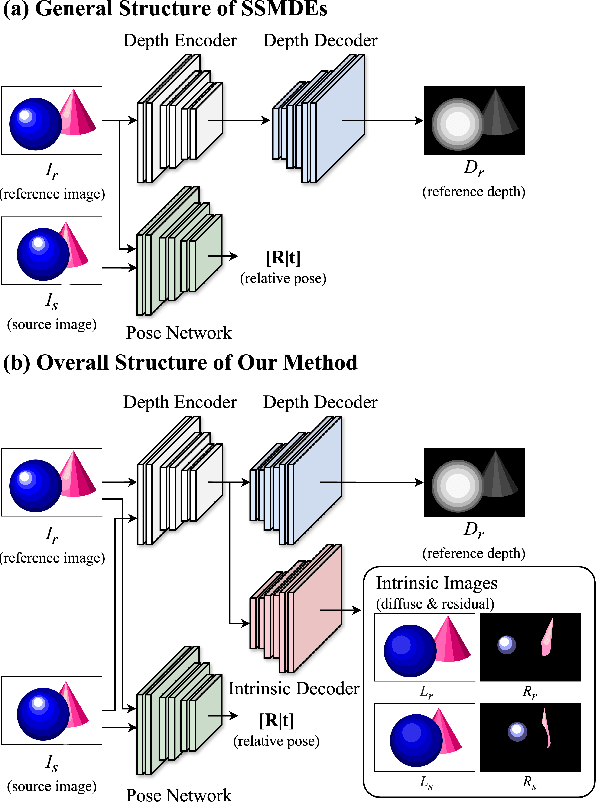
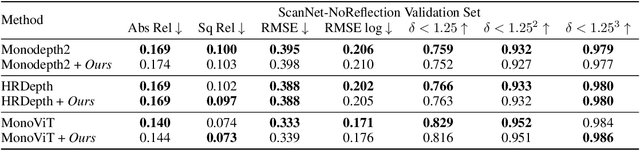
Self-supervised monocular depth estimation (SSMDE) has gained attention in the field of deep learning as it estimates depth without requiring ground truth depth maps. This approach typically uses a photometric consistency loss between a synthesized image, generated from the estimated depth, and the original image, thereby reducing the need for extensive dataset acquisition. However, the conventional photometric consistency loss relies on the Lambertian assumption, which often leads to significant errors when dealing with reflective surfaces that deviate from this model. To address this limitation, we propose a novel framework that incorporates intrinsic image decomposition into SSMDE. Our method synergistically trains for both monocular depth estimation and intrinsic image decomposition. The accurate depth estimation facilitates multi-image consistency for intrinsic image decomposition by aligning different view coordinate systems, while the decomposition process identifies reflective areas and excludes corrupted gradients from the depth training process. Furthermore, our framework introduces a pseudo-depth generation and knowledge distillation technique to further enhance the performance of the student model across both reflective and non-reflective surfaces. Comprehensive evaluations on multiple datasets show that our approach significantly outperforms existing SSMDE baselines in depth prediction, especially on reflective surfaces.
Multi-task Learning for Real-time Autonomous Driving Leveraging Task-adaptive Attention Generator
Mar 06, 2024



Real-time processing is crucial in autonomous driving systems due to the imperative of instantaneous decision-making and rapid response. In real-world scenarios, autonomous vehicles are continuously tasked with interpreting their surroundings, analyzing intricate sensor data, and making decisions within split seconds to ensure safety through numerous computer vision tasks. In this paper, we present a new real-time multi-task network adept at three vital autonomous driving tasks: monocular 3D object detection, semantic segmentation, and dense depth estimation. To counter the challenge of negative transfer, which is the prevalent issue in multi-task learning, we introduce a task-adaptive attention generator. This generator is designed to automatically discern interrelations across the three tasks and arrange the task-sharing pattern, all while leveraging the efficiency of the hard-parameter sharing approach. To the best of our knowledge, the proposed model is pioneering in its capability to concurrently handle multiple tasks, notably 3D object detection, while maintaining real-time processing speeds. Our rigorously optimized network, when tested on the Cityscapes-3D datasets, consistently outperforms various baseline models. Moreover, an in-depth ablation study substantiates the efficacy of the methodologies integrated into our framework.
Depth-discriminative Metric Learning for Monocular 3D Object Detection
Jan 02, 2024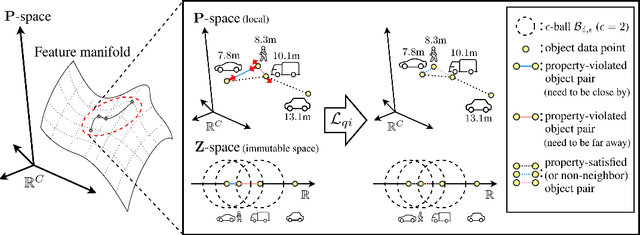
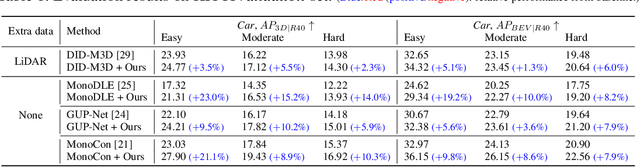
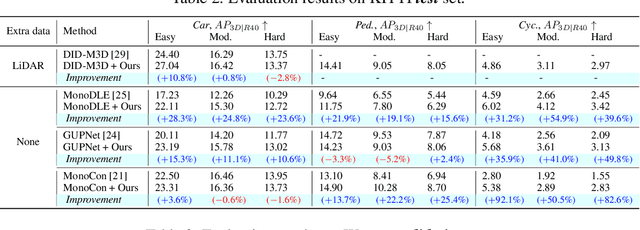
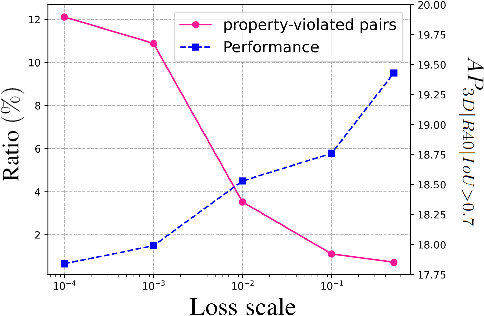
Monocular 3D object detection poses a significant challenge due to the lack of depth information in RGB images. Many existing methods strive to enhance the object depth estimation performance by allocating additional parameters for object depth estimation, utilizing extra modules or data. In contrast, we introduce a novel metric learning scheme that encourages the model to extract depth-discriminative features regardless of the visual attributes without increasing inference time and model size. Our method employs the distance-preserving function to organize the feature space manifold in relation to ground-truth object depth. The proposed (K, B, eps)-quasi-isometric loss leverages predetermined pairwise distance restriction as guidance for adjusting the distance among object descriptors without disrupting the non-linearity of the natural feature manifold. Moreover, we introduce an auxiliary head for object-wise depth estimation, which enhances depth quality while maintaining the inference time. The broad applicability of our method is demonstrated through experiments that show improvements in overall performance when integrated into various baselines. The results show that our method consistently improves the performance of various baselines by 23.51% and 5.78% on average across KITTI and Waymo, respectively.
Multi-Person 3D Pose and Shape Estimation via Inverse Kinematics and Refinement
Oct 30, 2022Estimating 3D poses and shapes in the form of meshes from monocular RGB images is challenging. Obviously, it is more difficult than estimating 3D poses only in the form of skeletons or heatmaps. When interacting persons are involved, the 3D mesh reconstruction becomes more challenging due to the ambiguity introduced by person-to-person occlusions. To tackle the challenges, we propose a coarse-to-fine pipeline that benefits from 1) inverse kinematics from the occlusion-robust 3D skeleton estimation and 2) Transformer-based relation-aware refinement techniques. In our pipeline, we first obtain occlusion-robust 3D skeletons for multiple persons from an RGB image. Then, we apply inverse kinematics to convert the estimated skeletons to deformable 3D mesh parameters. Finally, we apply the Transformer-based mesh refinement that refines the obtained mesh parameters considering intra- and inter-person relations of 3D meshes. Via extensive experiments, we demonstrate the effectiveness of our method, outperforming state-of-the-arts on 3DPW, MuPoTS and AGORA datasets.