 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Source, Better Flow: Learning Condition-Dependent Source Distribution for Flow Matching
Feb 05, 2026Flow matching has recently emerged as a promising alternative to diffusion-based generative models, particularly for text-to-image generation. Despite its flexibility in allowing arbitrary source distributions, most existing approaches rely on a standard Gaussian distribution, a choice inherited from diffusion models, and rarely consider the source distribution itself as an optimization target in such settings. In this work, we show that principled design of the source distribution is not only feasible but also beneficial at the scale of modern text-to-image systems. Specifically, we propose learning a condition-dependent source distribution under flow matching objective that better exploit rich conditioning signals. We identify key failure modes that arise when directly incorporating conditioning into the source, including distributional collapse and instability, and show that appropriate variance regularization and directional alignment between source and target are critical for stable and effective learning. We further analyze how the choice of target representation space impacts flow matching with structured sources, revealing regimes in which such designs are most effective. Extensive experiments across multiple text-to-image benchmarks demonstrate consistent and robust improvements, including up to a 3x faster convergence in FID, highlighting the practical benefits of a principled source distribution design for conditional flow matching.
Visual Representation Alignment for Multimodal Large Language Models
Sep 09, 2025Multimodal large language models (MLLMs) trained with visual instruction tuning have achieved strong performance across diverse tasks, yet they remain limited in vision-centric tasks such as object counting or spatial reasoning. We attribute this gap to the prevailing text-only supervision paradigm, which provides only indirect guidance for the visual pathway and often leads MLLMs to discard fine-grained visual details during training. In this paper, we present VIsual Representation ALignment (VIRAL), a simple yet effective regularization strategy that aligns the internal visual representations of MLLMs with those of pre-trained vision foundation models (VFMs). By explicitly enforcing this alignment, VIRAL enables the model not only to retain critical visual details from the input vision encoder but also to complement additional visual knowledge from VFMs, thereby enhancing its ability to reason over complex visual inputs. Our experiments demonstrate consistent improvements across all tasks on widely adopted multimodal benchmarks. Furthermore, we conduct comprehensive ablation studies to validate the key design choices underlying our framework. We believe this simple finding opens up an important direction for the effective integration of visual information in training MLLMs.
URECA: Unique Region Caption Anything
Apr 07, 2025
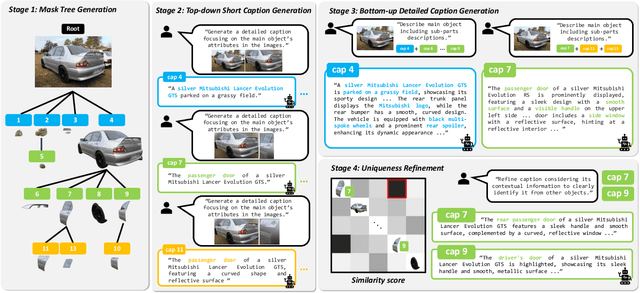
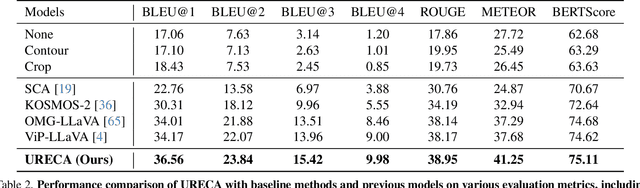
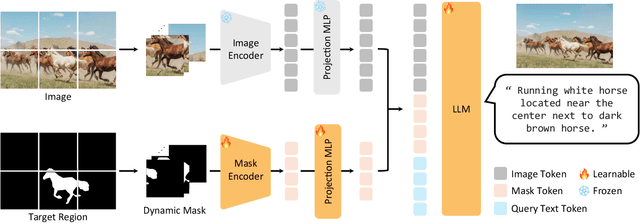
Region-level captioning aims to generate natural language descriptions for specific image regions while highlighting their distinguishing features. However, existing methods struggle to produce unique captions across multi-granularity, limiting their real-world applicability. To address the need for detailed region-level understanding, we introduce URECA dataset, a large-scale dataset tailored for multi-granularity region captioning. Unlike prior datasets that focus primarily on salient objects, URECA dataset ensures a unique and consistent mapping between regions and captions by incorporating a diverse set of objects, parts, and background elements. Central to this is a stage-wise data curation pipeline, where each stage incrementally refines region selection and caption generation. By leveraging Multimodal Large Language Models (MLLMs) at each stage, our pipeline produces distinctive and contextually grounded captions with improved accuracy and semantic diversity. Building upon this dataset, we present URECA, a novel captioning model designed to effectively encode multi-granularity regions. URECA maintains essential spatial properties such as position and shape through simple yet impactful modifications to existing MLLMs, enabling fine-grained and semantically rich region descriptions. Our approach introduces dynamic mask modeling and a high-resolution mask encoder to enhance caption uniqueness. Experiments show that URECA achieves state-of-the-art performance on URECA dataset and generalizes well to existing region-level captioning benchmarks.
DisCoRD: Discrete Tokens to Continuous Motion via Rectified Flow Decoding
Dec 02, 2024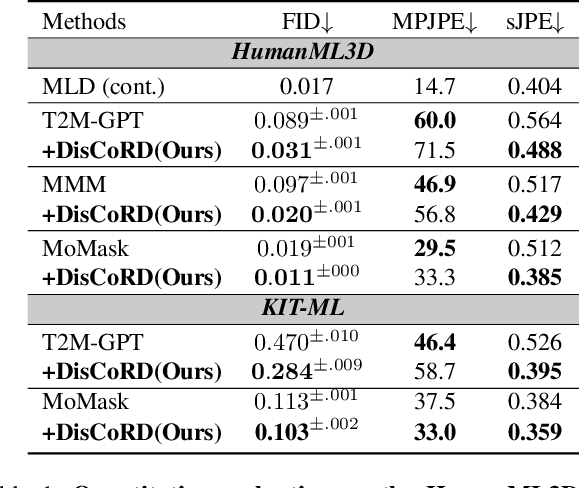
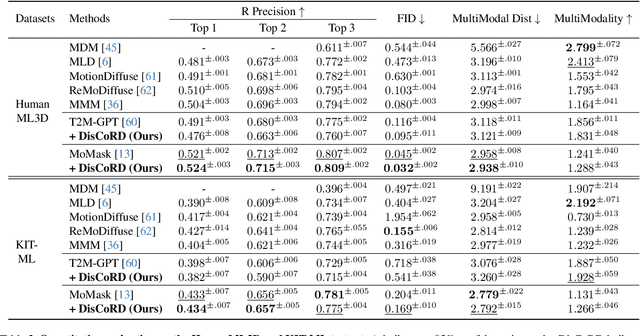
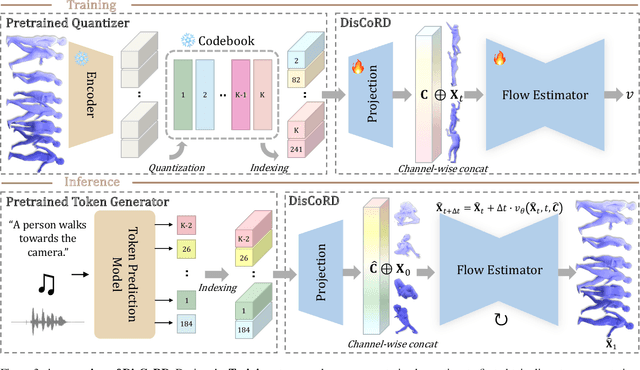
Human motion, inherently continuous and dynamic, presents significant challenges for generative models. Despite their dominance, discrete quantization methods, such as VQ-VAEs, suffer from inherent limitations, including restricted expressiveness and frame-wise noise artifacts. Continuous approaches, while producing smoother and more natural motions, often falter due to high-dimensional complexity and limited training data. To resolve this "discord" between discrete and continuous representations, we introduce DisCoRD: Discrete Tokens to Continuous Motion via Rectified Flow Decoding, a novel method that decodes discrete motion tokens into continuous motion through rectified flow. By employing an iterative refinement process in the continuous space, DisCoRD captures fine-grained dynamics and ensures smoother and more natural motions. Compatible with any discrete-based framework, our method enhances naturalness without compromising faithfulness to the conditioning signals. Extensive evaluations demonstrate that DisCoRD achieves state-of-the-art performance, with FID of 0.032 on HumanML3D and 0.169 on KIT-ML. These results solidify DisCoRD as a robust solution for bridging the divide between discrete efficiency and continuous realism. Our project page is available at: https://whwjdqls.github.io/discord.github.io/.
TWLV-I: Analysis and Insights from Holistic Evaluation on Video Foundation Models
Aug 21, 2024In this work, we discuss evaluating video foundation models in a fair and robust manner. Unlike language or image foundation models, many video foundation models are evaluated with differing parameters (such as sampling rate, number of frames, pretraining steps, etc.), making fair and robust comparisons challenging. Therefore, we present a carefully designed evaluation framework for measuring two core capabilities of video comprehension: appearance and motion understanding. Our findings reveal that existing video foundation models, whether text-supervised like UMT or InternVideo2, or self-supervised like V-JEPA, exhibit limitations in at least one of these capabilities. As an alternative, we introduce TWLV-I, a new video foundation model that constructs robust visual representations for both motion- and appearance-based videos. Based on the average top-1 accuracy of linear probing on five action recognition benchmarks, pretrained only on publicly accessible datasets, our model shows a 4.6%p improvement compared to V-JEPA (ViT-L) and a 7.7%p improvement compared to UMT (ViT-L). Even when compared to much larger models, our model demonstrates a 7.2%p improvement compared to DFN (ViT-H), a 2.7%p improvement compared to V-JEPA~(ViT-H) and a 2.8%p improvement compared to InternVideo2 (ViT-g). We provide embedding vectors obtained by TWLV-I from videos of several commonly used video benchmarks, along with evaluation source code that can directly utilize these embeddings. The code is available on "https://github.com/twelvelabs-io/video-embeddings-evaluation-framework".
Pegasus-v1 Technical Report
Apr 23, 2024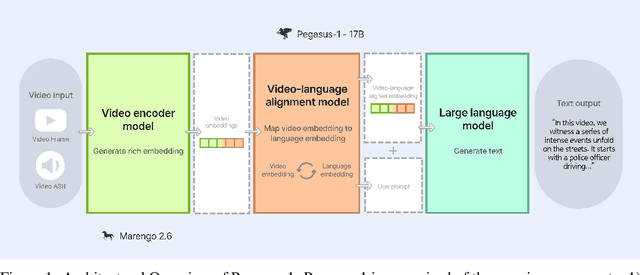
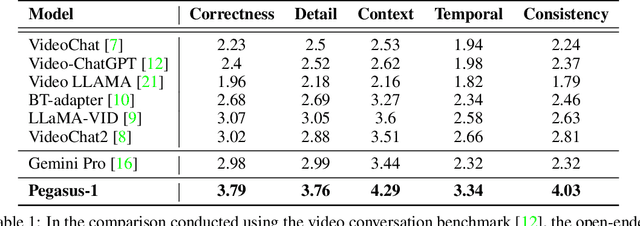


This technical report introduces Pegasus-1, a multimodal language model specialized in video content understanding and interaction through natural language. Pegasus-1 is designed to address the unique challenges posed by video data, such as interpreting spatiotemporal information, to offer nuanced video content comprehension across various lengths. This technical report overviews Pegasus-1's architecture, training strategies, and its performance in benchmarks on video conversation, zero-shot video question answering, and video summarization. We also explore qualitative characteristics of Pegasus-1 , demonstrating its capabilities as well as its limitations, in order to provide readers a balanced view of its current state and its future direction.