 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Noise is Worth Diffusion Guidance
Dec 05, 2024
Diffusion models excel in generating high-quality images. However, current diffusion models struggle to produce reliable images without guidance methods, such as classifier-free guidance (CFG). Are guidance methods truly necessary? Observing that noise obtained via diffusion inversion can reconstruct high-quality images without guidance, we focus on the initial noise of the denoising pipeline. By mapping Gaussian noise to `guidance-free noise', we uncover that small low-magnitude low-frequency components significantly enhance the denoising process, removing the need for guidance and thus improving both inference throughput and memory. Expanding on this, we propose \ours, a novel method that replaces guidance methods with a single refinement of the initial noise. This refined noise enables high-quality image generation without guidance, within the same diffusion pipeline. Our noise-refining model leverages efficient noise-space learning, achieving rapid convergence and strong performance with just 50K text-image pairs. We validate its effectiveness across diverse metrics and analyze how refined noise can eliminate the need for guidance. See our project page: https://cvlab-kaist.github.io/NoiseRefine/.
Self-Rectifying Diffusion Sampling with Perturbed-Attention Guidance
Mar 26, 2024



Recent studies have demonstrated that diffusion models are capable of generating high-quality samples, but their quality heavily depends on sampling guidance techniques, such as classifier guidance (CG) and classifier-free guidance (CFG). These techniques are often not applicable in unconditional generation or in various downstream tasks such as image restoration. In this paper, we propose a novel sampling guidance, called Perturbed-Attention Guidance (PAG), which improves diffusion sample quality across both unconditional and conditional settings, achieving this without requiring additional training or the integration of external modules. PAG is designed to progressively enhance the structure of samples throughout the denoising process. It involves generating intermediate samples with degraded structure by substituting selected self-attention maps in diffusion U-Net with an identity matrix, by considering the self-attention mechanisms' ability to capture structural information, and guiding the denoising process away from these degraded samples. In both ADM and Stable Diffusion, PAG surprisingly improves sample quality in conditional and even unconditional scenarios. Moreover, PAG significantly improves the baseline performance in various downstream tasks where existing guidances such as CG or CFG cannot be fully utilized, including ControlNet with empty prompts and image restoration such as inpainting and deblurring.
DiffMatch: Diffusion Model for Dense Matching
May 30, 2023

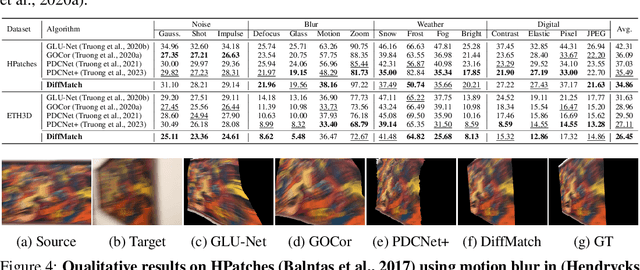
The objective for establishing dense correspondence between paired images consists of two terms: a data term and a prior term. While conventional techniques focused on defining hand-designed prior terms, which are difficult to formulate, recent approaches have focused on learning the data term with deep neural networks without explicitly modeling the prior, assuming that the model itself has the capacity to learn an optimal prior from a large-scale dataset. The performance improvement was obvious, however, they often fail to address inherent ambiguities of matching, such as textureless regions, repetitive patterns, and large displacements. To address this, we propose DiffMatch, a novel conditional diffusion-based framework designed to explicitly model both the data and prior terms. Unlike previous approaches, this is accomplished by leveraging a conditional denoising diffusion model. DiffMatch consists of two main components: conditional denoising diffusion module and cost injection module. We stabilize the training process and reduce memory usage with a stage-wise training strategy. Furthermore, to boost performance, we introduce an inference technique that finds a better path to the accurate matching field. Our experimental results demonstrate significant performance improvements of our method over existing approaches, and the ablation studies validate our design choices along with the effectiveness of each component. Project page is available at https://ku-cvlab.github.io/DiffMatch/.