 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAG:Tangential Amplifying Guidance for Hallucination-Resistant Diffusion Sampling
Oct 06, 2025Recent diffusion models achieve the state-of-the-art performance in image generation, but often suffer from semantic inconsistencies or hallucinations. While various inference-time guidance methods can enhance generation, they often operate indirectly by relying on external signals or architectural modifications, which introduces additional computational overhead. In this paper, we propose Tangential Amplifying Guidance (TAG), a more efficient and direct guidance method that operates solely on trajectory signals without modifying the underlying diffusion model. TAG leverages an intermediate sample as a projection basis and amplifies the tangential components of the estimated scores with respect to this basis to correct the sampling trajectory. We formalize this guidance process by leveraging a first-order Taylor expansion, which demonstrates that amplifying the tangential component steers the state toward higher-probability regions, thereby reducing inconsistencies and enhancing sample quality. TAG is a plug-and-play, architecture-agnostic module that improves diffusion sampling fidelity with minimal computational addition, offering a new perspective on diffusion guidance.
Towards Lossless Implicit Neural Representation via Bit Plane Decomposition
Feb 28, 2025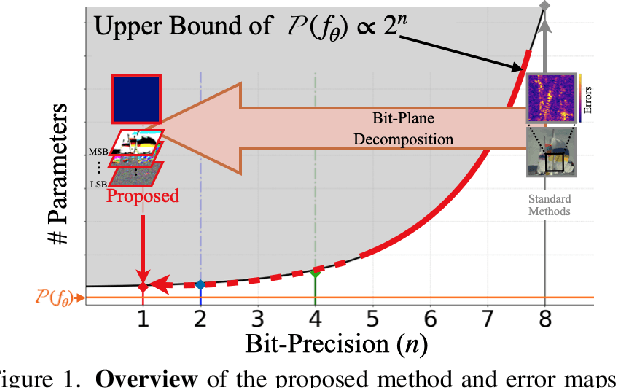

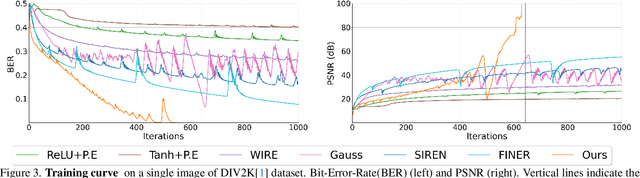
We quantify the upper bound on the size of the implicit neural representation (INR) model from a digital perspective. The upper bound of the model size increases exponentially as the required bit-precision increases. To this end, we present a bit-plane decomposition method that makes INR predict bit-planes, producing the same effect as reducing the upper bound of the model size. We validate our hypothesis that reducing the upper bound leads to faster convergence with constant model size. Our method achieves lossless representation in 2D image and audio fitting, even for high bit-depth signals, such as 16-bit, which was previously unachievable. We pioneered the presence of bit bias, which INR prioritizes as the most significant bit (MSB). We expand the application of the INR task to bit depth expansion, lossless image compression, and extreme network quantization. Our source code is available at https://github.com/WooKyoungHan/LosslessINR
Identity-preserving Distillation Sampling by Fixed-Point Iterator
Feb 27, 2025Score distillation sampling (SDS) demonstrates a powerful capability for text-conditioned 2D image and 3D object generation by distilling the knowledge from learned score functions. However, SDS often suffers from blurriness caused by noisy gradients. When SDS meets the image editing, such degradations can be reduced by adjusting bias shifts using reference pairs, but the de-biasing techniques are still corrupted by erroneous gradients. To this end, we introduce Identity-preserving Distillation Sampling (IDS), which compensates for the gradient leading to undesired changes in the results. Based on the analysis that these errors come from the text-conditioned scores, a new regularization technique, called fixed-point iterative regularization (FPR), is proposed to modify the score itself, driving the preservation of the identity even including poses and structures. Thanks to a self-correction by FPR, the proposed method provides clear and unambiguous representations corresponding to the given prompts in image-to-image editing and editable neural radiance field (NeRF). The structural consistency between the source and the edited data is obviously maintained compared to other state-of-the-art methods.
BF-STVSR: B-Splines and Fourier-Best Friends for High Fidelity Spatial-Temporal Video Super-Resolution
Jan 19, 2025Enhancing low-resolution, low-frame-rate videos to high-resolution, high-frame-rate quality is essential for a seamless user experience, motivating advancements in Continuous Spatial-Temporal Video Super Resolution (C-STVSR). While prior methods employ Implicit Neural Representation (INR) for continuous encoding, they often struggle to capture the complexity of video data, relying on simple coordinate concatenation and pre-trained optical flow network for motion representation. Interestingly, we find that adding position encoding, contrary to common observations, does not improve-and even degrade performance. This issue becomes particularly pronounced when combined with pre-trained optical flow networks, which can limit the model's flexibility. To address these issues, we propose BF-STVSR, a C-STVSR framework with two key modules tailored to better represent spatial and temporal characteristics of video: 1) B-spline Mapper for smooth temporal interpolation, and 2) Fourier Mapper for capturing dominant spatial frequencies. Our approach achieves state-of-the-art PSNR and SSIM performance, showing enhanced spatial details and natural temporal consistency.
A Noise is Worth Diffusion Guidance
Dec 05, 2024
Diffusion models excel in generating high-quality images. However, current diffusion models struggle to produce reliable images without guidance methods, such as classifier-free guidance (CFG). Are guidance methods truly necessary? Observing that noise obtained via diffusion inversion can reconstruct high-quality images without guidance, we focus on the initial noise of the denoising pipeline. By mapping Gaussian noise to `guidance-free noise', we uncover that small low-magnitude low-frequency components significantly enhance the denoising process, removing the need for guidance and thus improving both inference throughput and memory. Expanding on this, we propose \ours, a novel method that replaces guidance methods with a single refinement of the initial noise. This refined noise enables high-quality image generation without guidance, within the same diffusion pipeline. Our noise-refining model leverages efficient noise-space learning, achieving rapid convergence and strong performance with just 50K text-image pairs. We validate its effectiveness across diverse metrics and analyze how refined noise can eliminate the need for guidance. See our project page: https://cvlab-kaist.github.io/NoiseRefine/.
BurstM: Deep Burst Multi-scale SR using Fourier Space with Optical Flow
Sep 21, 2024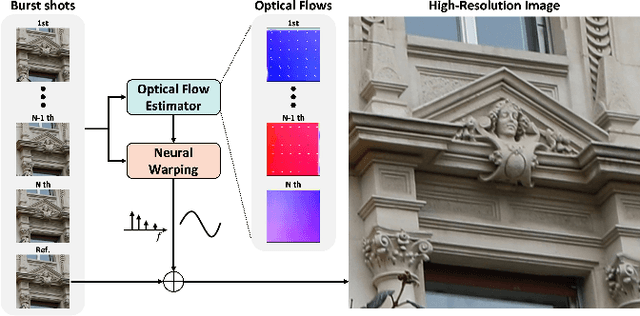
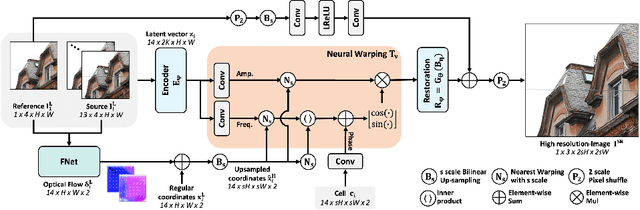
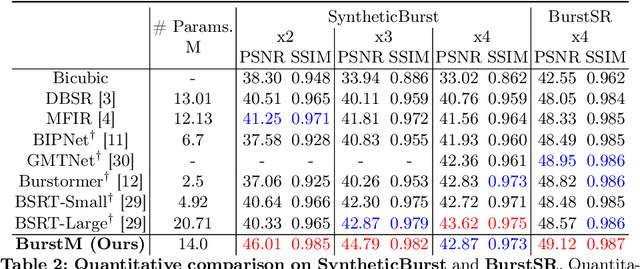
Multi frame super-resolution(MFSR) achieves higher performance than single image super-resolution (SISR), because MFSR leverages abundant information from multiple frames. Recent MFSR approaches adapt the deformable convolution network (DCN) to align the frames. However, the existing MFSR suffers from misalignments between the reference and source frames due to the limitations of DCN, such as small receptive fields and the predefined number of kernels. From these problems, existing MFSR approaches struggle to represent high-frequency information. To this end, we propose Deep Burst Multi-scale SR using Fourier Space with Optical Flow (BurstM). The proposed method estimates the optical flow offset for accurate alignment and predicts the continuous Fourier coefficient of each frame for representing high-frequency textures. In addition, we have enhanced the network flexibility by supporting various super-resolution (SR) scale factors with the unimodel. We demonstrate that our method has the highest performance and flexibility than the existing MFSR methods. Our source code is available at https://github.com/Egkang-Luis/burstm
JDEC: JPEG Decoding via Enhanced Continuous Cosine Coefficients
Apr 03, 2024



We propose a practical approach to JPEG image decoding, utilizing a local implicit neural representation with continuous cosine formulation. The JPEG algorithm significantly quantizes discrete cosine transform (DCT) spectra to achieve a high compression rate, inevitably resulting in quality degradation while encoding an image. We have designed a continuous cosine spectrum estimator to address the quality degradation issue that restores the distorted spectrum. By leveraging local DCT formulations, our network has the privilege to exploit dequantization and upsampling simultaneously. Our proposed model enables decoding compressed images directly across different quality factors using a single pre-trained model without relying on a conventional JPEG decoder. As a result, our proposed network achieves state-of-the-art performance in flexible color image JPEG artifact removal tasks. Our source code is available at https://github.com/WooKyoungHan/JDEC.
Self-Rectifying Diffusion Sampling with Perturbed-Attention Guidance
Mar 26, 2024



Recent studies have demonstrated that diffusion models are capable of generating high-quality samples, but their quality heavily depends on sampling guidance techniques, such as classifier guidance (CG) and classifier-free guidance (CFG). These techniques are often not applicable in unconditional generation or in various downstream tasks such as image restoration. In this paper, we propose a novel sampling guidance, called Perturbed-Attention Guidance (PAG), which improves diffusion sample quality across both unconditional and conditional settings, achieving this without requiring additional training or the integration of external modules. PAG is designed to progressively enhance the structure of samples throughout the denoising process. It involves generating intermediate samples with degraded structure by substituting selected self-attention maps in diffusion U-Net with an identity matrix, by considering the self-attention mechanisms' ability to capture structural information, and guiding the denoising process away from these degraded samples. In both ADM and Stable Diffusion, PAG surprisingly improves sample quality in conditional and even unconditional scenarios. Moreover, PAG significantly improves the baseline performance in various downstream tasks where existing guidances such as CG or CFG cannot be fully utilized, including ControlNet with empty prompts and image restoration such as inpainting and deblurring.
BroadBEV: Collaborative LiDAR-camera Fusion for Broad-sighted Bird's Eye View Map Construction
Sep 25, 2023A recent sensor fusion in a Bird's Eye View (BEV) space has shown its utility in various tasks such as 3D detection, map segmentation, etc. However, the approach struggles with inaccurate camera BEV estimation, and a perception of distant areas due to the sparsity of LiDAR points. In this paper, we propose a broad BEV fusion (BroadBEV) that addresses the problems with a spatial synchronization approach of cross-modality. Our strategy aims to enhance camera BEV estimation for a broad-sighted perception while simultaneously improving the completion of LiDAR's sparsity in the entire BEV space. Toward that end, we devise Point-scattering that scatters LiDAR BEV distribution to camera depth distribution. The method boosts the learning of depth estimation of the camera branch and induces accurate location of dense camera features in BEV space. For an effective BEV fusion between the spatially synchronized features, we suggest ColFusion that applies self-attention weights of LiDAR and camera BEV features to each other. Our extensive experiments demonstrate that BroadBEV provides a broad-sighted BEV perception with remarkable performance gains.
Implicit Neural Image Stitching With Enhanced and Blended Feature Reconstruction
Sep 12, 2023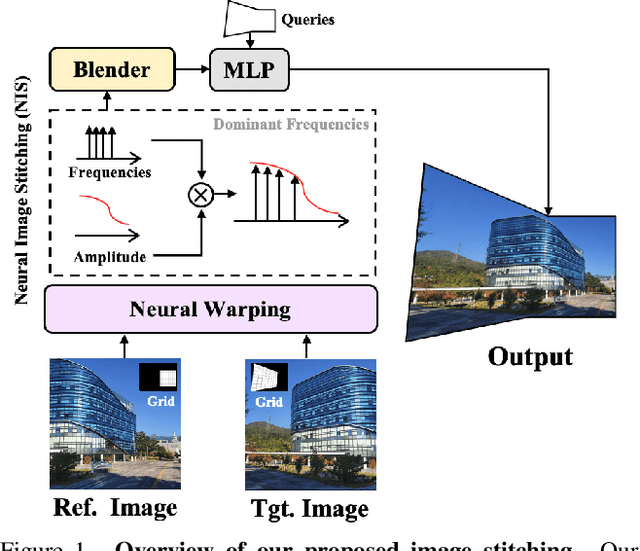
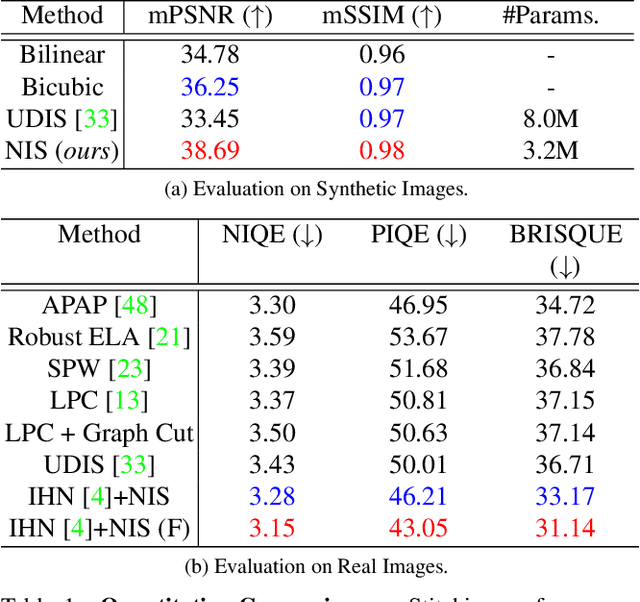

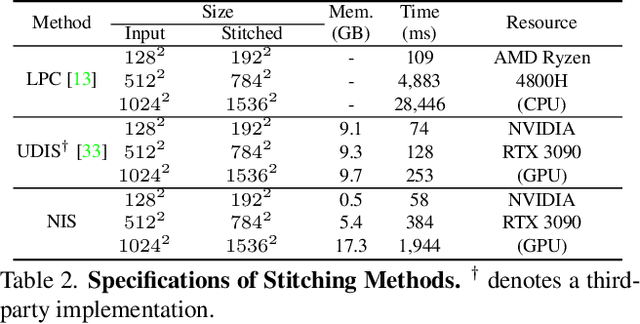
Existing frameworks for image stitching often provide visually reasonable stitchings. However, they suffer from blurry artifacts and disparities in illumination, depth level, etc. Although the recent learning-based stitchings relax such disparities, the required methods impose sacrifice of image qualities failing to capture high-frequency details for stitched images. To address the problem, we propose a novel approach, implicit Neural Image Stitching (NIS) that extends arbitrary-scale super-resolution. Our method estimates Fourier coefficients of images for quality-enhancing warps. Then, the suggested model blends color mismatches and misalignment in the latent space and decodes the features into RGB values of stitched images. Our experiments show that our approach achieves improvement in resolving the low-definition imaging of the previous deep image stitching with favorable accelerated image-enhancing methods. Our source code is available at https://github.com/minshu-kim/NIS.