 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodied-R1.5: Evolving Physical Intelligence via Embodied Foundation Models
Jun 09, 2026We introduce Embodied-R1.5, a unified Embodied Foundation Model (EFM) that integrates comprehensive embodied reasoning capabilities, spanning embodied cognition, task planning, correction, and pointing, within a single architecture toward general physical intelligence. Leveraging three automated data construction pipelines to significantly expand the data coverage of critical capabilities, we build a large-scale data system of over 15B tokens, and design a multi-task balanced RL recipe to alleviate heterogeneous task conflicts. We further introduce a Planner-Grounder-Corrector (PGC) closed-loop framework that enables a single model to autonomously execute and self-correct over long-horizon tasks. With only 8B parameters, Embodied-R1.5 achieves SOTA on 16 out of 24 embodied VLM benchmarks, surpassing leading models like Gemini-Robotics-ER-1.5 and GPT-5.4. Benefiting from the internalized embodied capabilities, Embodied-R1.5 can be fine-tuned into a VLA with only a small amount of data, outperforming leading VLA models like $π_{0.5}$ across 4 popular manipulation benchmark suites. We further conduct extensive zero-shot real-robot experiments, validating performance in instruction following, affordance grounding, articulated object manipulation, and long-horizon complex tasks, demonstrating strong generalization to the physical world. We open-source model weights, datasets, training code, and EmbodiedEvalKit, an evaluation framework tailored for embodied tasks, to facilitate future research in EFMs.
MusTBENCH: Benchmarking and Advancing Temporal Grounding in Music LLMs
May 28, 2026Recent Large Audio-Language Models (LALMs) have demonstrated promising abilities in understanding musical content. However, whether their responses are grounded in the correct temporal regions of the audio remains underexplored. This limitation is particularly critical for music understanding, where key information often occurs as temporally localized events, such as instrument entries and rhythmic transitions. To address this gap, we introduce MusTBENCH, a music-expert-validated benchmark designed to evaluate temporal grounding in LALMs through five temporally grounded question-answering tasks. To further improve temporal grounding in existing models, we propose MusT, a novel four-stage temporal optimization recipe spanning music encoder adaptation, LLM adaptation, LLM supervised fine-tuning, and RL-based optimization. Experiments on MusTBENCH show that existing LALMs struggle with precise temporal grounding, while MusT brings significant improvements over strong baselines. These results establish temporal grounding as a key missing capability in current LALMs and position MusTBENCH as a challenging benchmark for future research in temporally grounded music understanding.
Break-the-Beat! Controllable MIDI-to-Drum Audio Synthesis
May 14, 2026Current methods for creating drum loop audio in digital music production, such as using one-shot samples or resampling, often demand non-trivial efforts of creators. While recent generative models achieve high fidelity and adhere to text, they lack the specific control needed for such a task. Existing symbolic-to-audio research often focuses on single, tonal instruments, leaving the challenge of polyphonic, percussive drum synthesis unaddressed. We address this gap by introducing ``Break-the-Beat!,'' a model capable of rendering a drum MIDI with the timbre of a reference audio. It is built by fine-tuning a pre-trained text-to-audio model with our proposed content encoder and a effective hybrid conditioning mechanism. To enable this, we construct a new dataset of paired target-reference drum audio from existing drum audio datasets. Experiments demonstrate that our model generates high-quality drum audio that follows high-resolution drum MIDI, achieving strong performance across metrics of audio quality, rhythmic alignment, and beat continuity. This offer producers a new, controllable tool for creative production. Demo page: https://ik4sumii.github.io/break-the-beat/
Remedy-R: Generative Reasoning for Machine Translation Evaluation without Error Annotations
Dec 21, 2025Over the years, automatic MT metrics have hillclimbed benchmarks and presented strong and sometimes human-level agreement with human ratings. Yet they remain black-box, offering little insight into their decision-making and often failing under real-world out-of-distribution (OOD) inputs. We introduce Remedy-R, a reasoning-driven generative MT metric trained with reinforcement learning from pairwise translation preferences, without requiring error-span annotations or distillation from closed LLMs. Remedy-R produces step-by-step analyses of accuracy, fluency, and completeness, followed by a final score, enabling more interpretable assessments. With only 60K training pairs across two language pairs, Remedy-R remains competitive with top scalar metrics and GPT-4-based judges on WMT22-24 meta-evaluation, generalizes to other languages, and exhibits strong robustness on OOD stress tests. Moreover, Remedy-R models generate self-reflective feedback that can be reused for translation improvement. Building on this finding, we introduce Remedy-R Agent, a simple evaluate-revise pipeline that leverages Remedy-R's evaluation analysis to refine translations. This agent consistently improves translation quality across diverse models, including Qwen2.5, ALMA-R, GPT-4o-mini, and Gemini-2.0-Flash, suggesting that Remedy-R's reasoning captures translation-relevant information and is practically useful.
VIRTUE: Visual-Interactive Text-Image Universal Embedder
Oct 01, 2025Multimodal representation learning models have demonstrated successful operation across complex tasks, and the integration of vision-language models (VLMs) has further enabled embedding models with instruction-following capabilities. However, existing embedding models lack visual-interactive capabilities to specify regions of interest from users (e.g., point, bounding box, mask), which have been explored in generative models to broaden their human-interactive applicability. Equipping embedding models with visual interactions not only would unlock new applications with localized grounding of user intent, which remains unexplored, but also enable the models to learn entity-level information within images to complement their global representations for conventional embedding tasks. In this paper, we propose a novel Visual-InteRactive Text-Image Universal Embedder (VIRTUE) that extends the capabilities of the segmentation model and the vision-language model to the realm of representation learning. In VIRTUE, the segmentation model can process visual prompts that pinpoint specific regions within an image, thereby enabling the embedder to handle complex and ambiguous scenarios more precisely. To evaluate the visual-interaction ability of VIRTUE, we introduce a large-scale Segmentation-and-Scene Caption Retrieval (SCaR) benchmark comprising 1M samples that aims to retrieve the text caption by jointly considering the entity with a specific object and image scene. VIRTUE consistently achieves a state-of-the-art performance with significant improvements across 36 universal MMEB (3.1%-8.5%) and five visual-interactive SCaR (15.2%-20.3%) tasks.
From Chaos to Order: The Atomic Reasoner Framework for Fine-grained Reasoning in Large Language Models
Mar 20, 2025



Recent advances in large language models (LLMs) have shown remarkable progress, yet their capacity for logical ``slow-thinking'' reasoning persists as a critical research frontier. Current inference scaling paradigms suffer from two fundamental constraints: fragmented thought flows compromising logical coherence, and intensively computational complexity that escalates with search space dimensions. To overcome these limitations, we present \textbf{Atomic Reasoner} (\textbf{AR}), a cognitive inference strategy that enables fine-grained reasoning through systematic atomic-level operations. AR decomposes the reasoning process into atomic cognitive units, employing a cognitive routing mechanism to dynamically construct reasoning representations and orchestrate inference pathways. This systematic methodology implements stepwise, structured cognition, which ensures logical coherence while significantly reducing cognitive load, effectively simulating the cognitive patterns observed in human deep thinking processes. Extensive experimental results demonstrate AR's superior reasoning capabilities without the computational burden of exhaustive solution searches, particularly excelling in linguistic logic puzzles. These findings substantiate AR's effectiveness in enhancing LLMs' capacity for robust, long-sequence logical reasoning and deliberation.
Cross-Modal Learning for Music-to-Music-Video Description Generation
Mar 14, 2025Music-to-music-video generation is a challenging task due to the intrinsic differences between the music and video modalities. The advent of powerful text-to-video diffusion models has opened a promising pathway for music-video (MV) generation by first addressing the music-to-MV description task and subsequently leveraging these models for video generation. In this study, we focus on the MV description generation task and propose a comprehensive pipeline encompassing training data construction and multimodal model fine-tuning. We fine-tune existing pre-trained multimodal models on our newly constructed music-to-MV description dataset based on the Music4All dataset, which integrates both musical and visual information. Our experimental results demonstrate that music representations can be effectively mapped to textual domains, enabling the generation of meaningful MV description directly from music inputs. We also identify key components in the dataset construction pipeline that critically impact the quality of MV description and highlight specific musical attributes that warrant greater focus for improved MV description generation.
Joint Fusion and Encoding: Advancing Multimodal Retrieval from the Ground Up
Feb 27, 2025Information retrieval is indispensable for today's Internet applications, yet traditional semantic matching techniques often fall short in capturing the fine-grained cross-modal interactions required for complex queries. Although late-fusion two-tower architectures attempt to bridge this gap by independently encoding visual and textual data before merging them at a high level, they frequently overlook the subtle interplay essential for comprehensive understanding. In this work, we rigorously assess these limitations and introduce a unified retrieval framework that fuses visual and textual cues from the ground up, enabling early cross-modal interactions for enhancing context interpretation. Through a two-stage training process--comprising post-training adaptation followed by instruction tuning--we adapt MLLMs as retrievers using a simple one-tower architecture. Our approach outperforms conventional methods across diverse retrieval scenarios, particularly when processing complex multi-modal inputs. Notably, the joint fusion encoder yields greater improvements on tasks that require modality fusion compared to those that do not, underscoring the transformative potential of early integration strategies and pointing toward a promising direction for contextually aware and effective information retrieval.
DeepResonance: Enhancing Multimodal Music Understanding via Music-centric Multi-way Instruction Tuning
Feb 18, 2025Recent advancements in music large language models (LLMs) have significantly improved music understanding tasks, which involve the model's ability to analyze and interpret various musical elements. These improvements primarily focused on integrating both music and text inputs. However, the potential of incorporating additional modalities such as images, videos and textual music features to enhance music understanding remains unexplored. To bridge this gap, we propose DeepResonance, a multimodal music understanding LLM fine-tuned via multi-way instruction tuning with multi-way aligned music, text, image, and video data. To this end, we construct Music4way-MI2T, Music4way-MV2T, and Music4way-Any2T, three 4-way training and evaluation datasets designed to enable DeepResonance to integrate both visual and textual music feature content. We also introduce multi-sampled ImageBind embeddings and a pre-alignment Transformer to enhance modality fusion prior to input into text LLMs, tailoring DeepResonance for multi-way instruction tuning. Our model achieves state-of-the-art performances across six music understanding tasks, highlighting the benefits of the auxiliary modalities and the structural superiority of DeepResonance. We plan to open-source the models and the newly constructed datasets.
Beyond Simple Sum of Delayed Rewards: Non-Markovian Reward Modeling for Reinforcement Learning
Oct 26, 2024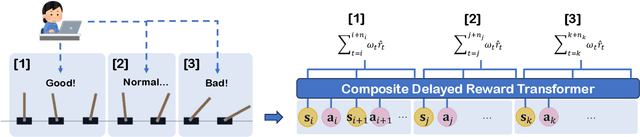
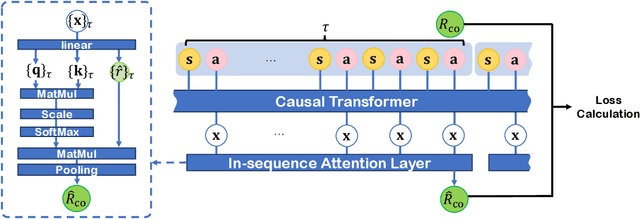
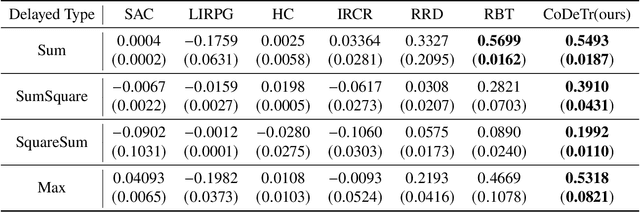
Reinforcement Learning (RL) empowers agents to acquire various skills by learning from reward signals. Unfortunately, designing high-quality instance-level rewards often demands significant effort. An emerging alternative, RL with delayed reward, focuses on learning from rewards presented periodically, which can be obtained from human evaluators assessing the agent's performance over sequences of behaviors. However, traditional methods in this domain assume the existence of underlying Markovian rewards and that the observed delayed reward is simply the sum of instance-level rewards, both of which often do not align well with real-world scenarios. In this paper, we introduce the problem of RL from Composite Delayed Reward (RLCoDe), which generalizes traditional RL from delayed rewards by eliminating the strong assumption. We suggest that the delayed reward may arise from a more complex structure reflecting the overall contribution of the sequence. To address this problem, we present a framework for modeling composite delayed rewards, using a weighted sum of non-Markovian components to capture the different contributions of individual steps. Building on this framework, we propose Composite Delayed Reward Transformer (CoDeTr), which incorporates a specialized in-sequence attention mechanism to effectively model these contributions. We conduct experiments on challenging locomotion tasks where the agent receives delayed rewards computed from composite functions of observable step rewards. The experimental results indicate that CoDeTr consistently outperforms baseline methods across evaluated metrics. Additionally, we demonstrate that it effectively identifies the most significant time steps within the sequence and accurately predicts rewards that closely reflect the environment feedback.