 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffMatch: Diffusion Model for Dense Matching
May 30, 2023
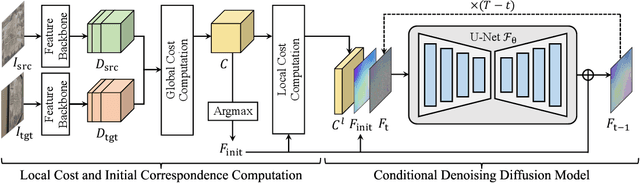

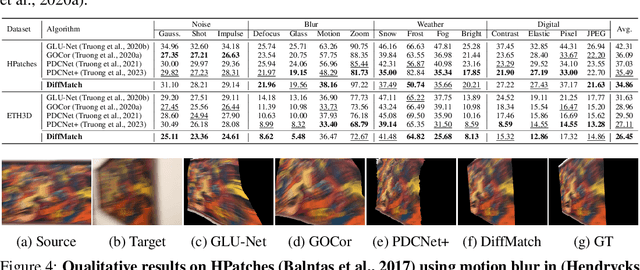
The objective for establishing dense correspondence between paired images consists of two terms: a data term and a prior term. While conventional techniques focused on defining hand-designed prior terms, which are difficult to formulate, recent approaches have focused on learning the data term with deep neural networks without explicitly modeling the prior, assuming that the model itself has the capacity to learn an optimal prior from a large-scale dataset. The performance improvement was obvious, however, they often fail to address inherent ambiguities of matching, such as textureless regions, repetitive patterns, and large displacements. To address this, we propose DiffMatch, a novel conditional diffusion-based framework designed to explicitly model both the data and prior terms. Unlike previous approaches, this is accomplished by leveraging a conditional denoising diffusion model. DiffMatch consists of two main components: conditional denoising diffusion module and cost injection module. We stabilize the training process and reduce memory usage with a stage-wise training strategy. Furthermore, to boost performance, we introduce an inference technique that finds a better path to the accurate matching field. Our experimental results demonstrate significant performance improvements of our method over existing approaches, and the ablation studies validate our design choices along with the effectiveness of each component. Project page is available at https://ku-cvlab.github.io/DiffMatch/.
Predicting quantum chemical property with easy-to-obtain geometry via positional denoising
Mar 28, 2023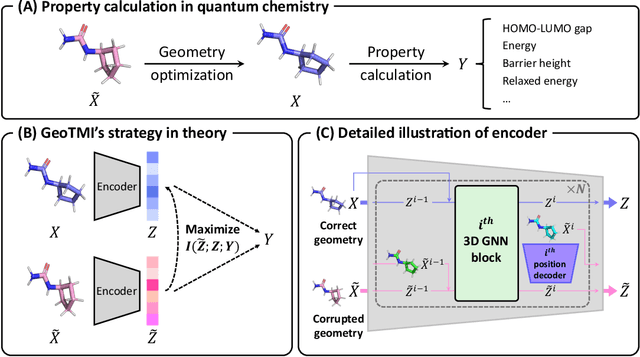
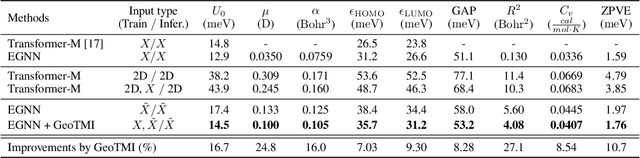
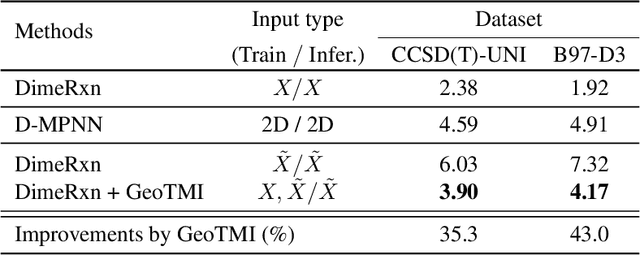
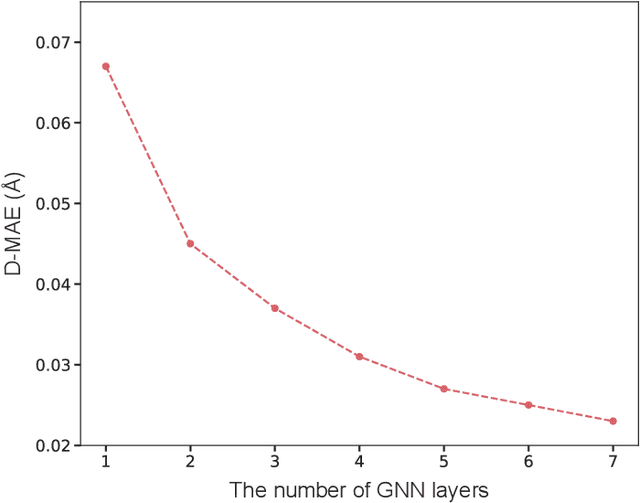
As quantum chemical properties have a significant dependence on their geometries, graph neural networks (GNNs) using 3D geometric information have achieved high prediction accuracy in many tasks. However, they often require 3D geometries obtained from high-level quantum mechanical calculations, which are practically infeasible, limiting their applicability in real-world problems. To tackle this, we propose a method to accurately predict the properties with relatively easy-to-obtain geometries (e.g., optimized geometries from the molecular force field). In this method, the input geometry, regarded as the corrupted geometry of the correct one, gradually approaches the correct one as it passes through the stacked denoising layers. We investigated the performance of the proposed method using 3D message-passing architectures for two prediction tasks: molecular properties and chemical reaction property. The reduction of positional errors through the denoising process contributed to performance improvement by increasing the mutual information between the correct and corrupted geometries. Moreover, our analysis of the correlation between denoising power and predictive accuracy demonstrates the effectiveness of the denoising process.
Let 2D Diffusion Model Know 3D-Consistency for Robust Text-to-3D Generation
Mar 16, 2023
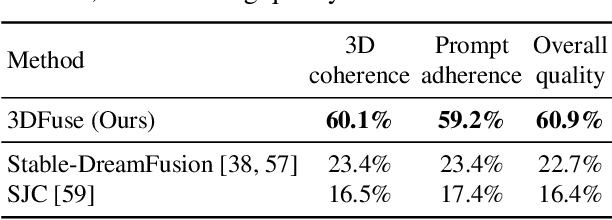
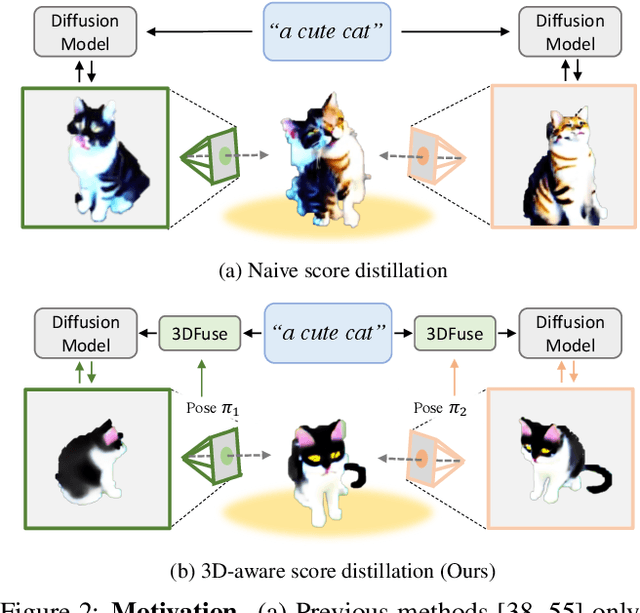
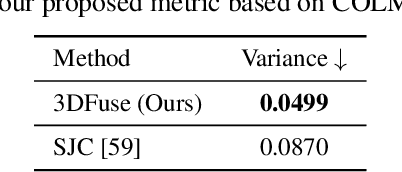
Text-to-3D generation has shown rapid progress in recent days with the advent of score distillation, a methodology of using pretrained text-to-2D diffusion models to optimize neural radiance field (NeRF) in the zero-shot setting. However, the lack of 3D awareness in the 2D diffusion models destabilizes score distillation-based methods from reconstructing a plausible 3D scene. To address this issue, we propose 3DFuse, a novel framework that incorporates 3D awareness into pretrained 2D diffusion models, enhancing the robustness and 3D consistency of score distillation-based methods. We realize this by first constructing a coarse 3D structure of a given text prompt and then utilizing projected, view-specific depth map as a condition for the diffusion model. Additionally, we introduce a training strategy that enables the 2D diffusion model learns to handle the errors and sparsity within the coarse 3D structure for robust generation, as well as a method for ensuring semantic consistency throughout all viewpoints of the scene. Our framework surpasses the limitations of prior arts, and has significant implications for 3D consistent generation of 2D diffusion models.