 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy-Gradient Grounding: Training-Free Evidence Retrieval in Vision-Language Models
Apr 09, 2026Despite rapid progress, pretrained vision-language models still struggle when answers depend on tiny visual details or on combining clues spread across multiple regions, as in documents and compositional queries. We address this by framing grounding as test-time evidence retrieval: given a query, the model should actively identify where to look next to resolve ambiguity. To this end, we propose a training-free, model-intrinsic grounding method that uses uncertainty as supervision. Specifically, we compute the entropy of the model's next-token distribution and backpropagate it to the visual token embeddings to obtain an entropy-gradient relevance map, without auxiliary detectors or attention-map heuristics. We then extract and rank multiple coherent regions to support multi-evidence queries, and introduce an iterative zoom-and-reground procedure with a spatial-entropy stopping rule to avoid over-refinement. Experiments on seven benchmarks across four VLM architectures demonstrate consistent improvements over existing methods, with the largest gains on detail-critical and high-resolution settings, while also producing more interpretable evidence localizations.
Visual Representation Alignment for Multimodal Large Language Models
Sep 09, 2025Multimodal large language models (MLLMs) trained with visual instruction tuning have achieved strong performance across diverse tasks, yet they remain limited in vision-centric tasks such as object counting or spatial reasoning. We attribute this gap to the prevailing text-only supervision paradigm, which provides only indirect guidance for the visual pathway and often leads MLLMs to discard fine-grained visual details during training. In this paper, we present VIsual Representation ALignment (VIRAL), a simple yet effective regularization strategy that aligns the internal visual representations of MLLMs with those of pre-trained vision foundation models (VFMs). By explicitly enforcing this alignment, VIRAL enables the model not only to retain critical visual details from the input vision encoder but also to complement additional visual knowledge from VFMs, thereby enhancing its ability to reason over complex visual inputs. Our experiments demonstrate consistent improvements across all tasks on widely adopted multimodal benchmarks. Furthermore, we conduct comprehensive ablation studies to validate the key design choices underlying our framework. We believe this simple finding opens up an important direction for the effective integration of visual information in training MLLMs.
Vid-CamEdit: Video Camera Trajectory Editing with Generative Rendering from Estimated Geometry
Jun 16, 2025We introduce Vid-CamEdit, a novel framework for video camera trajectory editing, enabling the re-synthesis of monocular videos along user-defined camera paths. This task is challenging due to its ill-posed nature and the limited multi-view video data for training. Traditional reconstruction methods struggle with extreme trajectory changes, and existing generative models for dynamic novel view synthesis cannot handle in-the-wild videos. Our approach consists of two steps: estimating temporally consistent geometry, and generative rendering guided by this geometry. By integrating geometric priors, the generative model focuses on synthesizing realistic details where the estimated geometry is uncertain. We eliminate the need for extensive 4D training data through a factorized fine-tuning framework that separately trains spatial and temporal components using multi-view image and video data. Our method outperforms baselines in producing plausible videos from novel camera trajectories, especially in extreme extrapolation scenarios on real-world footage.
D^2USt3R: Enhancing 3D Reconstruction with 4D Pointmaps for Dynamic Scenes
Apr 08, 2025We address the task of 3D reconstruction in dynamic scenes, where object motions degrade the quality of previous 3D pointmap regression methods, such as DUSt3R, originally designed for static 3D scene reconstruction. Although these methods provide an elegant and powerful solution in static settings, they struggle in the presence of dynamic motions that disrupt alignment based solely on camera poses. To overcome this, we propose D^2USt3R that regresses 4D pointmaps that simultaneiously capture both static and dynamic 3D scene geometry in a feed-forward manner. By explicitly incorporating both spatial and temporal aspects, our approach successfully encapsulates spatio-temporal dense correspondence to the proposed 4D pointmaps, enhancing downstream tasks. Extensive experimental evaluations demonstrate that our proposed approach consistently achieves superior reconstruction performance across various datasets featuring complex motions.
URECA: Unique Region Caption Anything
Apr 07, 2025
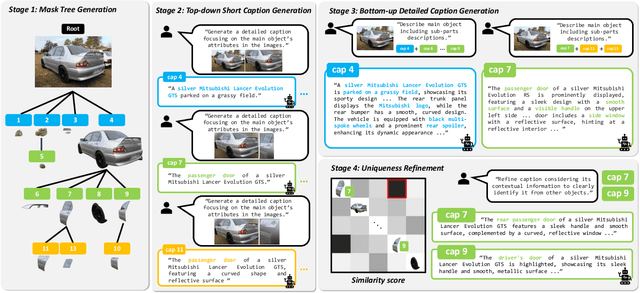
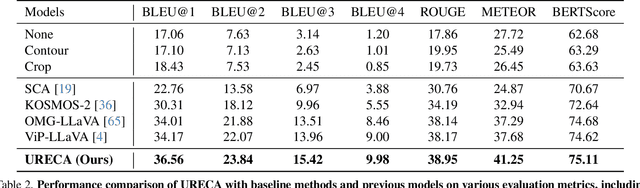
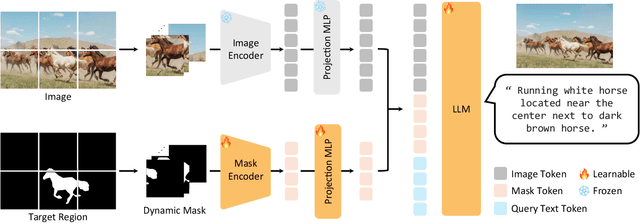
Region-level captioning aims to generate natural language descriptions for specific image regions while highlighting their distinguishing features. However, existing methods struggle to produce unique captions across multi-granularity, limiting their real-world applicability. To address the need for detailed region-level understanding, we introduce URECA dataset, a large-scale dataset tailored for multi-granularity region captioning. Unlike prior datasets that focus primarily on salient objects, URECA dataset ensures a unique and consistent mapping between regions and captions by incorporating a diverse set of objects, parts, and background elements. Central to this is a stage-wise data curation pipeline, where each stage incrementally refines region selection and caption generation. By leveraging Multimodal Large Language Models (MLLMs) at each stage, our pipeline produces distinctive and contextually grounded captions with improved accuracy and semantic diversity. Building upon this dataset, we present URECA, a novel captioning model designed to effectively encode multi-granularity regions. URECA maintains essential spatial properties such as position and shape through simple yet impactful modifications to existing MLLMs, enabling fine-grained and semantically rich region descriptions. Our approach introduces dynamic mask modeling and a high-resolution mask encoder to enhance caption uniqueness. Experiments show that URECA achieves state-of-the-art performance on URECA dataset and generalizes well to existing region-level captioning benchmarks.
Cross-View Completion Models are Zero-shot Correspondence Estimators
Dec 12, 2024In this work, we explore new perspectives on cross-view completion learning by drawing an analogy to self-supervised correspondence learning. Through our analysis, we demonstrate that the cross-attention map within cross-view completion models captures correspondence more effectively than other correlations derived from encoder or decoder features. We verify the effectiveness of the cross-attention map by evaluating on both zero-shot matching and learning-based geometric matching and multi-frame depth estimation. Project page is available at https://cvlab-kaist.github.io/ZeroCo/.
PF3plat: Pose-Free Feed-Forward 3D Gaussian Splatting
Oct 29, 2024We consider the problem of novel view synthesis from unposed images in a single feed-forward. Our framework capitalizes on fast speed, scalability, and high-quality 3D reconstruction and view synthesis capabilities of 3DGS, where we further extend it to offer a practical solution that relaxes common assumptions such as dense image views, accurate camera poses, and substantial image overlaps. We achieve this through identifying and addressing unique challenges arising from the use of pixel-aligned 3DGS: misaligned 3D Gaussians across different views induce noisy or sparse gradients that destabilize training and hinder convergence, especially when above assumptions are not met. To mitigate this, we employ pre-trained monocular depth estimation and visual correspondence models to achieve coarse alignments of 3D Gaussians. We then introduce lightweight, learnable modules to refine depth and pose estimates from the coarse alignments, improving the quality of 3D reconstruction and novel view synthesis. Furthermore, the refined estimates are leveraged to estimate geometry confidence scores, which assess the reliability of 3D Gaussian centers and condition the prediction of Gaussian parameters accordingly. Extensive evaluations on large-scale real-world datasets demonstrate that PF3plat sets a new state-of-the-art across all benchmarks, supported by comprehensive ablation studies validating our design choices.
Relaxing Accurate Initialization Constraint for 3D Gaussian Splatting
Mar 14, 2024



3D Gaussian splatting (3DGS) has recently demonstrated impressive capabilities in real-time novel view synthesis and 3D reconstruction. However, 3DGS heavily depends on the accurate initialization derived from Structure-from-Motion (SfM) methods. When trained with randomly initialized point clouds, 3DGS fails to maintain its ability to produce high-quality images, undergoing large performance drops of 4-5 dB in PSNR. Through extensive analysis of SfM initialization in the frequency domain and analysis of a 1D regression task with multiple 1D Gaussians, we propose a novel optimization strategy dubbed RAIN-GS (Relaxing Accurate Initialization Constraint for 3D Gaussian Splatting), that successfully trains 3D Gaussians from random point clouds. We show the effectiveness of our strategy through quantitative and qualitative comparisons on multiple datasets, largely improving the performance in all settings. Our project page and code can be found at https://ku-cvlab.github.io/RAIN-GS.
Unifying Correspondence, Pose and NeRF for Pose-Free Novel View Synthesis from Stereo Pairs
Dec 12, 2023



This work delves into the task of pose-free novel view synthesis from stereo pairs, a challenging and pioneering task in 3D vision. Our innovative framework, unlike any before, seamlessly integrates 2D correspondence matching, camera pose estimation, and NeRF rendering, fostering a synergistic enhancement of these tasks. We achieve this through designing an architecture that utilizes a shared representation, which serves as a foundation for enhanced 3D geometry understanding. Capitalizing on the inherent interplay between the tasks, our unified framework is trained end-to-end with the proposed training strategy to improve overall model accuracy. Through extensive evaluations across diverse indoor and outdoor scenes from two real-world datasets, we demonstrate that our approach achieves substantial improvement over previous methodologies, especially in scenarios characterized by extreme viewpoint changes and the absence of accurate camera poses.
Self-Evolving Neural Radiance Fields
Dec 05, 2023Recently, neural radiance field (NeRF) has shown remarkable performance in novel view synthesis and 3D reconstruction. However, it still requires abundant high-quality images, limiting its applicability in real-world scenarios. To overcome this limitation, recent works have focused on training NeRF only with sparse viewpoints by giving additional regularizations, often called few-shot NeRF. We observe that due to the under-constrained nature of the task, solely using additional regularization is not enough to prevent the model from overfitting to sparse viewpoints. In this paper, we propose a novel framework, dubbed Self-Evolving Neural Radiance Fields (SE-NeRF), that applies a self-training framework to NeRF to address these problems. We formulate few-shot NeRF into a teacher-student framework to guide the network to learn a more robust representation of the scene by training the student with additional pseudo labels generated from the teacher. By distilling ray-level pseudo labels using distinct distillation schemes for reliable and unreliable rays obtained with our novel reliability estimation method, we enable NeRF to learn a more accurate and robust geometry of the 3D scene. We show and evaluate that applying our self-training framework to existing models improves the quality of the rendered images and achieves state-of-the-art performance in multiple settings.