 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVid-CamEdit: Video Camera Trajectory Editing with Generative Rendering from Estimated Geometry
Jun 16, 2025We introduce Vid-CamEdit, a novel framework for video camera trajectory editing, enabling the re-synthesis of monocular videos along user-defined camera paths. This task is challenging due to its ill-posed nature and the limited multi-view video data for training. Traditional reconstruction methods struggle with extreme trajectory changes, and existing generative models for dynamic novel view synthesis cannot handle in-the-wild videos. Our approach consists of two steps: estimating temporally consistent geometry, and generative rendering guided by this geometry. By integrating geometric priors, the generative model focuses on synthesizing realistic details where the estimated geometry is uncertain. We eliminate the need for extensive 4D training data through a factorized fine-tuning framework that separately trains spatial and temporal components using multi-view image and video data. Our method outperforms baselines in producing plausible videos from novel camera trajectories, especially in extreme extrapolation scenarios on real-world footage.
D^2USt3R: Enhancing 3D Reconstruction with 4D Pointmaps for Dynamic Scenes
Apr 08, 2025We address the task of 3D reconstruction in dynamic scenes, where object motions degrade the quality of previous 3D pointmap regression methods, such as DUSt3R, originally designed for static 3D scene reconstruction. Although these methods provide an elegant and powerful solution in static settings, they struggle in the presence of dynamic motions that disrupt alignment based solely on camera poses. To overcome this, we propose D^2USt3R that regresses 4D pointmaps that simultaneiously capture both static and dynamic 3D scene geometry in a feed-forward manner. By explicitly incorporating both spatial and temporal aspects, our approach successfully encapsulates spatio-temporal dense correspondence to the proposed 4D pointmaps, enhancing downstream tasks. Extensive experimental evaluations demonstrate that our proposed approach consistently achieves superior reconstruction performance across various datasets featuring complex motions.
HumanGif: Single-View Human Diffusion with Generative Prior
Feb 17, 2025
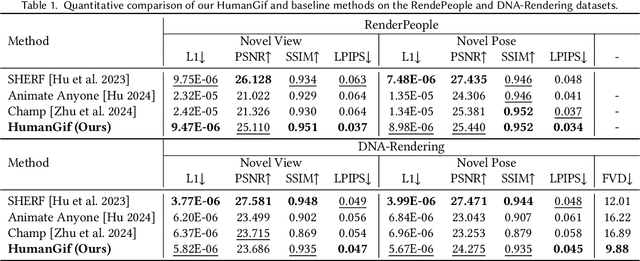
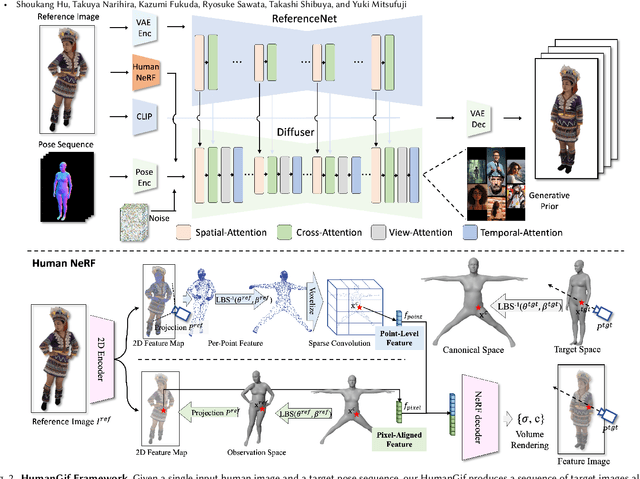

While previous single-view-based 3D human reconstruction methods made significant progress in novel view synthesis, it remains a challenge to synthesize both view-consistent and pose-consistent results for animatable human avatars from a single image input. Motivated by the success of 2D character animation, we propose <strong>HumanGif</strong>, a single-view human diffusion model with generative prior. Specifically, we formulate the single-view-based 3D human novel view and pose synthesis as a single-view-conditioned human diffusion process, utilizing generative priors from foundational diffusion models. To ensure fine-grained and consistent novel view and pose synthesis, we introduce a Human NeRF module in HumanGif to learn spatially aligned features from the input image, implicitly capturing the relative camera and human pose transformation. Furthermore, we introduce an image-level loss during optimization to bridge the gap between latent and image spaces in diffusion models. Extensive experiments on RenderPeople and DNA-Rendering datasets demonstrate that HumanGif achieves the best perceptual performance, with better generalizability for novel view and pose synthesis.
GenWarp: Single Image to Novel Views with Semantic-Preserving Generative Warping
May 27, 2024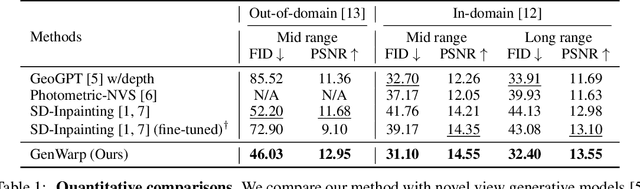
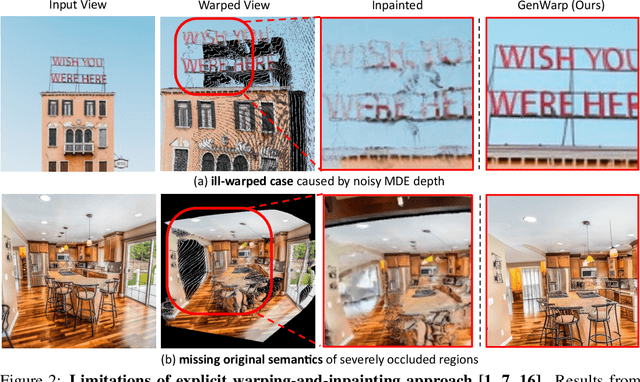

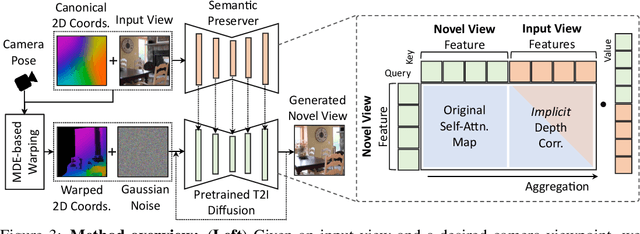
Generating novel views from a single image remains a challenging task due to the complexity of 3D scenes and the limited diversity in the existing multi-view datasets to train a model on. Recent research combining large-scale text-to-image (T2I) models with monocular depth estimation (MDE) has shown promise in handling in-the-wild images. In these methods, an input view is geometrically warped to novel views with estimated depth maps, then the warped image is inpainted by T2I models. However, they struggle with noisy depth maps and loss of semantic details when warping an input view to novel viewpoints. In this paper, we propose a novel approach for single-shot novel view synthesis, a semantic-preserving generative warping framework that enables T2I generative models to learn where to warp and where to generate, through augmenting cross-view attention with self-attention. Our approach addresses the limitations of existing methods by conditioning the generative model on source view images and incorporating geometric warping signals. Qualitative and quantitative evaluations demonstrate that our model outperforms existing methods in both in-domain and out-of-domain scenarios. Project page is available at https://GenWarp-NVS.github.io/.