 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale-invariant and View-relational Representation Learning for Full Surround Monocular Depth
Dec 09, 2025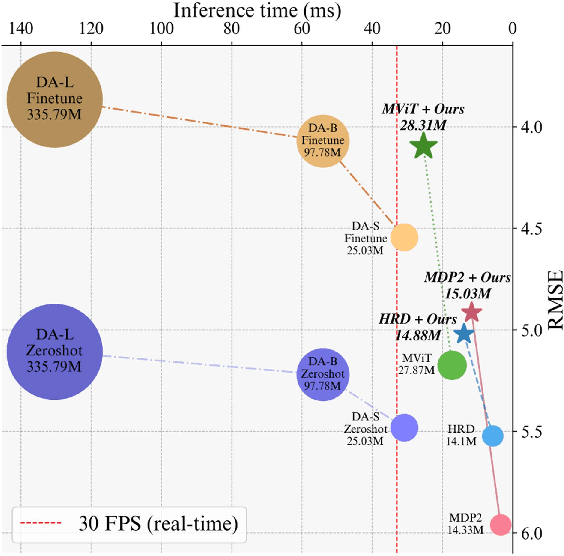
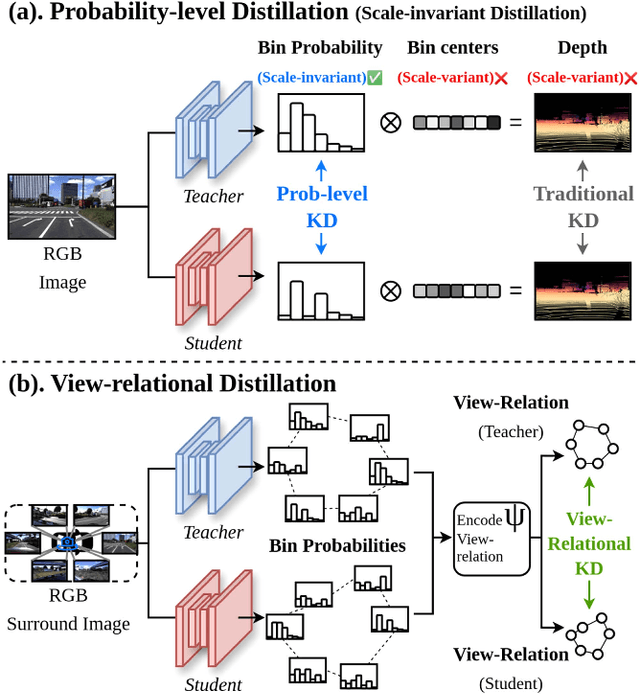
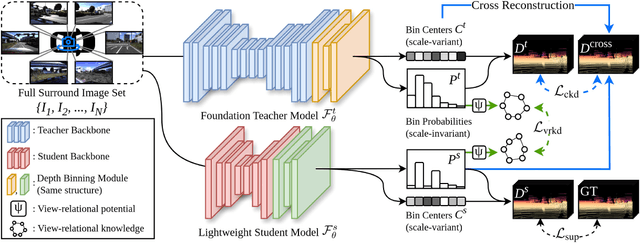

Recent foundation models demonstrate strong generalization capabilities in monocular depth estimation. However, directly applying these models to Full Surround Monocular Depth Estimation (FSMDE) presents two major challenges: (1) high computational cost, which limits real-time performance, and (2) difficulty in estimating metric-scale depth, as these models are typically trained to predict only relative depth. To address these limitations, we propose a novel knowledge distillation strategy that transfers robust depth knowledge from a foundation model to a lightweight FSMDE network. Our approach leverages a hybrid regression framework combining the knowledge distillation scheme--traditionally used in classification--with a depth binning module to enhance scale consistency. Specifically, we introduce a cross-interaction knowledge distillation scheme that distills the scale-invariant depth bin probabilities of a foundation model into the student network while guiding it to infer metric-scale depth bin centers from ground-truth depth. Furthermore, we propose view-relational knowledge distillation, which encodes structural relationships among adjacent camera views and transfers them to enhance cross-view depth consistency. Experiments on DDAD and nuScenes demonstrate the effectiveness of our method compared to conventional supervised methods and existing knowledge distillation approaches. Moreover, our method achieves a favorable trade-off between performance and efficiency, meeting real-time requirements.
Infinite-Story: A Training-Free Consistent Text-to-Image Generation
Nov 17, 2025We present Infinite-Story, a training-free framework for consistent text-to-image (T2I) generation tailored for multi-prompt storytelling scenarios. Built upon a scale-wise autoregressive model, our method addresses two key challenges in consistent T2I generation: identity inconsistency and style inconsistency. To overcome these issues, we introduce three complementary techniques: Identity Prompt Replacement, which mitigates context bias in text encoders to align identity attributes across prompts; and a unified attention guidance mechanism comprising Adaptive Style Injection and Synchronized Guidance Adaptation, which jointly enforce global style and identity appearance consistency while preserving prompt fidelity. Unlike prior diffusion-based approaches that require fine-tuning or suffer from slow inference, Infinite-Story operates entirely at test time, delivering high identity and style consistency across diverse prompts. Extensive experiments demonstrate that our method achieves state-of-the-art generation performance, while offering over 6X faster inference (1.72 seconds per image) than the existing fastest consistent T2I models, highlighting its effectiveness and practicality for real-world visual storytelling.
Bridging Geometric and Semantic Foundation Models for Generalized Monocular Depth Estimation
May 29, 2025We present Bridging Geometric and Semantic (BriGeS), an effective method that fuses geometric and semantic information within foundation models to enhance Monocular Depth Estimation (MDE). Central to BriGeS is the Bridging Gate, which integrates the complementary strengths of depth and segmentation foundation models. This integration is further refined by our Attention Temperature Scaling technique. It finely adjusts the focus of the attention mechanisms to prevent over-concentration on specific features, thus ensuring balanced performance across diverse inputs. BriGeS capitalizes on pre-trained foundation models and adopts a strategy that focuses on training only the Bridging Gate. This method significantly reduces resource demands and training time while maintaining the model's ability to generalize effectively. Extensive experiments across multiple challenging datasets demonstrate that BriGeS outperforms state-of-the-art methods in MDE for complex scenes, effectively handling intricate structures and overlapping objects.
A Training-Free Style-aligned Image Generation with Scale-wise Autoregressive Model
Apr 08, 2025

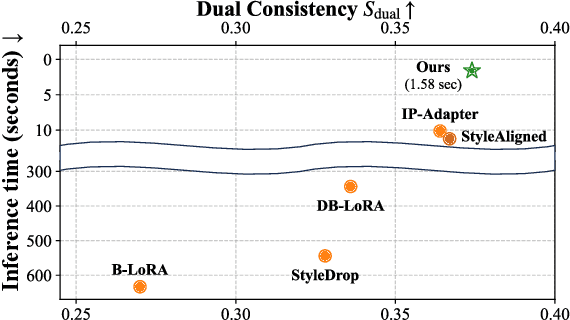
We present a training-free style-aligned image generation method that leverages a scale-wise autoregressive model. While large-scale text-to-image (T2I) models, particularly diffusion-based methods, have demonstrated impressive generation quality, they often suffer from style misalignment across generated image sets and slow inference speeds, limiting their practical usability. To address these issues, we propose three key components: initial feature replacement to ensure consistent background appearance, pivotal feature interpolation to align object placement, and dynamic style injection, which reinforces style consistency using a schedule function. Unlike previous methods requiring fine-tuning or additional training, our approach maintains fast inference while preserving individual content details. Extensive experiments show that our method achieves generation quality comparable to competing approaches, significantly improves style alignment, and delivers inference speeds over six times faster than the fastest model.
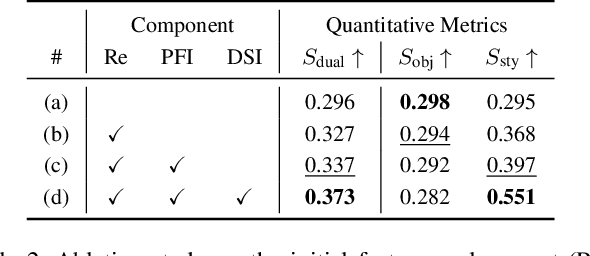
Intrinsic Image Decomposition for Robust Self-supervised Monocular Depth Estimation on Reflective Surfaces
Mar 28, 2025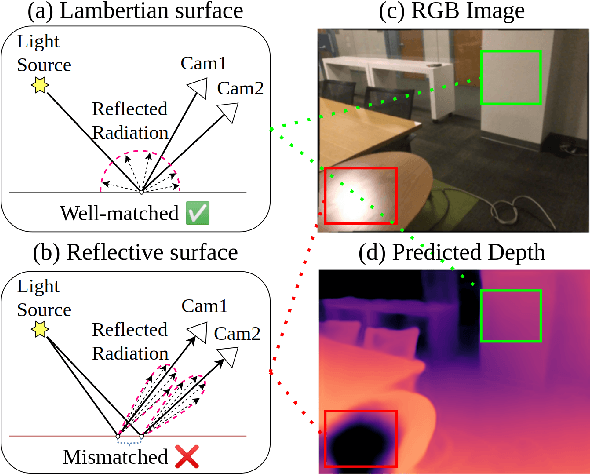
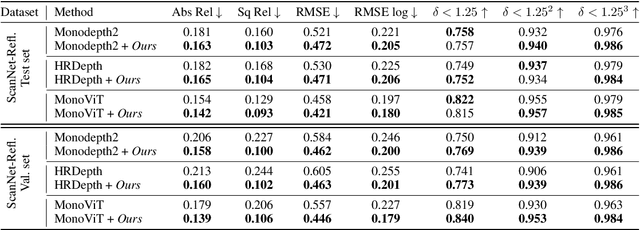
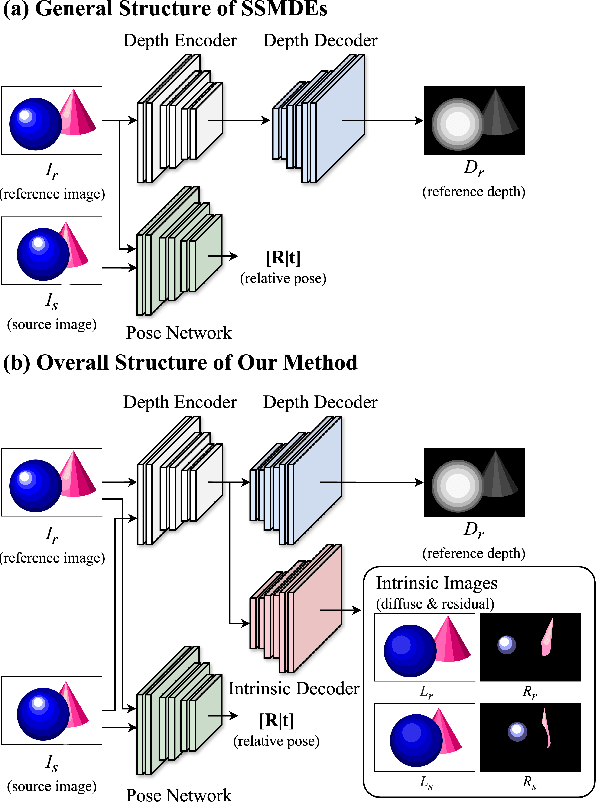
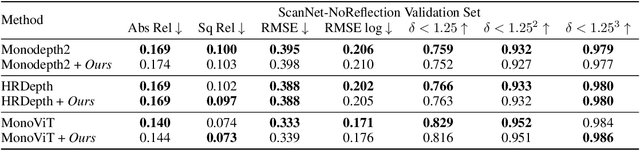
Self-supervised monocular depth estimation (SSMDE) has gained attention in the field of deep learning as it estimates depth without requiring ground truth depth maps. This approach typically uses a photometric consistency loss between a synthesized image, generated from the estimated depth, and the original image, thereby reducing the need for extensive dataset acquisition. However, the conventional photometric consistency loss relies on the Lambertian assumption, which often leads to significant errors when dealing with reflective surfaces that deviate from this model. To address this limitation, we propose a novel framework that incorporates intrinsic image decomposition into SSMDE. Our method synergistically trains for both monocular depth estimation and intrinsic image decomposition. The accurate depth estimation facilitates multi-image consistency for intrinsic image decomposition by aligning different view coordinate systems, while the decomposition process identifies reflective areas and excludes corrupted gradients from the depth training process. Furthermore, our framework introduces a pseudo-depth generation and knowledge distillation technique to further enhance the performance of the student model across both reflective and non-reflective surfaces. Comprehensive evaluations on multiple datasets show that our approach significantly outperforms existing SSMDE baselines in depth prediction, especially on reflective surfaces.
Towards Lossless Implicit Neural Representation via Bit Plane Decomposition
Feb 28, 2025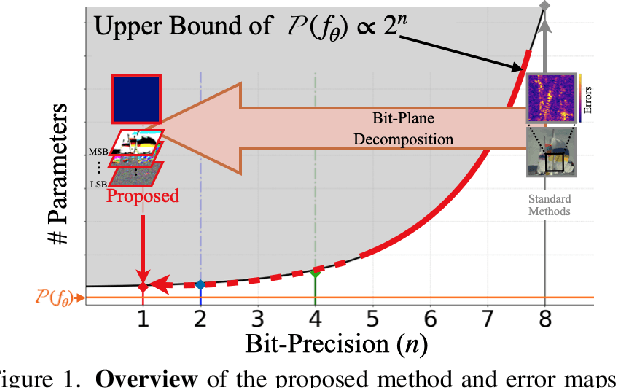

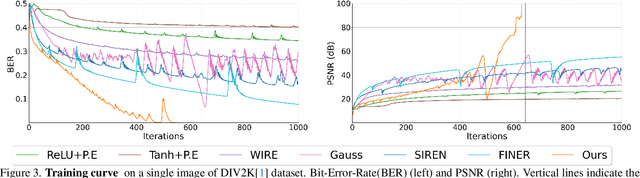
We quantify the upper bound on the size of the implicit neural representation (INR) model from a digital perspective. The upper bound of the model size increases exponentially as the required bit-precision increases. To this end, we present a bit-plane decomposition method that makes INR predict bit-planes, producing the same effect as reducing the upper bound of the model size. We validate our hypothesis that reducing the upper bound leads to faster convergence with constant model size. Our method achieves lossless representation in 2D image and audio fitting, even for high bit-depth signals, such as 16-bit, which was previously unachievable. We pioneered the presence of bit bias, which INR prioritizes as the most significant bit (MSB). We expand the application of the INR task to bit depth expansion, lossless image compression, and extreme network quantization. Our source code is available at https://github.com/WooKyoungHan/LosslessINR
BurstM: Deep Burst Multi-scale SR using Fourier Space with Optical Flow
Sep 21, 2024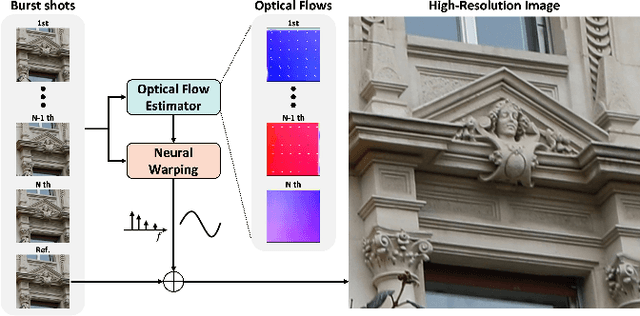
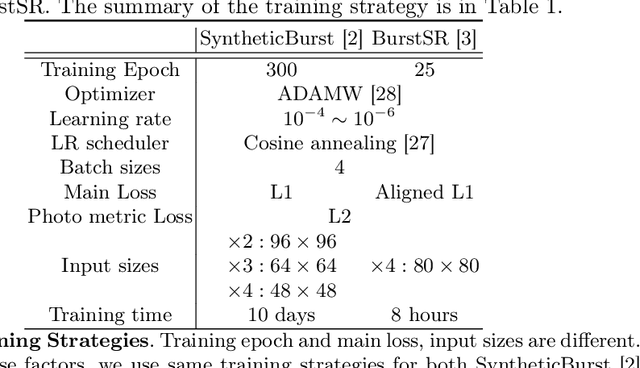
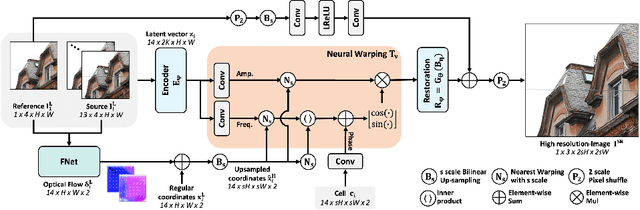
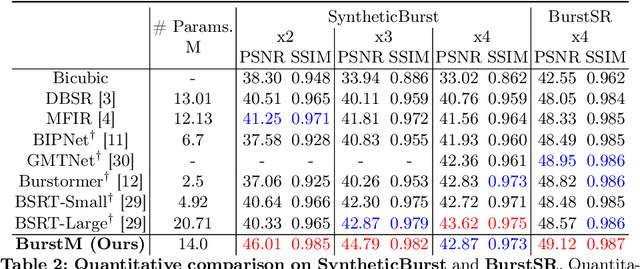
Multi frame super-resolution(MFSR) achieves higher performance than single image super-resolution (SISR), because MFSR leverages abundant information from multiple frames. Recent MFSR approaches adapt the deformable convolution network (DCN) to align the frames. However, the existing MFSR suffers from misalignments between the reference and source frames due to the limitations of DCN, such as small receptive fields and the predefined number of kernels. From these problems, existing MFSR approaches struggle to represent high-frequency information. To this end, we propose Deep Burst Multi-scale SR using Fourier Space with Optical Flow (BurstM). The proposed method estimates the optical flow offset for accurate alignment and predicts the continuous Fourier coefficient of each frame for representing high-frequency textures. In addition, we have enhanced the network flexibility by supporting various super-resolution (SR) scale factors with the unimodel. We demonstrate that our method has the highest performance and flexibility than the existing MFSR methods. Our source code is available at https://github.com/Egkang-Luis/burstm
TEXTOC: Text-driven Object-Centric Style Transfer
Aug 16, 2024

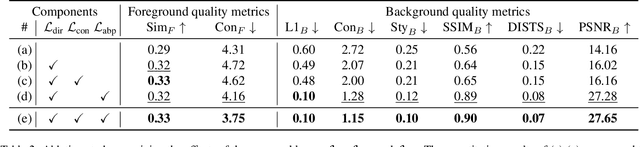
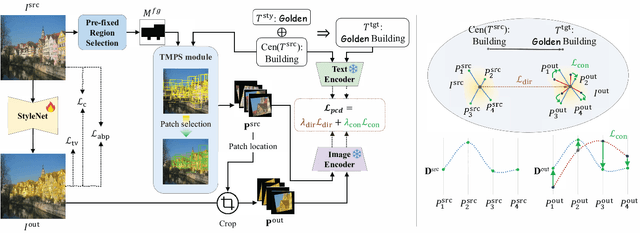
We present Text-driven Object-Centric Style Transfer (TEXTOC), a novel method that guides style transfer at an object-centric level using textual inputs. The core of TEXTOC is our Patch-wise Co-Directional (PCD) loss, meticulously designed for precise object-centric transformations that are closely aligned with the input text. This loss combines a patch directional loss for text-guided style direction and a patch distribution consistency loss for even CLIP embedding distribution across object regions. It ensures a seamless and harmonious style transfer across object regions. Key to our method are the Text-Matched Patch Selection (TMPS) and Pre-fixed Region Selection (PRS) modules for identifying object locations via text, eliminating the need for segmentation masks. Lastly, we introduce an Adaptive Background Preservation (ABP) loss to maintain the original style and structural essence of the image's background. This loss is applied to dynamically identified background areas. Extensive experiments underline the effectiveness of our approach in creating visually coherent and textually aligned style transfers.
Flow4D: Leveraging 4D Voxel Network for LiDAR Scene Flow Estimation
Jul 10, 2024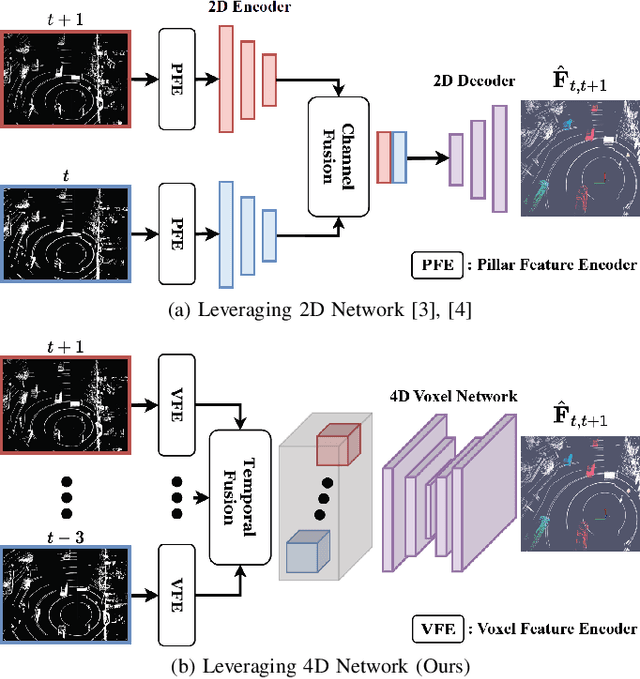
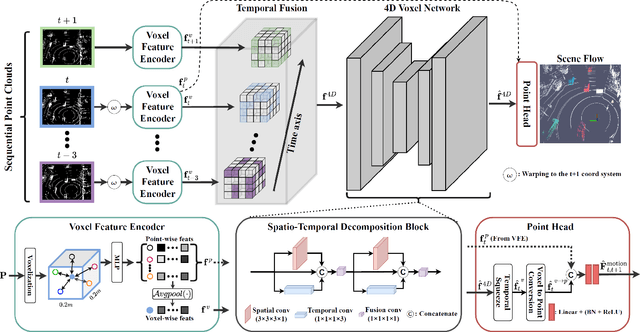
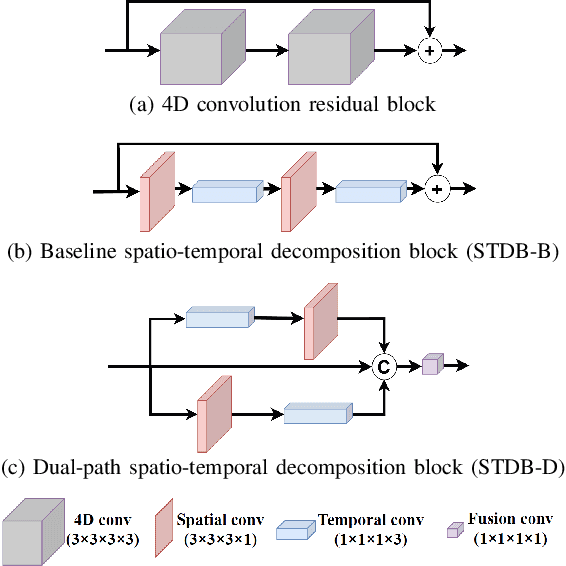
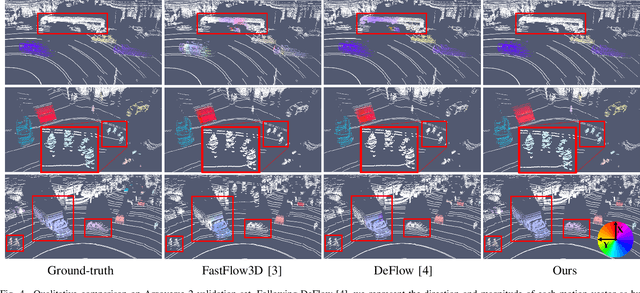
Understanding the motion states of the surrounding environment is critical for safe autonomous driving. These motion states can be accurately derived from scene flow, which captures the three-dimensional motion field of points. Existing LiDAR scene flow methods extract spatial features from each point cloud and then fuse them channel-wise, resulting in the implicit extraction of spatio-temporal features. Furthermore, they utilize 2D Bird's Eye View and process only two frames, missing crucial spatial information along the Z-axis and the broader temporal context, leading to suboptimal performance. To address these limitations, we propose Flow4D, which temporally fuses multiple point clouds after the 3D intra-voxel feature encoder, enabling more explicit extraction of spatio-temporal features through a 4D voxel network. However, while using 4D convolution improves performance, it significantly increases the computational load. For further efficiency, we introduce the Spatio-Temporal Decomposition Block (STDB), which combines 3D and 1D convolutions instead of using heavy 4D convolution. In addition, Flow4D further improves performance by using five frames to take advantage of richer temporal information. As a result, the proposed method achieves a 45.9% higher performance compared to the state-of-the-art while running in real-time, and won 1st place in the 2024 Argoverse 2 Scene Flow Challenge. The code is available at https://github.com/dgist-cvlab/Flow4D.
Context-Aware Video Instance Segmentation
Jul 03, 2024



In this paper, we introduce the Context-Aware Video Instance Segmentation (CAVIS), a novel framework designed to enhance instance association by integrating contextual information adjacent to each object. To efficiently extract and leverage this information, we propose the Context-Aware Instance Tracker (CAIT), which merges contextual data surrounding the instances with the core instance features to improve tracking accuracy. Additionally, we introduce the Prototypical Cross-frame Contrastive (PCC) loss, which ensures consistency in object-level features across frames, thereby significantly enhancing instance matching accuracy. CAVIS demonstrates superior performance over state-of-the-art methods on all benchmark datasets in video instance segmentation (VIS) and video panoptic segmentation (VPS). Notably, our method excels on the OVIS dataset, which is known for its particularly challenging videos.