 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUDA: Counterfactual Group-wise Training Data Attribution for Diffusion Models via Unlearning
Jan 30, 2026Training-data attribution for vision generative models aims to identify which training data influenced a given output. While most methods score individual examples, practitioners often need group-level answers (e.g., artistic styles or object classes). Group-wise attribution is counterfactual: how would a model's behavior on a generated sample change if a group were absent from training? A natural realization of this counterfactual is Leave-One-Group-Out (LOGO) retraining, which retrains the model with each group removed; however, it becomes computationally prohibitive as the number of groups grows. We propose GUDA (Group Unlearning-based Data Attribution) for diffusion models, which approximates each counterfactual model by applying machine unlearning to a shared full-data model instead of training from scratch. GUDA quantifies group influence using differences in a likelihood-based scoring rule (ELBO) between the full model and each unlearned counterfactual. Experiments on CIFAR-10 and artistic style attribution with Stable Diffusion show that GUDA identifies primary contributing groups more reliably than semantic similarity, gradient-based attribution, and instance-level unlearning approaches, while achieving x100 speedup on CIFAR-10 over LOGO retraining.
Summary of The Inaugural Music Source Restoration Challenge
Jan 07, 2026Music Source Restoration (MSR) aims to recover original, unprocessed instrument stems from professionally mixed and degraded audio, requiring the reversal of both production effects and real-world degradations. We present the inaugural MSR Challenge, which features objective evaluation on studio-produced mixtures using Multi-Mel-SNR, Zimtohrli, and FAD-CLAP, alongside subjective evaluation on real-world degraded recordings. Five teams participated in the challenge. The winning system achieved 4.46 dB Multi-Mel-SNR and 3.47 MOS-Overall, corresponding to relative improvements of 91% and 18% over the second-place system, respectively. Per-stem analysis reveals substantial variation in restoration difficulty across instruments, with bass averaging 4.59 dB across all teams, while percussion averages only 0.29 dB. The dataset, evaluation protocols, and baselines are available at https://msrchallenge.com/.
Improved Object-Centric Diffusion Learning with Registers and Contrastive Alignment
Jan 03, 2026Slot Attention (SA) with pretrained diffusion models has recently shown promise for object-centric learning (OCL), but suffers from slot entanglement and weak alignment between object slots and image content. We propose Contrastive Object-centric Diffusion Alignment (CODA), a simple extension that (i) employs register slots to absorb residual attention and reduce interference between object slots, and (ii) applies a contrastive alignment loss to explicitly encourage slot-image correspondence. The resulting training objective serves as a tractable surrogate for maximizing mutual information (MI) between slots and inputs, strengthening slot representation quality. On both synthetic (MOVi-C/E) and real-world datasets (VOC, COCO), CODA improves object discovery (e.g., +6.1% FG-ARI on COCO), property prediction, and compositional image generation over strong baselines. Register slots add negligible overhead, keeping CODA efficient and scalable. These results indicate potential applications of CODA as an effective framework for robust OCL in complex, real-world scenes.
Do Foundational Audio Encoders Understand Music Structure?
Dec 19, 2025In music information retrieval (MIR) research, the use of pretrained foundational audio encoders (FAEs) has recently become a trend. FAEs pretrained on large amounts of music and audio data have been shown to improve performance on MIR tasks such as music tagging and automatic music transcription. However, their use for music structure analysis (MSA) remains underexplored. Although many open-source FAE models are available, only a small subset has been examined for MSA, and the impact of factors such as learning methods, training data, and model context length on MSA performance remains unclear. In this study, we conduct comprehensive experiments on 11 types of FAEs to investigate how these factors affect MSA performance. Our results demonstrate that FAEs using selfsupervised learning with masked language modeling on music data are particularly effective for MSA. These findings pave the way for future research in MSA.
AutoRefiner: Improving Autoregressive Video Diffusion Models via Reflective Refinement Over the Stochastic Sampling Path
Dec 15, 2025Autoregressive video diffusion models (AR-VDMs) show strong promise as scalable alternatives to bidirectional VDMs, enabling real-time and interactive applications. Yet there remains room for improvement in their sample fidelity. A promising solution is inference-time alignment, which optimizes the noise space to improve sample fidelity without updating model parameters. Yet, optimization- or search-based methods are computationally impractical for AR-VDMs. Recent text-to-image (T2I) works address this via feedforward noise refiners that modulate sampled noises in a single forward pass. Can such noise refiners be extended to AR-VDMs? We identify the failure of naively extending T2I noise refiners to AR-VDMs and propose AutoRefiner-a noise refiner tailored for AR-VDMs, with two key designs: pathwise noise refinement and a reflective KV-cache. Experiments demonstrate that AutoRefiner serves as an efficient plug-in for AR-VDMs, effectively enhancing sample fidelity by refining noise along stochastic denoising paths.
Schrodinger Audio-Visual Editor: Object-Level Audiovisual Removal
Dec 14, 2025Joint editing of audio and visual content is crucial for precise and controllable content creation. This new task poses challenges due to the limitations of paired audio-visual data before and after targeted edits, and the heterogeneity across modalities. To address the data and modeling challenges in joint audio-visual editing, we introduce SAVEBench, a paired audiovisual dataset with text and mask conditions to enable object-grounded source-to-target learning. With SAVEBench, we train the Schrodinger Audio-Visual Editor (SAVE), an end-to-end flow-matching model that edits audio and video in parallel while keeping them aligned throughout processing. SAVE incorporates a Schrodinger Bridge that learns a direct transport from source to target audiovisual mixtures. Our evaluation demonstrates that the proposed SAVE model is able to remove the target objects in audio and visual content while preserving the remaining content, with stronger temporal synchronization and audiovisual semantic correspondence compared with pairwise combinations of an audio editor and a video editor.
PAVAS: Physics-Aware Video-to-Audio Synthesis
Dec 09, 2025



Recent advances in Video-to-Audio (V2A) generation have achieved impressive perceptual quality and temporal synchronization, yet most models remain appearance-driven, capturing visual-acoustic correlations without considering the physical factors that shape real-world sounds. We present Physics-Aware Video-to-Audio Synthesis (PAVAS), a method that incorporates physical reasoning into a latent diffusion-based V2A generation through the Physics-Driven Audio Adapter (Phy-Adapter). The adapter receives object-level physical parameters estimated by the Physical Parameter Estimator (PPE), which uses a Vision-Language Model (VLM) to infer the moving-object mass and a segmentation-based dynamic 3D reconstruction module to recover its motion trajectory for velocity computation. These physical cues enable the model to synthesize sounds that reflect underlying physical factors. To assess physical realism, we curate VGG-Impact, a benchmark focusing on object-object interactions, and introduce Audio-Physics Correlation Coefficient (APCC), an evaluation metric that measures consistency between physical and auditory attributes. Comprehensive experiments show that PAVAS produces physically plausible and perceptually coherent audio, outperforming existing V2A models in both quantitative and qualitative evaluations. Visit https://physics-aware-video-to-audio-synthesis.github.io for demo videos.
Coherent Audio-Visual Editing via Conditional Audio Generation Following Video Edits
Dec 08, 2025We introduce a novel pipeline for joint audio-visual editing that enhances the coherence between edited video and its accompanying audio. Our approach first applies state-of-the-art video editing techniques to produce the target video, then performs audio editing to align with the visual changes. To achieve this, we present a new video-to-audio generation model that conditions on the source audio, target video, and a text prompt. We extend the model architecture to incorporate conditional audio input and propose a data augmentation strategy that improves training efficiency. Furthermore, our model dynamically adjusts the influence of the source audio based on the complexity of the edits, preserving the original audio structure where possible. Experimental results demonstrate that our method outperforms existing approaches in maintaining audio-visual alignment and content integrity.
MeanFlow Transformers with Representation Autoencoders
Nov 17, 2025MeanFlow (MF) is a diffusion-motivated generative model that enables efficient few-step generation by learning long jumps directly from noise to data. In practice, it is often used as a latent MF by leveraging the pre-trained Stable Diffusion variational autoencoder (SD-VAE) for high-dimensional data modeling. However, MF training remains computationally demanding and is often unstable. During inference, the SD-VAE decoder dominates the generation cost, and MF depends on complex guidance hyperparameters for class-conditional generation. In this work, we develop an efficient training and sampling scheme for MF in the latent space of a Representation Autoencoder (RAE), where a pre-trained vision encoder (e.g., DINO) provides semantically rich latents paired with a lightweight decoder. We observe that naive MF training in the RAE latent space suffers from severe gradient explosion. To stabilize and accelerate training, we adopt Consistency Mid-Training for trajectory-aware initialization and use a two-stage scheme: distillation from a pre-trained flow matching teacher to speed convergence and reduce variance, followed by an optional bootstrapping stage with a one-point velocity estimator to further reduce deviation from the oracle mean flow. This design removes the need for guidance, simplifies training configurations, and reduces computation in both training and sampling. Empirically, our method achieves a 1-step FID of 2.03, outperforming vanilla MF's 3.43, while reducing sampling GFLOPS by 38% and total training cost by 83% on ImageNet 256. We further scale our approach to ImageNet 512, achieving a competitive 1-step FID of 3.23 with the lowest GFLOPS among all baselines. Code is available at https://github.com/sony/mf-rae.
FoleyBench: A Benchmark For Video-to-Audio Models
Nov 17, 2025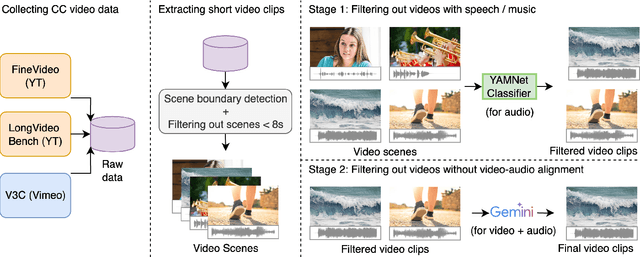
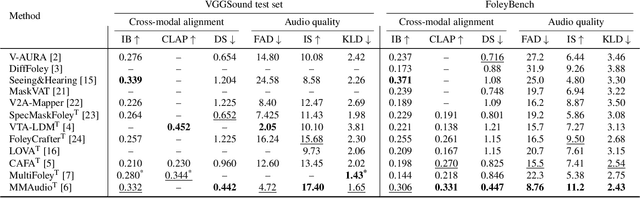
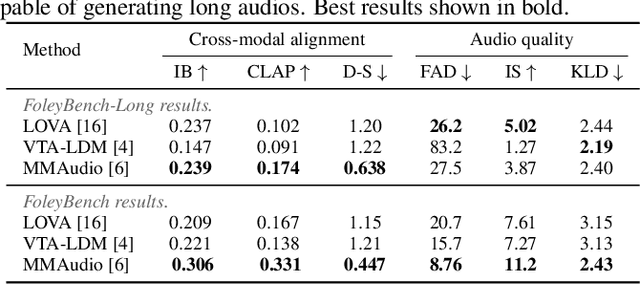

Video-to-audio generation (V2A) is of increasing importance in domains such as film post-production, AR/VR, and sound design, particularly for the creation of Foley sound effects synchronized with on-screen actions. Foley requires generating audio that is both semantically aligned with visible events and temporally aligned with their timing. Yet, there is a mismatch between evaluation and downstream applications due to the absence of a benchmark tailored to Foley-style scenarios. We find that 74% of videos from past evaluation datasets have poor audio-visual correspondence. Moreover, they are dominated by speech and music, domains that lie outside the use case for Foley. To address this gap, we introduce FoleyBench, the first large-scale benchmark explicitly designed for Foley-style V2A evaluation. FoleyBench contains 5,000 (video, ground-truth audio, text caption) triplets, each featuring visible sound sources with audio causally tied to on-screen events. The dataset is built using an automated, scalable pipeline applied to in-the-wild internet videos from YouTube-based and Vimeo-based sources. Compared to past datasets, we show that videos from FoleyBench have stronger coverage of sound categories from a taxonomy specifically designed for Foley sound. Each clip is further labeled with metadata capturing source complexity, UCS/AudioSet category, and video length, enabling fine-grained analysis of model performance and failure modes. We benchmark several state-of-the-art V2A models, evaluating them on audio quality, audio-video alignment, temporal synchronization, and audio-text consistency. Samples are available at: https://gclef-cmu.org/foleybench