 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepurposing Video Diffusion Transformers for Robust Point Tracking
Dec 23, 2025Point tracking aims to localize corresponding points across video frames, serving as a fundamental task for 4D reconstruction, robotics, and video editing. Existing methods commonly rely on shallow convolutional backbones such as ResNet that process frames independently, lacking temporal coherence and producing unreliable matching costs under challenging conditions. Through systematic analysis, we find that video Diffusion Transformers (DiTs), pre-trained on large-scale real-world videos with spatio-temporal attention, inherently exhibit strong point tracking capability and robustly handle dynamic motions and frequent occlusions. We propose DiTracker, which adapts video DiTs through: (1) query-key attention matching, (2) lightweight LoRA tuning, and (3) cost fusion with a ResNet backbone. Despite training with 8 times smaller batch size, DiTracker achieves state-of-the-art performance on challenging ITTO benchmark and matches or outperforms state-of-the-art models on TAP-Vid benchmarks. Our work validates video DiT features as an effective and efficient foundation for point tracking.
Visual Representation Alignment for Multimodal Large Language Models
Sep 09, 2025Multimodal large language models (MLLMs) trained with visual instruction tuning have achieved strong performance across diverse tasks, yet they remain limited in vision-centric tasks such as object counting or spatial reasoning. We attribute this gap to the prevailing text-only supervision paradigm, which provides only indirect guidance for the visual pathway and often leads MLLMs to discard fine-grained visual details during training. In this paper, we present VIsual Representation ALignment (VIRAL), a simple yet effective regularization strategy that aligns the internal visual representations of MLLMs with those of pre-trained vision foundation models (VFMs). By explicitly enforcing this alignment, VIRAL enables the model not only to retain critical visual details from the input vision encoder but also to complement additional visual knowledge from VFMs, thereby enhancing its ability to reason over complex visual inputs. Our experiments demonstrate consistent improvements across all tasks on widely adopted multimodal benchmarks. Furthermore, we conduct comprehensive ablation studies to validate the key design choices underlying our framework. We believe this simple finding opens up an important direction for the effective integration of visual information in training MLLMs.
D^2USt3R: Enhancing 3D Reconstruction with 4D Pointmaps for Dynamic Scenes
Apr 08, 2025We address the task of 3D reconstruction in dynamic scenes, where object motions degrade the quality of previous 3D pointmap regression methods, such as DUSt3R, originally designed for static 3D scene reconstruction. Although these methods provide an elegant and powerful solution in static settings, they struggle in the presence of dynamic motions that disrupt alignment based solely on camera poses. To overcome this, we propose D^2USt3R that regresses 4D pointmaps that simultaneiously capture both static and dynamic 3D scene geometry in a feed-forward manner. By explicitly incorporating both spatial and temporal aspects, our approach successfully encapsulates spatio-temporal dense correspondence to the proposed 4D pointmaps, enhancing downstream tasks. Extensive experimental evaluations demonstrate that our proposed approach consistently achieves superior reconstruction performance across various datasets featuring complex motions.
Towards Open-Vocabulary Semantic Segmentation Without Semantic Labels
Sep 30, 2024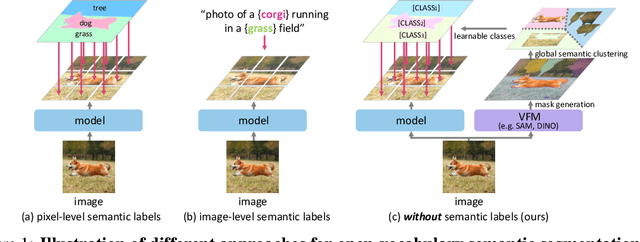
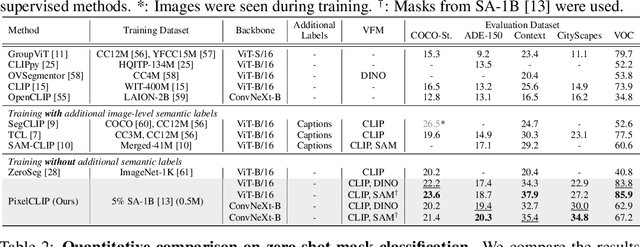

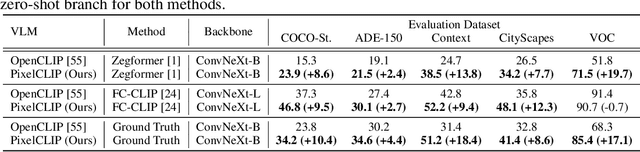
Large-scale vision-language models like CLIP have demonstrated impressive open-vocabulary capabilities for image-level tasks, excelling in recognizing what objects are present. However, they struggle with pixel-level recognition tasks like semantic segmentation, which additionally require understanding where the objects are located. In this work, we propose a novel method, PixelCLIP, to adapt the CLIP image encoder for pixel-level understanding by guiding the model on where, which is achieved using unlabeled images and masks generated from vision foundation models such as SAM and DINO. To address the challenges of leveraging masks without semantic labels, we devise an online clustering algorithm using learnable class names to acquire general semantic concepts. PixelCLIP shows significant performance improvements over CLIP and competitive results compared to caption-supervised methods in open-vocabulary semantic segmentation. Project page is available at https://cvlab-kaist.github.io/PixelCLIP