 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Diffusion Transformer for High-fidelity Text-Aware Image Restoration
Dec 09, 2025Text-Aware Image Restoration (TAIR) aims to recover high-quality images from low-quality inputs containing degraded textual content. While diffusion models provide strong generative priors for general image restoration, they often produce text hallucinations in text-centric tasks due to the absence of explicit linguistic knowledge. To address this, we propose UniT, a unified text restoration framework that integrates a Diffusion Transformer (DiT), a Vision-Language Model (VLM), and a Text Spotting Module (TSM) in an iterative fashion for high-fidelity text restoration. In UniT, the VLM extracts textual content from degraded images to provide explicit textual guidance. Simultaneously, the TSM, trained on diffusion features, generates intermediate OCR predictions at each denoising step, enabling the VLM to iteratively refine its guidance during the denoising process. Finally, the DiT backbone, leveraging its strong representational power, exploit these cues to recover fine-grained textual content while effectively suppressing text hallucinations. Experiments on the SA-Text and Real-Text benchmarks demonstrate that UniT faithfully reconstructs degraded text, substantially reduces hallucinations, and achieves state-of-the-art end-to-end F1-score performance in TAIR task.
Text-Aware Image Restoration with Diffusion Models
Jun 11, 2025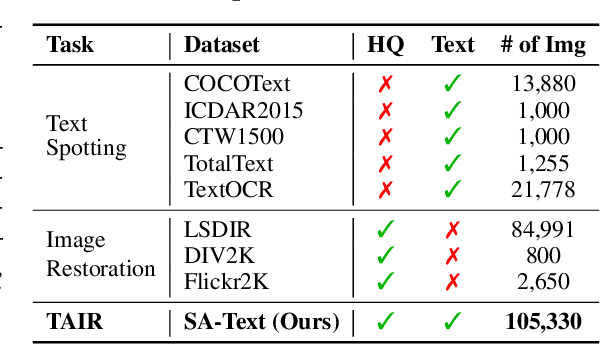
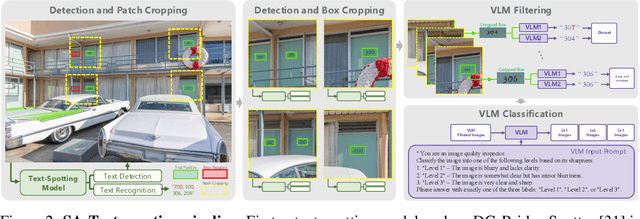
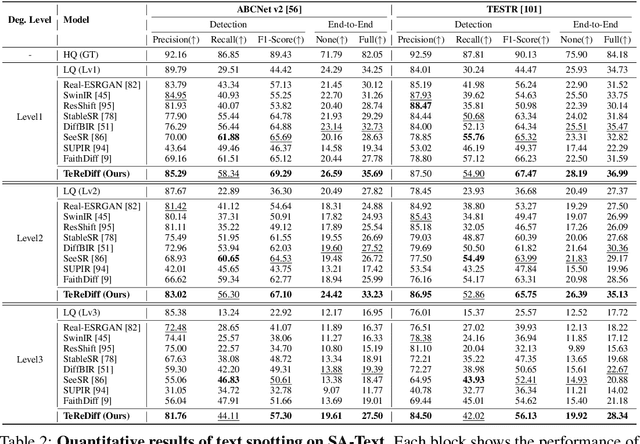

Image restoration aims to recover degraded images. However, existing diffusion-based restoration methods, despite great success in natural image restoration, often struggle to faithfully reconstruct textual regions in degraded images. Those methods frequently generate plausible but incorrect text-like patterns, a phenomenon we refer to as text-image hallucination. In this paper, we introduce Text-Aware Image Restoration (TAIR), a novel restoration task that requires the simultaneous recovery of visual contents and textual fidelity. To tackle this task, we present SA-Text, a large-scale benchmark of 100K high-quality scene images densely annotated with diverse and complex text instances. Furthermore, we propose a multi-task diffusion framework, called TeReDiff, that integrates internal features from diffusion models into a text-spotting module, enabling both components to benefit from joint training. This allows for the extraction of rich text representations, which are utilized as prompts in subsequent denoising steps. Extensive experiments demonstrate that our approach consistently outperforms state-of-the-art restoration methods, achieving significant gains in text recognition accuracy. See our project page: https://cvlab-kaist.github.io/TAIR/
Domain Generalization Using Large Pretrained Models with Mixture-of-Adapters
Oct 17, 2023



Learning a robust vision model despite large distribution shift is essential for model deployment in real-world settings. Especially, domain generalization (DG) algorithm aims to maintain the performance of a trained model on different distributions which were not seen during training. One of the most effective methods has been leveraging the already learned rich knowledge of large pretrained models. However, naively fine-tuning large models to DG tasks is often practically infeasible due to memory limitations, extensive time requirements for training, and the risk of learned knowledge deterioration. Recently, parameter-efficient fine-tuning (PEFT) methods have been proposed to reduce the high computational cost during training and efficiently adapt large models to downstream tasks. In this work, for the first time, we find that the use of adapters in PEFT methods not only reduce high computational cost during training but also serve as an effective regularizer for DG tasks. Surprisingly, a naive adapter implementation for large models achieve superior performance on common datasets. However, in situations of large distribution shifts, additional factors such as optimal amount of regularization due to the strength of distribution shifts should be considered for a sophisticated adapter implementation. To address this, we propose a mixture-of-expert based adapter fine-tuning method, dubbed as mixture-of-adapters (MoA). Specifically, we employ multiple adapters that have varying capacities, and by using learnable routers, we allocate each token to a proper adapter. By using both PEFT and MoA methods, we effectively alleviate the performance deterioration caused by distribution shifts and achieve state-of-the-art performance on diverse DG benchmarks.