 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale-invariant and View-relational Representation Learning for Full Surround Monocular Depth
Dec 09, 2025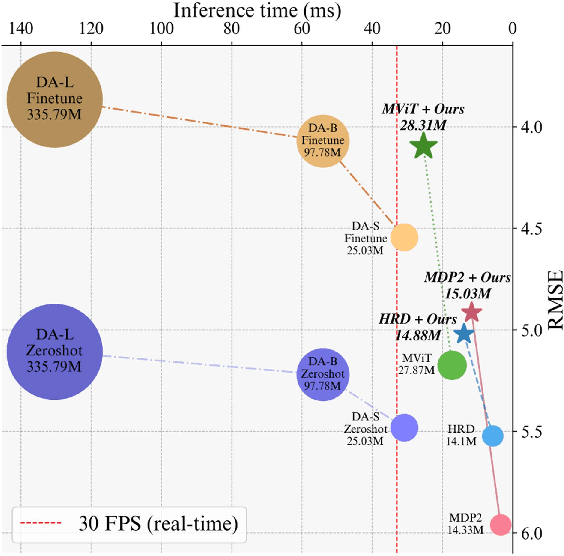
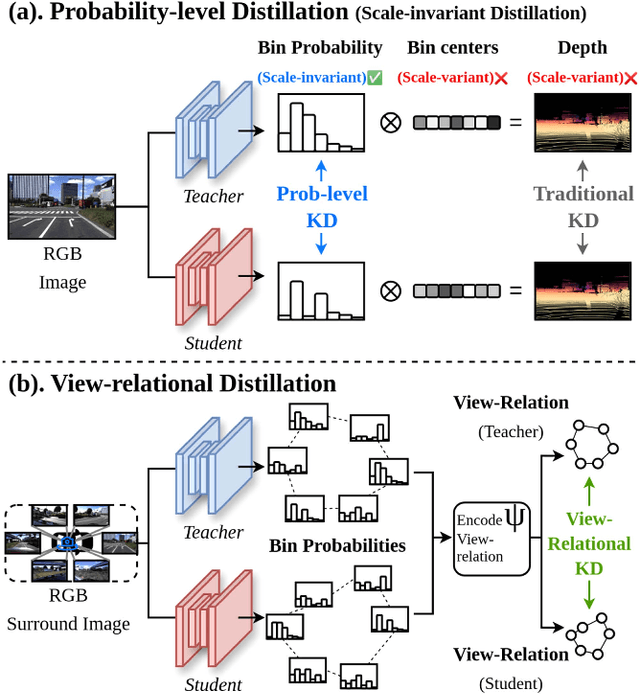
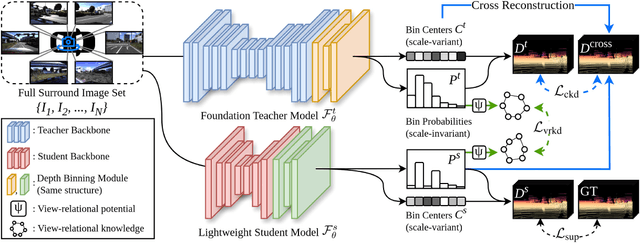

Recent foundation models demonstrate strong generalization capabilities in monocular depth estimation. However, directly applying these models to Full Surround Monocular Depth Estimation (FSMDE) presents two major challenges: (1) high computational cost, which limits real-time performance, and (2) difficulty in estimating metric-scale depth, as these models are typically trained to predict only relative depth. To address these limitations, we propose a novel knowledge distillation strategy that transfers robust depth knowledge from a foundation model to a lightweight FSMDE network. Our approach leverages a hybrid regression framework combining the knowledge distillation scheme--traditionally used in classification--with a depth binning module to enhance scale consistency. Specifically, we introduce a cross-interaction knowledge distillation scheme that distills the scale-invariant depth bin probabilities of a foundation model into the student network while guiding it to infer metric-scale depth bin centers from ground-truth depth. Furthermore, we propose view-relational knowledge distillation, which encodes structural relationships among adjacent camera views and transfers them to enhance cross-view depth consistency. Experiments on DDAD and nuScenes demonstrate the effectiveness of our method compared to conventional supervised methods and existing knowledge distillation approaches. Moreover, our method achieves a favorable trade-off between performance and efficiency, meeting real-time requirements.
Infinite-Story: A Training-Free Consistent Text-to-Image Generation
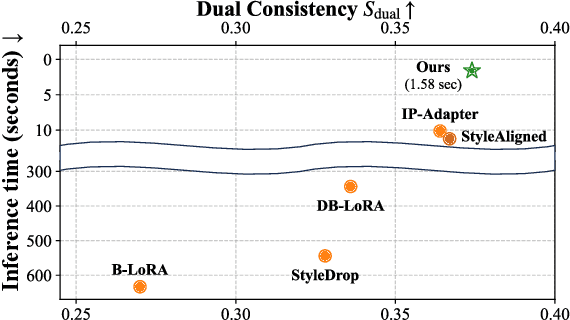
Nov 17, 2025We present Infinite-Story, a training-free framework for consistent text-to-image (T2I) generation tailored for multi-prompt storytelling scenarios. Built upon a scale-wise autoregressive model, our method addresses two key challenges in consistent T2I generation: identity inconsistency and style inconsistency. To overcome these issues, we introduce three complementary techniques: Identity Prompt Replacement, which mitigates context bias in text encoders to align identity attributes across prompts; and a unified attention guidance mechanism comprising Adaptive Style Injection and Synchronized Guidance Adaptation, which jointly enforce global style and identity appearance consistency while preserving prompt fidelity. Unlike prior diffusion-based approaches that require fine-tuning or suffer from slow inference, Infinite-Story operates entirely at test time, delivering high identity and style consistency across diverse prompts. Extensive experiments demonstrate that our method achieves state-of-the-art generation performance, while offering over 6X faster inference (1.72 seconds per image) than the existing fastest consistent T2I models, highlighting its effectiveness and practicality for real-world visual storytelling.
A Training-Free Style-aligned Image Generation with Scale-wise Autoregressive Model
Apr 08, 2025

We present a training-free style-aligned image generation method that leverages a scale-wise autoregressive model. While large-scale text-to-image (T2I) models, particularly diffusion-based methods, have demonstrated impressive generation quality, they often suffer from style misalignment across generated image sets and slow inference speeds, limiting their practical usability. To address these issues, we propose three key components: initial feature replacement to ensure consistent background appearance, pivotal feature interpolation to align object placement, and dynamic style injection, which reinforces style consistency using a schedule function. Unlike previous methods requiring fine-tuning or additional training, our approach maintains fast inference while preserving individual content details. Extensive experiments show that our method achieves generation quality comparable to competing approaches, significantly improves style alignment, and delivers inference speeds over six times faster than the fastest model.
Intrinsic Image Decomposition for Robust Self-supervised Monocular Depth Estimation on Reflective Surfaces
Mar 28, 2025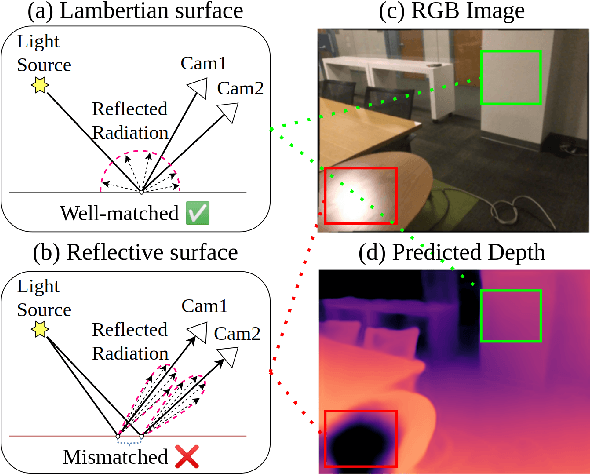
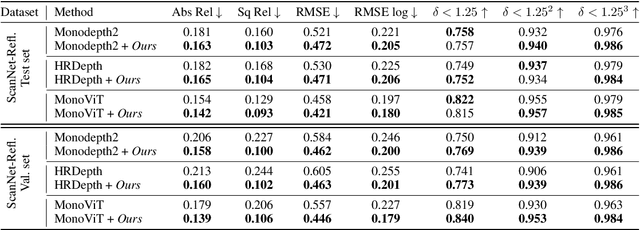
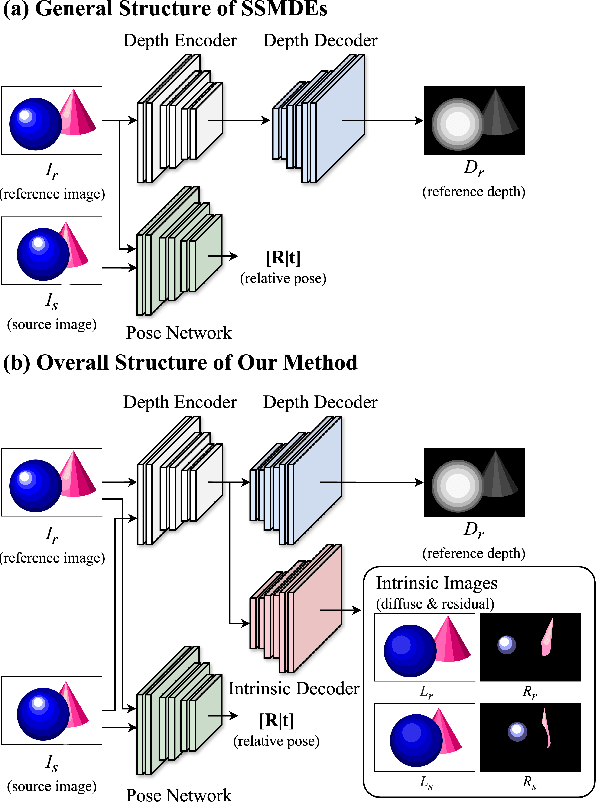
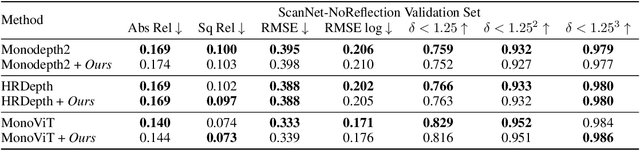
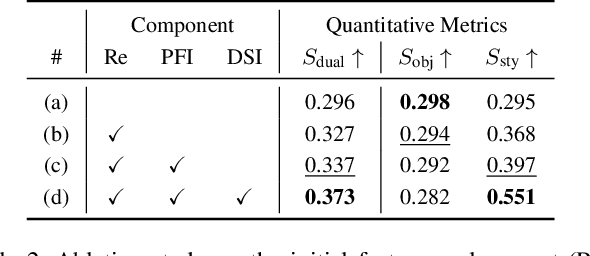
Self-supervised monocular depth estimation (SSMDE) has gained attention in the field of deep learning as it estimates depth without requiring ground truth depth maps. This approach typically uses a photometric consistency loss between a synthesized image, generated from the estimated depth, and the original image, thereby reducing the need for extensive dataset acquisition. However, the conventional photometric consistency loss relies on the Lambertian assumption, which often leads to significant errors when dealing with reflective surfaces that deviate from this model. To address this limitation, we propose a novel framework that incorporates intrinsic image decomposition into SSMDE. Our method synergistically trains for both monocular depth estimation and intrinsic image decomposition. The accurate depth estimation facilitates multi-image consistency for intrinsic image decomposition by aligning different view coordinate systems, while the decomposition process identifies reflective areas and excludes corrupted gradients from the depth training process. Furthermore, our framework introduces a pseudo-depth generation and knowledge distillation technique to further enhance the performance of the student model across both reflective and non-reflective surfaces. Comprehensive evaluations on multiple datasets show that our approach significantly outperforms existing SSMDE baselines in depth prediction, especially on reflective surfaces.
Context-Aware Video Instance Segmentation
Jul 03, 2024



In this paper, we introduce the Context-Aware Video Instance Segmentation (CAVIS), a novel framework designed to enhance instance association by integrating contextual information adjacent to each object. To efficiently extract and leverage this information, we propose the Context-Aware Instance Tracker (CAIT), which merges contextual data surrounding the instances with the core instance features to improve tracking accuracy. Additionally, we introduce the Prototypical Cross-frame Contrastive (PCC) loss, which ensures consistency in object-level features across frames, thereby significantly enhancing instance matching accuracy. CAVIS demonstrates superior performance over state-of-the-art methods on all benchmark datasets in video instance segmentation (VIS) and video panoptic segmentation (VPS). Notably, our method excels on the OVIS dataset, which is known for its particularly challenging videos.
ADAS: A Direct Adaptation Strategy for Multi-Target Domain Adaptive Semantic Segmentation
Mar 14, 2022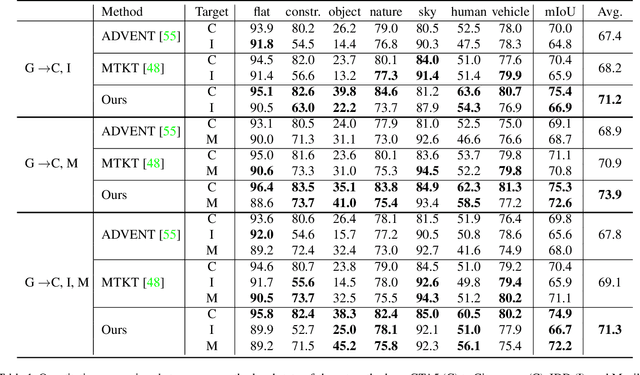



In this paper, we present a direct adaptation strategy (ADAS), which aims to directly adapt a single model to multiple target domains in a semantic segmentation task without pretrained domain-specific models. To do so, we design a multi-target domain transfer network (MTDT-Net) that aligns visual attributes across domains by transferring the domain distinctive features through a new target adaptive denormalization (TAD) module. Moreover, we propose a bi-directional adaptive region selection (BARS) that reduces the attribute ambiguity among the class labels by adaptively selecting the regions with consistent feature statistics. We show that our single MTDT-Net can synthesize visually pleasing domain transferred images with complex driving datasets, and BARS effectively filters out the unnecessary region of training images for each target domain. With the collaboration of MTDT-Net and BARS, our ADAS achieves state-of-the-art performance for multi-target domain adaptation (MTDA). To the best of our knowledge, our method is the first MTDA method that directly adapts to multiple domains in semantic segmentation.