 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThunder-NUBench: A Benchmark for LLMs' Sentence-Level Negation Understanding
Jun 18, 2025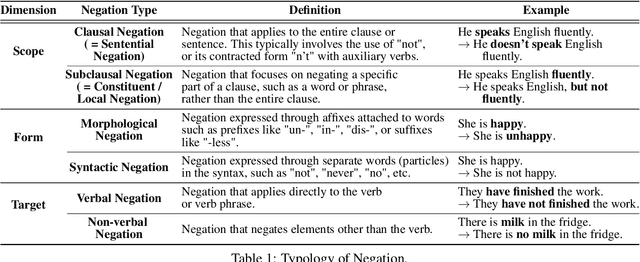
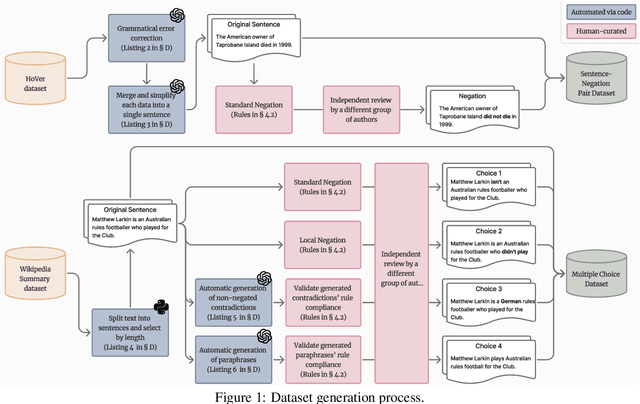
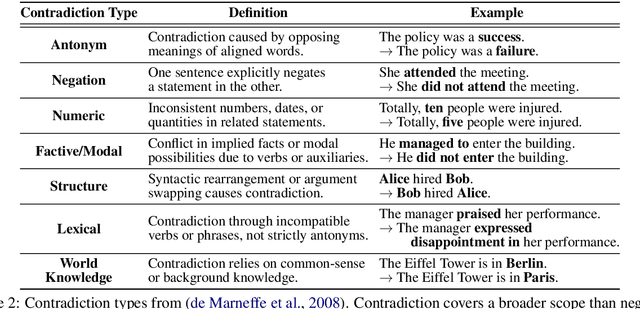

Negation is a fundamental linguistic phenomenon that poses persistent challenges for Large Language Models (LLMs), particularly in tasks requiring deep semantic understanding. Existing benchmarks often treat negation as a side case within broader tasks like natural language inference, resulting in a lack of benchmarks that exclusively target negation understanding. In this work, we introduce Thunder-NUBench, a novel benchmark explicitly designed to assess sentence-level negation understanding in LLMs. Thunder-NUBench goes beyond surface-level cue detection by contrasting standard negation with structurally diverse alternatives such as local negation, contradiction, and paraphrase. The benchmark consists of manually curated sentence-negation pairs and a multiple-choice dataset that enables in-depth evaluation of models' negation understanding.
Thunder-DeID: Accurate and Efficient De-identification Framework for Korean Court Judgments
Jun 18, 2025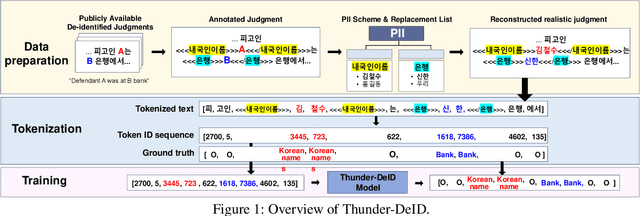
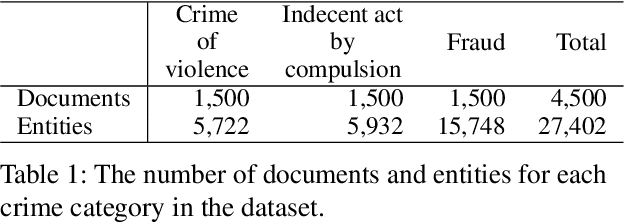
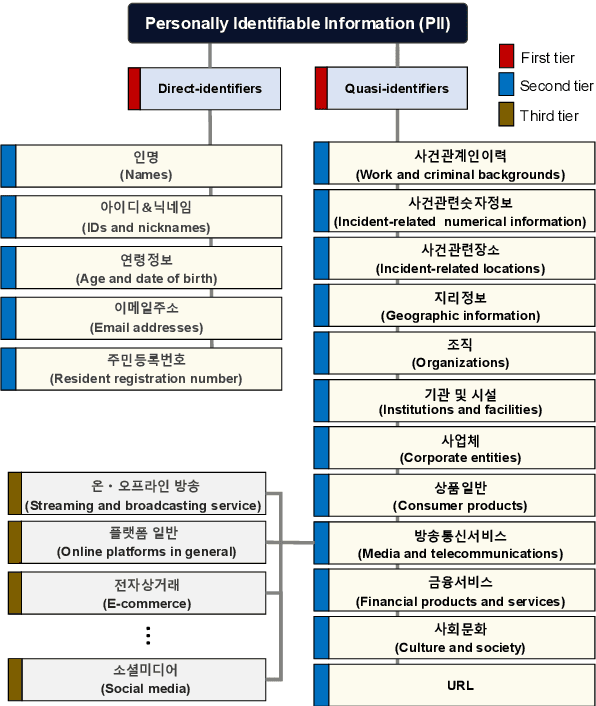
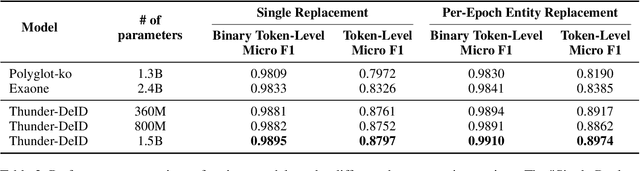
To ensure a balance between open access to justice and personal data protection, the South Korean judiciary mandates the de-identification of court judgments before they can be publicly disclosed. However, the current de-identification process is inadequate for handling court judgments at scale while adhering to strict legal requirements. Additionally, the legal definitions and categorizations of personal identifiers are vague and not well-suited for technical solutions. To tackle these challenges, we propose a de-identification framework called Thunder-DeID, which aligns with relevant laws and practices. Specifically, we (i) construct and release the first Korean legal dataset containing annotated judgments along with corresponding lists of entity mentions, (ii) introduce a systematic categorization of Personally Identifiable Information (PII), and (iii) develop an end-to-end deep neural network (DNN)-based de-identification pipeline. Our experimental results demonstrate that our model achieves state-of-the-art performance in the de-identification of court judgments.
Domain Generalization Using Large Pretrained Models with Mixture-of-Adapters
Oct 17, 2023



Learning a robust vision model despite large distribution shift is essential for model deployment in real-world settings. Especially, domain generalization (DG) algorithm aims to maintain the performance of a trained model on different distributions which were not seen during training. One of the most effective methods has been leveraging the already learned rich knowledge of large pretrained models. However, naively fine-tuning large models to DG tasks is often practically infeasible due to memory limitations, extensive time requirements for training, and the risk of learned knowledge deterioration. Recently, parameter-efficient fine-tuning (PEFT) methods have been proposed to reduce the high computational cost during training and efficiently adapt large models to downstream tasks. In this work, for the first time, we find that the use of adapters in PEFT methods not only reduce high computational cost during training but also serve as an effective regularizer for DG tasks. Surprisingly, a naive adapter implementation for large models achieve superior performance on common datasets. However, in situations of large distribution shifts, additional factors such as optimal amount of regularization due to the strength of distribution shifts should be considered for a sophisticated adapter implementation. To address this, we propose a mixture-of-expert based adapter fine-tuning method, dubbed as mixture-of-adapters (MoA). Specifically, we employ multiple adapters that have varying capacities, and by using learnable routers, we allocate each token to a proper adapter. By using both PEFT and MoA methods, we effectively alleviate the performance deterioration caused by distribution shifts and achieve state-of-the-art performance on diverse DG benchmarks.
DiffMatch: Diffusion Model for Dense Matching
May 30, 2023
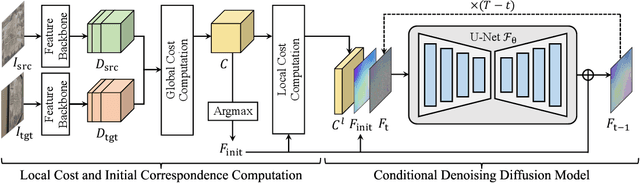

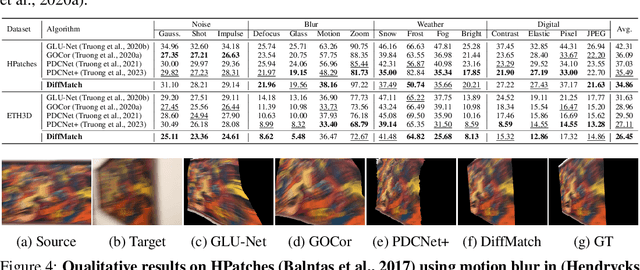
The objective for establishing dense correspondence between paired images consists of two terms: a data term and a prior term. While conventional techniques focused on defining hand-designed prior terms, which are difficult to formulate, recent approaches have focused on learning the data term with deep neural networks without explicitly modeling the prior, assuming that the model itself has the capacity to learn an optimal prior from a large-scale dataset. The performance improvement was obvious, however, they often fail to address inherent ambiguities of matching, such as textureless regions, repetitive patterns, and large displacements. To address this, we propose DiffMatch, a novel conditional diffusion-based framework designed to explicitly model both the data and prior terms. Unlike previous approaches, this is accomplished by leveraging a conditional denoising diffusion model. DiffMatch consists of two main components: conditional denoising diffusion module and cost injection module. We stabilize the training process and reduce memory usage with a stage-wise training strategy. Furthermore, to boost performance, we introduce an inference technique that finds a better path to the accurate matching field. Our experimental results demonstrate significant performance improvements of our method over existing approaches, and the ablation studies validate our design choices along with the effectiveness of each component. Project page is available at https://ku-cvlab.github.io/DiffMatch/.
DAG: Depth-Aware Guidance with Denoising Diffusion Probabilistic Models
Dec 17, 2022



In recent years, generative models have undergone significant advancement due to the success of diffusion models. The success of these models is often attributed to their use of guidance techniques, such as classifier and classifier-free methods, which provides effective mechanisms to trade-off between fidelity and diversity. However, these methods are not capable of guiding a generated image to be aware of its geometric configuration, e.g., depth, which hinders the application of diffusion models to areas that require a certain level of depth awareness. To address this limitation, we propose a novel guidance approach for diffusion models that uses estimated depth information derived from the rich intermediate representations of diffusion models. To do this, we first present a label-efficient depth estimation framework using the internal representations of diffusion models. At the sampling phase, we utilize two guidance techniques to self-condition the generated image using the estimated depth map, the first of which uses pseudo-labeling, and the subsequent one uses a depth-domain diffusion prior. Experiments and extensive ablation studies demonstrate the effectiveness of our method in guiding the diffusion models toward geometrically plausible image generation. Project page is available at https://ku-cvlab.github.io/DAG/.
Improving Sample Quality of Diffusion Models Using Self-Attention Guidance
Oct 04, 2022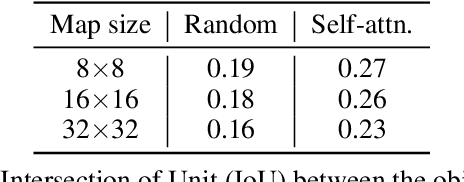
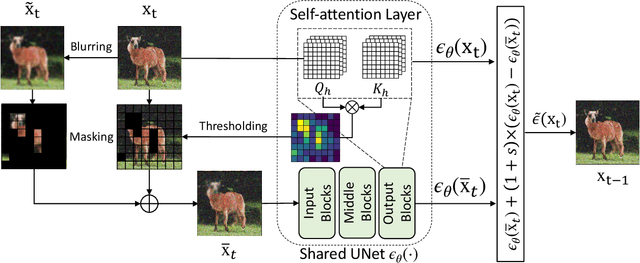
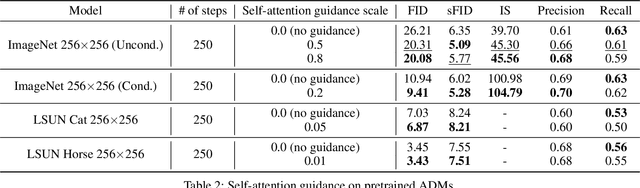

Following generative adversarial networks (GANs), a de facto standard model for image generation, denoising diffusion models (DDMs) have been actively researched and attracted strong attention due to their capability to generate images with high quality and diversity. However, the way the internal self-attention mechanism works inside the UNet of DDMs is under-explored. To unveil them, in this paper, we first investigate the self-attention operations within the black-boxed diffusion models and build hypotheses. Next, we verify the hypotheses about the self-attention map by conducting frequency analysis and testing the relationships with the generated objects. In consequence, we find out that the attention map is closely related to the quality of generated images. On the other hand, diffusion guidance methods based on additional information such as labels are proposed to improve the quality of generated images. Inspired by these methods, we present label-free guidance based on the intermediate self-attention map that can guide existing pretrained diffusion models to generate images with higher fidelity. In addition to the enhanced sample quality when used alone, we show that the results are further improved by combining our method with classifier guidance on ImageNet 128x128.
Towards Flexible Inductive Bias via Progressive Reparameterization Scheduling
Oct 04, 2022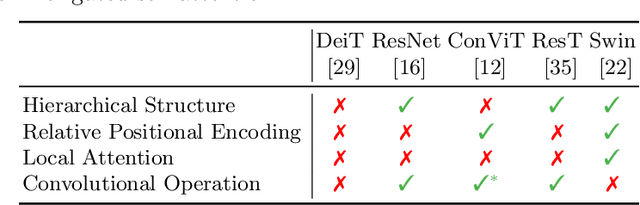
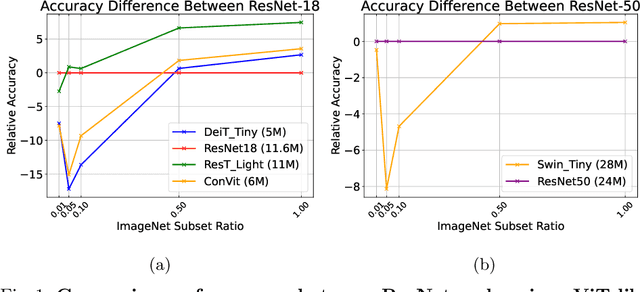
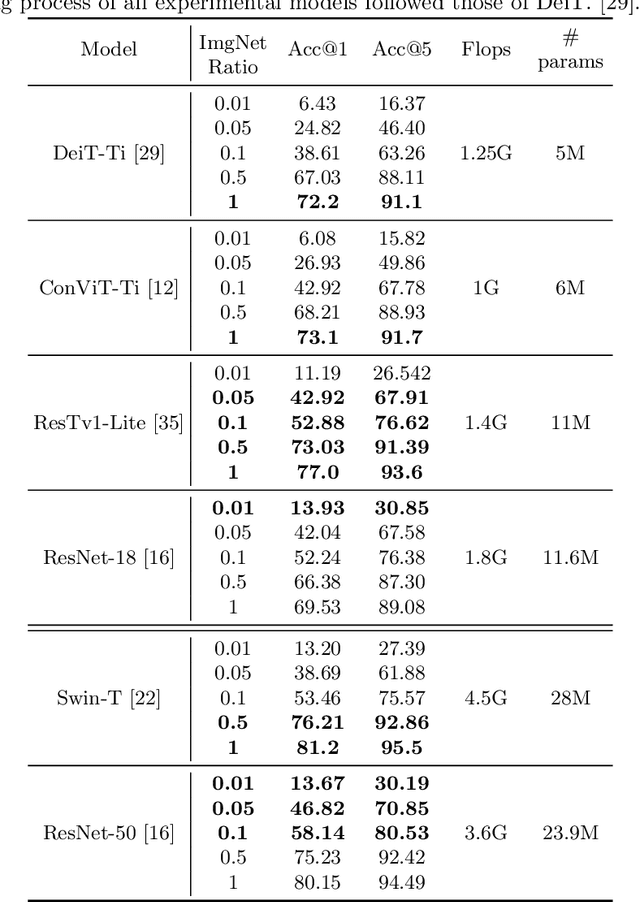
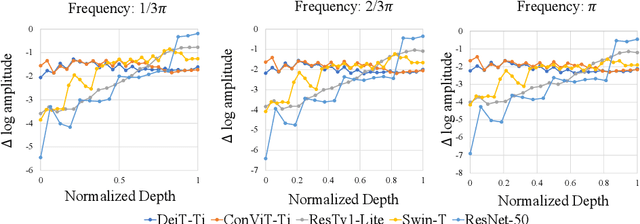
There are two de facto standard architectures in recent computer vision: Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs). Strong inductive biases of convolutions help the model learn sample effectively, but such strong biases also limit the upper bound of CNNs when sufficient data are available. On the contrary, ViT is inferior to CNNs for small data but superior for sufficient data. Recent approaches attempt to combine the strengths of these two architectures. However, we show these approaches overlook that the optimal inductive bias also changes according to the target data scale changes by comparing various models' accuracy on subsets of sampled ImageNet at different ratios. In addition, through Fourier analysis of feature maps, the model's response patterns according to signal frequency changes, we observe which inductive bias is advantageous for each data scale. The more convolution-like inductive bias is included in the model, the smaller the data scale is required where the ViT-like model outperforms the ResNet performance. To obtain a model with flexible inductive bias on the data scale, we show reparameterization can interpolate inductive bias between convolution and self-attention. By adjusting the number of epochs the model stays in the convolution, we show that reparameterization from convolution to self-attention interpolates the Fourier analysis pattern between CNNs and ViTs. Adapting these findings, we propose Progressive Reparameterization Scheduling (PRS), in which reparameterization adjusts the required amount of convolution-like or self-attention-like inductive bias per layer. For small-scale datasets, our PRS performs reparameterization from convolution to self-attention linearly faster at the late stage layer. PRS outperformed previous studies on the small-scale dataset, e.g., CIFAR-100.
MIDMs: Matching Interleaved Diffusion Models for Exemplar-based Image Translation
Sep 23, 2022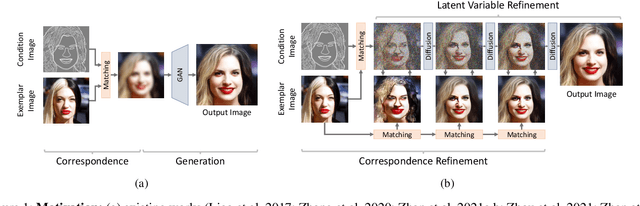
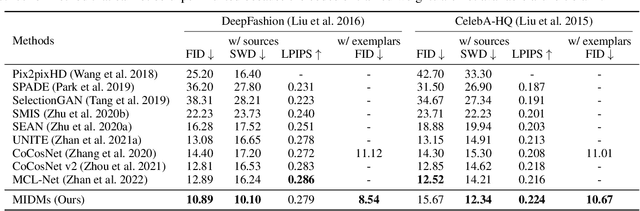
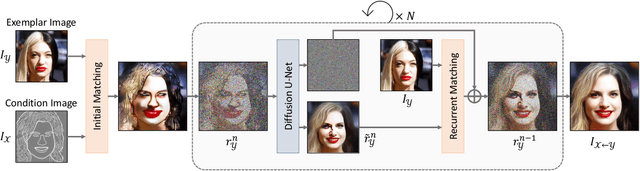
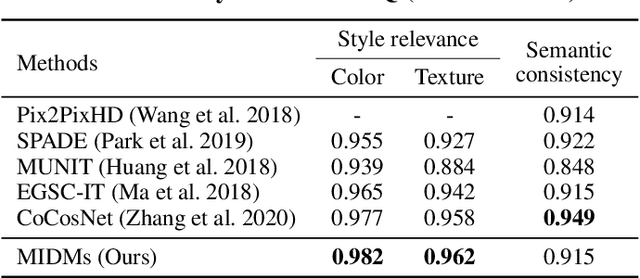
We present a novel method for exemplar-based image translation, called matching interleaved diffusion models (MIDMs). Most existing methods for this task were formulated as GAN-based matching-then-generation framework. However, in this framework, matching errors induced by the difficulty of semantic matching across cross-domain, e.g., sketch and photo, can be easily propagated to the generation step, which in turn leads to degenerated results. Motivated by the recent success of diffusion models overcoming the shortcomings of GANs, we incorporate the diffusion models to overcome these limitations. Specifically, we formulate a diffusion-based matching-and-generation framework that interleaves cross-domain matching and diffusion steps in the latent space by iteratively feeding the intermediate warp into the noising process and denoising it to generate a translated image. In addition, to improve the reliability of the diffusion process, we design a confidence-aware process using cycle-consistency to consider only confident regions during translation. Experimental results show that our MIDMs generate more plausible images than state-of-the-art methods.
ConMatch: Semi-Supervised Learning with Confidence-Guided Consistency Regularization
Aug 18, 2022
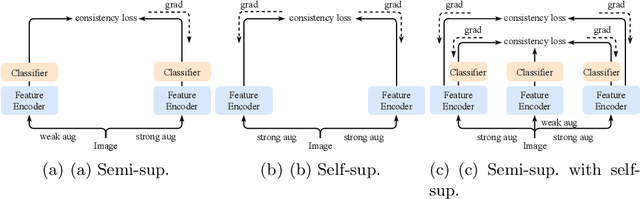
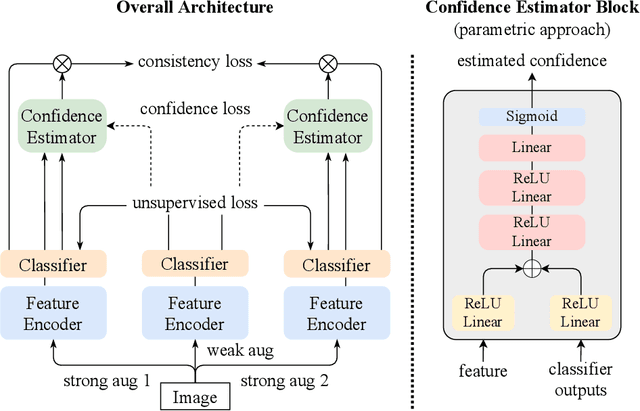
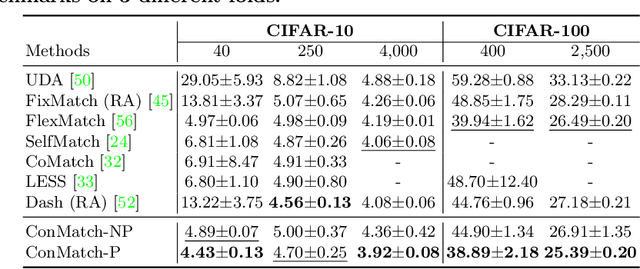
We present a novel semi-supervised learning framework that intelligently leverages the consistency regularization between the model's predictions from two strongly-augmented views of an image, weighted by a confidence of pseudo-label, dubbed ConMatch. While the latest semi-supervised learning methods use weakly- and strongly-augmented views of an image to define a directional consistency loss, how to define such direction for the consistency regularization between two strongly-augmented views remains unexplored. To account for this, we present novel confidence measures for pseudo-labels from strongly-augmented views by means of weakly-augmented view as an anchor in non-parametric and parametric approaches. Especially, in parametric approach, we present, for the first time, to learn the confidence of pseudo-label within the networks, which is learned with backbone model in an end-to-end manner. In addition, we also present a stage-wise training to boost the convergence of training. When incorporated in existing semi-supervised learners, ConMatch consistently boosts the performance. We conduct experiments to demonstrate the effectiveness of our ConMatch over the latest methods and provide extensive ablation studies. Code has been made publicly available at https://github.com/JiwonCocoder/ConMatch.
Semi-Supervised Learning of Semantic Correspondence with Pseudo-Labels
Apr 05, 2022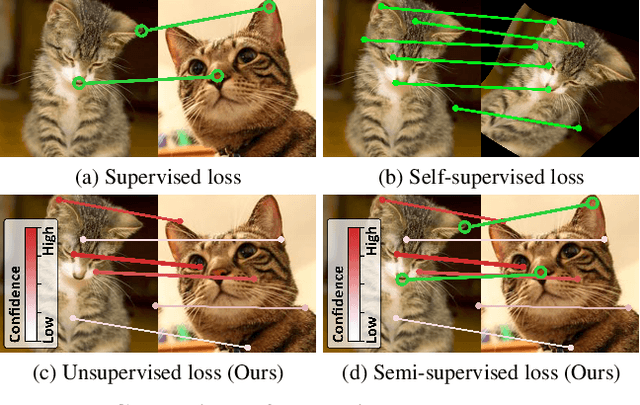
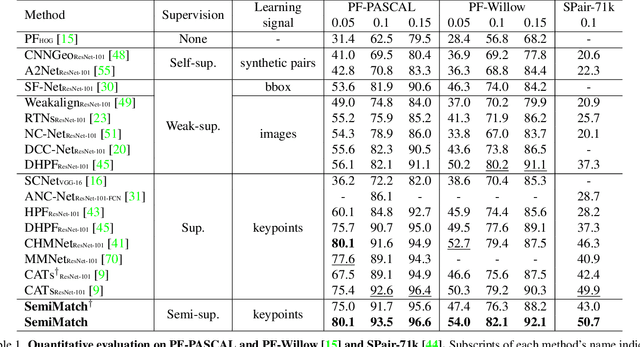
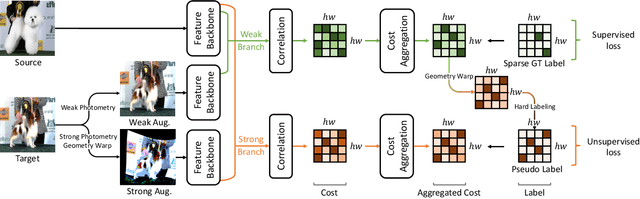
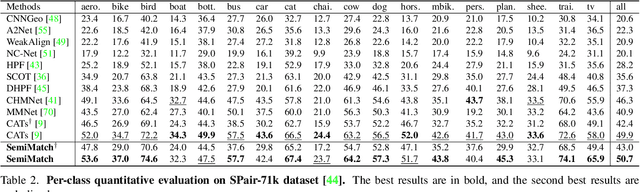
Establishing dense correspondences across semantically similar images remains a challenging task due to the significant intra-class variations and background clutters. Traditionally, a supervised learning was used for training the models, which required tremendous manually-labeled data, while some methods suggested a self-supervised or weakly-supervised learning to mitigate the reliance on the labeled data, but with limited performance. In this paper, we present a simple, but effective solution for semantic correspondence that learns the networks in a semi-supervised manner by supplementing few ground-truth correspondences via utilization of a large amount of confident correspondences as pseudo-labels, called SemiMatch. Specifically, our framework generates the pseudo-labels using the model's prediction itself between source and weakly-augmented target, and uses pseudo-labels to learn the model again between source and strongly-augmented target, which improves the robustness of the model. We also present a novel confidence measure for pseudo-labels and data augmentation tailored for semantic correspondence. In experiments, SemiMatch achieves state-of-the-art performance on various benchmarks, especially on PF-Willow by a large margin.