 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUDA: Counterfactual Group-wise Training Data Attribution for Diffusion Models via Unlearning
Jan 30, 2026Training-data attribution for vision generative models aims to identify which training data influenced a given output. While most methods score individual examples, practitioners often need group-level answers (e.g., artistic styles or object classes). Group-wise attribution is counterfactual: how would a model's behavior on a generated sample change if a group were absent from training? A natural realization of this counterfactual is Leave-One-Group-Out (LOGO) retraining, which retrains the model with each group removed; however, it becomes computationally prohibitive as the number of groups grows. We propose GUDA (Group Unlearning-based Data Attribution) for diffusion models, which approximates each counterfactual model by applying machine unlearning to a shared full-data model instead of training from scratch. GUDA quantifies group influence using differences in a likelihood-based scoring rule (ELBO) between the full model and each unlearned counterfactual. Experiments on CIFAR-10 and artistic style attribution with Stable Diffusion show that GUDA identifies primary contributing groups more reliably than semantic similarity, gradient-based attribution, and instance-level unlearning approaches, while achieving x100 speedup on CIFAR-10 over LOGO retraining.
Improved Object-Centric Diffusion Learning with Registers and Contrastive Alignment
Jan 03, 2026Slot Attention (SA) with pretrained diffusion models has recently shown promise for object-centric learning (OCL), but suffers from slot entanglement and weak alignment between object slots and image content. We propose Contrastive Object-centric Diffusion Alignment (CODA), a simple extension that (i) employs register slots to absorb residual attention and reduce interference between object slots, and (ii) applies a contrastive alignment loss to explicitly encourage slot-image correspondence. The resulting training objective serves as a tractable surrogate for maximizing mutual information (MI) between slots and inputs, strengthening slot representation quality. On both synthetic (MOVi-C/E) and real-world datasets (VOC, COCO), CODA improves object discovery (e.g., +6.1% FG-ARI on COCO), property prediction, and compositional image generation over strong baselines. Register slots add negligible overhead, keeping CODA efficient and scalable. These results indicate potential applications of CODA as an effective framework for robust OCL in complex, real-world scenes.
SONA: Learning Conditional, Unconditional, and Mismatching-Aware Discriminator
Oct 06, 2025Deep generative models have made significant advances in generating complex content, yet conditional generation remains a fundamental challenge. Existing conditional generative adversarial networks often struggle to balance the dual objectives of assessing authenticity and conditional alignment of input samples within their conditional discriminators. To address this, we propose a novel discriminator design that integrates three key capabilities: unconditional discrimination, matching-aware supervision to enhance alignment sensitivity, and adaptive weighting to dynamically balance all objectives. Specifically, we introduce Sum of Naturalness and Alignment (SONA), which employs separate projections for naturalness (authenticity) and alignment in the final layer with an inductive bias, supported by dedicated objective functions and an adaptive weighting mechanism. Extensive experiments on class-conditional generation tasks show that \ours achieves superior sample quality and conditional alignment compared to state-of-the-art methods. Furthermore, we demonstrate its effectiveness in text-to-image generation, confirming the versatility and robustness of our approach.
Schrödinger Bridge Consistency Trajectory Models for Speech Enhancement
Jul 16, 2025Speech enhancement (SE) utilizing diffusion models is a promising technology that improves speech quality in noisy speech data. Furthermore, the Schr\"odinger bridge (SB) has recently been used in diffusion-based SE to improve speech quality by resolving a mismatch between the endpoint of the forward process and the starting point of the reverse process. However, the SB still exhibits slow inference owing to the necessity of a large number of function evaluations (NFE) for inference to obtain high-quality results. While Consistency Models (CMs) address this issue by employing consistency training that uses distillation from pretrained models in the field of image generation, it does not improve generation quality when the number of steps increases. As a solution to this problem, Consistency Trajectory Models (CTMs) not only accelerate inference speed but also maintain a favorable trade-off between quality and speed. Furthermore, SoundCTM demonstrates the applicability of CTM techniques to the field of sound generation. In this paper, we present Schr\"odinger bridge Consistency Trajectory Models (SBCTM) by applying the CTM's technique to the Schr\"odinger bridge for SE. Additionally, we introduce a novel auxiliary loss, including a perceptual loss, into the original CTM's training framework. As a result, SBCTM achieves an approximately 16x improvement in the real-time factor (RTF) compared to the conventional Schr\"odinger bridge for SE. Furthermore, the favorable trade-off between quality and speed in SBCTM allows for time-efficient inference by limiting multi-step refinement to cases where 1-step inference is insufficient. Our code, pretrained models, and audio samples are available at https://github.com/sony/sbctm/.
Concept-TRAK: Understanding how diffusion models learn concepts through concept-level attribution
Jul 09, 2025



While diffusion models excel at image generation, their growing adoption raises critical concerns around copyright issues and model transparency. Existing attribution methods identify training examples influencing an entire image, but fall short in isolating contributions to specific elements, such as styles or objects, that matter most to stakeholders. To bridge this gap, we introduce \emph{concept-level attribution} via a novel method called \emph{Concept-TRAK}. Concept-TRAK extends influence functions with two key innovations: (1) a reformulated diffusion training loss based on diffusion posterior sampling, enabling robust, sample-specific attribution; and (2) a concept-aware reward function that emphasizes semantic relevance. We evaluate Concept-TRAK on the AbC benchmark, showing substantial improvements over prior methods. Through diverse case studies--ranging from identifying IP-protected and unsafe content to analyzing prompt engineering and compositional learning--we demonstrate how concept-level attribution yields actionable insights for responsible generative AI development and governance.
Forging and Removing Latent-Noise Diffusion Watermarks Using a Single Image
Apr 27, 2025Watermarking techniques are vital for protecting intellectual property and preventing fraudulent use of media. Most previous watermarking schemes designed for diffusion models embed a secret key in the initial noise. The resulting pattern is often considered hard to remove and forge into unrelated images. In this paper, we propose a black-box adversarial attack without presuming access to the diffusion model weights. Our attack uses only a single watermarked example and is based on a simple observation: there is a many-to-one mapping between images and initial noises. There are regions in the clean image latent space pertaining to each watermark that get mapped to the same initial noise when inverted. Based on this intuition, we propose an adversarial attack to forge the watermark by introducing perturbations to the images such that we can enter the region of watermarked images. We show that we can also apply a similar approach for watermark removal by learning perturbations to exit this region. We report results on multiple watermarking schemes (Tree-Ring, RingID, WIND, and Gaussian Shading) across two diffusion models (SDv1.4 and SDv2.0). Our results demonstrate the effectiveness of the attack and expose vulnerabilities in the watermarking methods, motivating future research on improving them.
SteerMusic: Enhanced Musical Consistency for Zero-shot Text-Guided and Personalized Music Editing
Apr 15, 2025Music editing is an important step in music production, which has broad applications, including game development and film production. Most existing zero-shot text-guided methods rely on pretrained diffusion models by involving forward-backward diffusion processes for editing. However, these methods often struggle to maintain the music content consistency. Additionally, text instructions alone usually fail to accurately describe the desired music. In this paper, we propose two music editing methods that enhance the consistency between the original and edited music by leveraging score distillation. The first method, SteerMusic, is a coarse-grained zero-shot editing approach using delta denoising score. The second method, SteerMusic+, enables fine-grained personalized music editing by manipulating a concept token that represents a user-defined musical style. SteerMusic+ allows for the editing of music into any user-defined musical styles that cannot be achieved by the text instructions alone. Experimental results show that our methods outperform existing approaches in preserving both music content consistency and editing fidelity. User studies further validate that our methods achieve superior music editing quality. Audio examples are available on https://steermusic.pages.dev/.
Transformed Low-rank Adaptation via Tensor Decomposition and Its Applications to Text-to-image Models
Jan 15, 2025
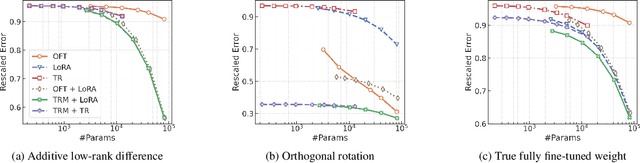
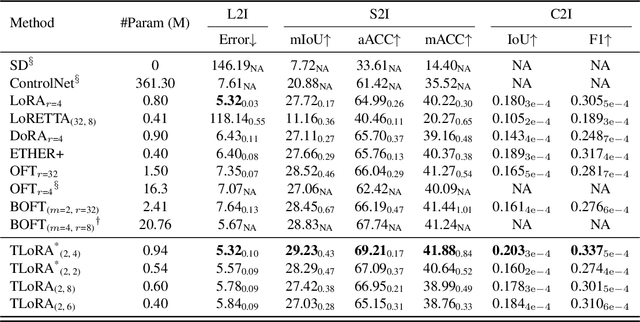
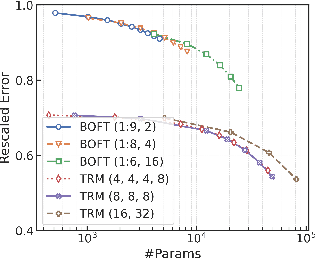
Parameter-Efficient Fine-Tuning (PEFT) of text-to-image models has become an increasingly popular technique with many applications. Among the various PEFT methods, Low-Rank Adaptation (LoRA) and its variants have gained significant attention due to their effectiveness, enabling users to fine-tune models with limited computational resources. However, the approximation gap between the low-rank assumption and desired fine-tuning weights prevents the simultaneous acquisition of ultra-parameter-efficiency and better performance. To reduce this gap and further improve the power of LoRA, we propose a new PEFT method that combines two classes of adaptations, namely, transform and residual adaptations. In specific, we first apply a full-rank and dense transform to the pre-trained weight. This learnable transform is expected to align the pre-trained weight as closely as possible to the desired weight, thereby reducing the rank of the residual weight. Then, the residual part can be effectively approximated by more compact and parameter-efficient structures, with a smaller approximation error. To achieve ultra-parameter-efficiency in practice, we design highly flexible and effective tensor decompositions for both the transform and residual adaptations. Additionally, popular PEFT methods such as DoRA can be summarized under this transform plus residual adaptation scheme. Experiments are conducted on fine-tuning Stable Diffusion models in subject-driven and controllable generation. The results manifest that our method can achieve better performances and parameter efficiency compared to LoRA and several baselines.
Blind Inverse Problem Solving Made Easy by Text-to-Image Latent Diffusion
Nov 30, 2024



Blind inverse problems, where both the target data and forward operator are unknown, are crucial to many computer vision applications. Existing methods often depend on restrictive assumptions such as additional training, operator linearity, or narrow image distributions, thus limiting their generalizability. In this work, we present LADiBI, a training-free framework that uses large-scale text-to-image diffusion models to solve blind inverse problems with minimal assumptions. By leveraging natural language prompts, LADiBI jointly models priors for both the target image and operator, allowing for flexible adaptation across a variety of tasks. Additionally, we propose a novel posterior sampling approach that combines effective operator initialization with iterative refinement, enabling LADiBI to operate without predefined operator forms. Our experiments show that LADiBI is capable of solving a broad range of image restoration tasks, including both linear and nonlinear problems, on diverse target image distributions.
Mitigating Embedding Collapse in Diffusion Models for Categorical Data
Oct 18, 2024



Latent diffusion models have enabled continuous-state diffusion models to handle a variety of datasets, including categorical data. However, most methods rely on fixed pretrained embeddings, limiting the benefits of joint training with the diffusion model. While jointly learning the embedding (via reconstruction loss) and the latent diffusion model (via score matching loss) could enhance performance, our analysis shows that end-to-end training risks embedding collapse, degrading generation quality. To address this issue, we introduce CATDM, a continuous diffusion framework within the embedding space that stabilizes training. We propose a novel objective combining the joint embedding-diffusion variational lower bound with a Consistency-Matching (CM) regularizer, alongside a shifted cosine noise schedule and random dropping strategy. The CM regularizer ensures the recovery of the true data distribution. Experiments on benchmarks show that CATDM mitigates embedding collapse, yielding superior results on FFHQ, LSUN Churches, and LSUN Bedrooms. In particular, CATDM achieves an FID of 6.81 on ImageNet $256\times256$ with 50 steps. It outperforms non-autoregressive models in machine translation and is on a par with previous methods in text generation.