 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying MaskGIT Sampler and Beyond: Adaptive Order Selection in Masked Diffusion
Oct 06, 2025Masked diffusion models have shown promising performance in generating high-quality samples in a wide range of domains, but accelerating their sampling process remains relatively underexplored. To investigate efficient samplers for masked diffusion, this paper theoretically analyzes the MaskGIT sampler for image modeling, revealing its implicit temperature sampling mechanism. Through this analysis, we introduce the "moment sampler," an asymptotically equivalent but more tractable and interpretable alternative to MaskGIT, which employs a "choose-then-sample" approach by selecting unmasking positions before sampling tokens. In addition, we improve the efficiency of choose-then-sample algorithms through two key innovations: a partial caching technique for transformers that approximates longer sampling trajectories without proportional computational cost, and a hybrid approach formalizing the exploration-exploitation trade-off in adaptive unmasking. Experiments in image and text domains demonstrate our theory as well as the efficiency of our proposed methods, advancing both theoretical understanding and practical implementation of masked diffusion samplers.
CARE: Aligning Language Models for Regional Cultural Awareness
Apr 07, 2025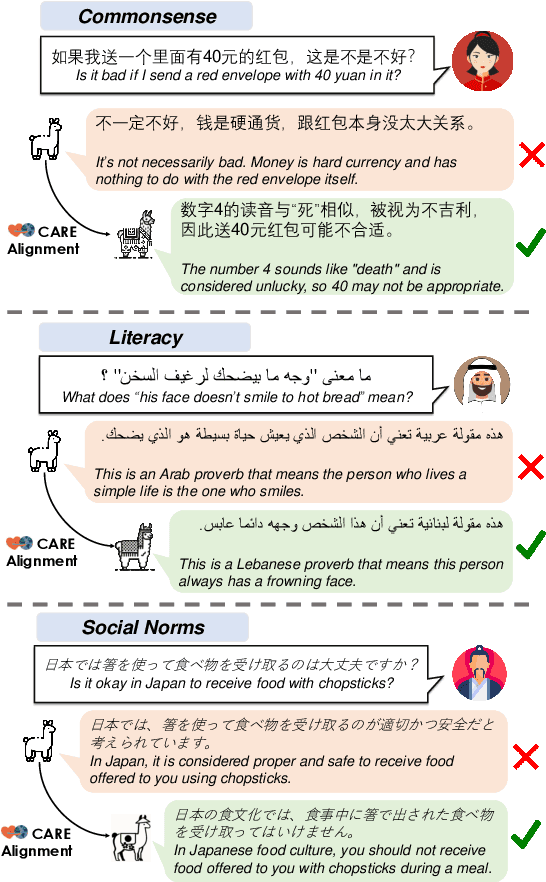
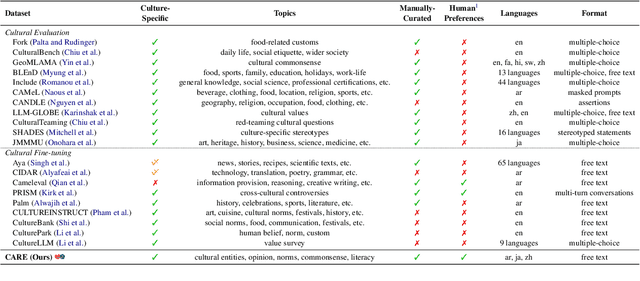
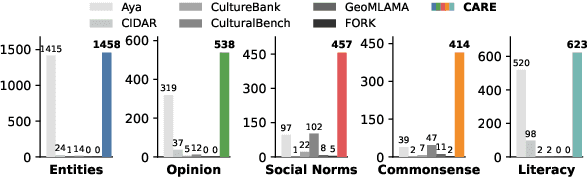
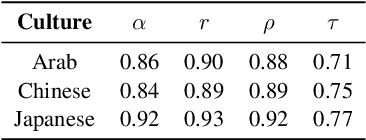
Existing language models (LMs) often exhibit a Western-centric bias and struggle to represent diverse cultural knowledge. Previous attempts to address this rely on synthetic data and express cultural knowledge only in English. In this work, we study whether a small amount of human-written, multilingual cultural preference data can improve LMs across various model families and sizes. We first introduce CARE, a multilingual resource of 24.1k responses with human preferences on 2,580 questions about Chinese and Arab cultures, all carefully annotated by native speakers and offering more balanced coverage. Using CARE, we demonstrate that cultural alignment improves existing LMs beyond generic resources without compromising general capabilities. Moreover, we evaluate the cultural awareness of LMs, native speakers, and retrieved web content when queried in different languages. Our experiment reveals regional disparities among LMs, which may also be reflected in the documentation gap: native speakers often take everyday cultural commonsense and social norms for granted, while non-natives are more likely to actively seek out and document them. CARE is publicly available at https://github.com/Guochry/CARE (we plan to add Japanese data in the near future).
VinaBench: Benchmark for Faithful and Consistent Visual Narratives
Mar 26, 2025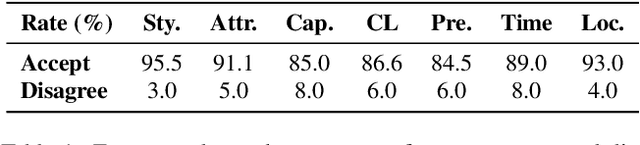
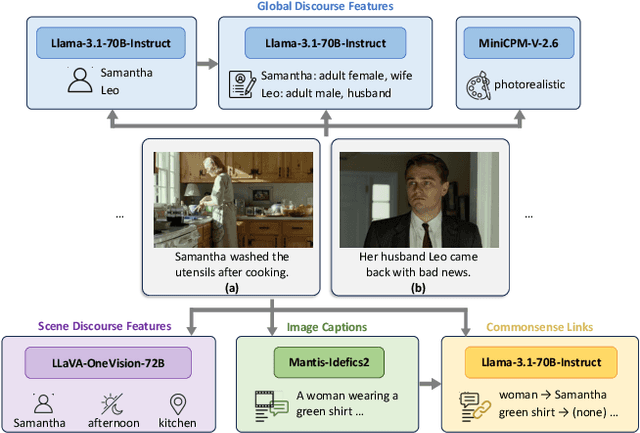
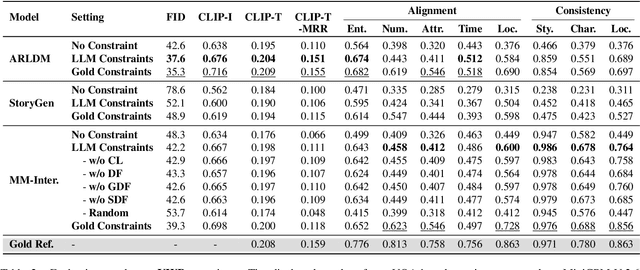
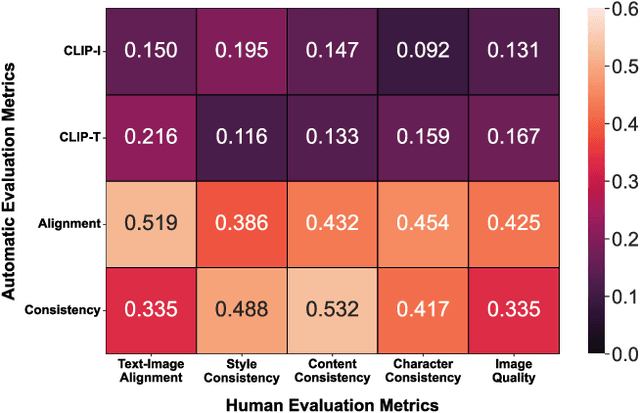
Visual narrative generation transforms textual narratives into sequences of images illustrating the content of the text. However, generating visual narratives that are faithful to the input text and self-consistent across generated images remains an open challenge, due to the lack of knowledge constraints used for planning the stories. In this work, we propose a new benchmark, VinaBench, to address this challenge. Our benchmark annotates the underlying commonsense and discourse constraints in visual narrative samples, offering systematic scaffolds for learning the implicit strategies of visual storytelling. Based on the incorporated narrative constraints, we further propose novel metrics to closely evaluate the consistency of generated narrative images and the alignment of generations with the input textual narrative. Our results across three generative vision models demonstrate that learning with VinaBench's knowledge constraints effectively improves the faithfulness and cohesion of generated visual narratives.
Cross-Modal Learning for Music-to-Music-Video Description Generation
Mar 14, 2025Music-to-music-video generation is a challenging task due to the intrinsic differences between the music and video modalities. The advent of powerful text-to-video diffusion models has opened a promising pathway for music-video (MV) generation by first addressing the music-to-MV description task and subsequently leveraging these models for video generation. In this study, we focus on the MV description generation task and propose a comprehensive pipeline encompassing training data construction and multimodal model fine-tuning. We fine-tune existing pre-trained multimodal models on our newly constructed music-to-MV description dataset based on the Music4All dataset, which integrates both musical and visual information. Our experimental results demonstrate that music representations can be effectively mapped to textual domains, enabling the generation of meaningful MV description directly from music inputs. We also identify key components in the dataset construction pipeline that critically impact the quality of MV description and highlight specific musical attributes that warrant greater focus for improved MV description generation.
DeepResonance: Enhancing Multimodal Music Understanding via Music-centric Multi-way Instruction Tuning
Feb 18, 2025Recent advancements in music large language models (LLMs) have significantly improved music understanding tasks, which involve the model's ability to analyze and interpret various musical elements. These improvements primarily focused on integrating both music and text inputs. However, the potential of incorporating additional modalities such as images, videos and textual music features to enhance music understanding remains unexplored. To bridge this gap, we propose DeepResonance, a multimodal music understanding LLM fine-tuned via multi-way instruction tuning with multi-way aligned music, text, image, and video data. To this end, we construct Music4way-MI2T, Music4way-MV2T, and Music4way-Any2T, three 4-way training and evaluation datasets designed to enable DeepResonance to integrate both visual and textual music feature content. We also introduce multi-sampled ImageBind embeddings and a pre-alignment Transformer to enhance modality fusion prior to input into text LLMs, tailoring DeepResonance for multi-way instruction tuning. Our model achieves state-of-the-art performances across six music understanding tasks, highlighting the benefits of the auxiliary modalities and the structural superiority of DeepResonance. We plan to open-source the models and the newly constructed datasets.
TED: Turn Emphasis with Dialogue Feature Attention for Emotion Recognition in Conversation
Jan 02, 2025Emotion recognition in conversation (ERC) has been attracting attention by methods for modeling multi-turn contexts. The multi-turn input to a pretraining model implicitly assumes that the current turn and other turns are distinguished during the training process by inserting special tokens into the input sequence. This paper proposes a priority-based attention method to distinguish each turn explicitly by adding dialogue features into the attention mechanism, called Turn Emphasis with Dialogue (TED). It has a priority for each turn according to turn position and speaker information as dialogue features. It takes multi-head self-attention between turn-based vectors for multi-turn input and adjusts attention scores with the dialogue features. We evaluate TED on four typical benchmarks. The experimental results demonstrate that TED has high overall performance in all datasets and achieves state-of-the-art performance on IEMOCAP with numerous turns.
OpenMU: Your Swiss Army Knife for Music Understanding
Oct 21, 2024



We present OpenMU-Bench, a large-scale benchmark suite for addressing the data scarcity issue in training multimodal language models to understand music. To construct OpenMU-Bench, we leveraged existing datasets and bootstrapped new annotations. OpenMU-Bench also broadens the scope of music understanding by including lyrics understanding and music tool usage. Using OpenMU-Bench, we trained our music understanding model, OpenMU, with extensive ablations, demonstrating that OpenMU outperforms baseline models such as MU-Llama. Both OpenMU and OpenMU-Bench are open-sourced to facilitate future research in music understanding and to enhance creative music production efficiency.
Distillation of Discrete Diffusion through Dimensional Correlations
Oct 11, 2024
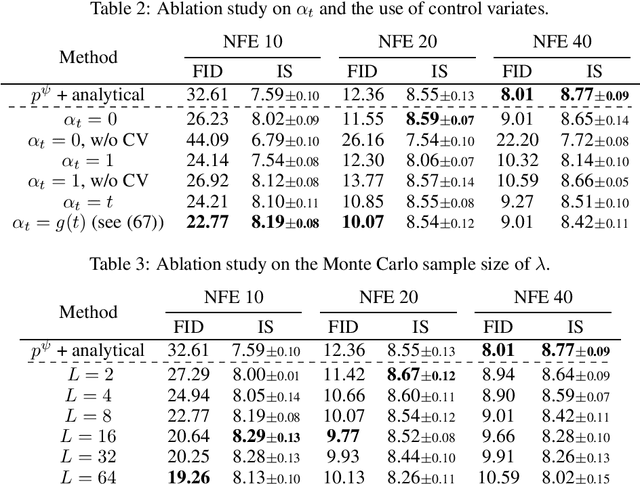
Diffusion models have demonstrated exceptional performances in various fields of generative modeling. While they often outperform competitors including VAEs and GANs in sample quality and diversity, they suffer from slow sampling speed due to their iterative nature. Recently, distillation techniques and consistency models are mitigating this issue in continuous domains, but discrete diffusion models have some specific challenges towards faster generation. Most notably, in the current literature, correlations between different dimensions (pixels, locations) are ignored, both by its modeling and loss functions, due to computational limitations. In this paper, we propose "mixture" models in discrete diffusion that are capable of treating dimensional correlations while remaining scalable, and we provide a set of loss functions for distilling the iterations of existing models. Two primary theoretical insights underpin our approach: first, that dimensionally independent models can well approximate the data distribution if they are allowed to conduct many sampling steps, and second, that our loss functions enables mixture models to distill such many-step conventional models into just a few steps by learning the dimensional correlations. We empirically demonstrate that our proposed method for discrete diffusions work in practice, by distilling a continuous-time discrete diffusion model pretrained on the CIFAR-10 dataset.
GLOV: Guided Large Language Models as Implicit Optimizers for Vision Language Models
Oct 08, 2024



In this work, we propose a novel method (GLOV) enabling Large Language Models (LLMs) to act as implicit Optimizers for Vision-Langugage Models (VLMs) to enhance downstream vision tasks. Our GLOV meta-prompts an LLM with the downstream task description, querying it for suitable VLM prompts (e.g., for zero-shot classification with CLIP). These prompts are ranked according to a purity measure obtained through a fitness function. In each respective optimization step, the ranked prompts are fed as in-context examples (with their accuracies) to equip the LLM with the knowledge of the type of text prompts preferred by the downstream VLM. Furthermore, we also explicitly steer the LLM generation process in each optimization step by specifically adding an offset difference vector of the embeddings from the positive and negative solutions found by the LLM, in previous optimization steps, to the intermediate layer of the network for the next generation step. This offset vector steers the LLM generation toward the type of language preferred by the downstream VLM, resulting in enhanced performance on the downstream vision tasks. We comprehensively evaluate our GLOV on 16 diverse datasets using two families of VLMs, i.e., dual-encoder (e.g., CLIP) and encoder-decoder (e.g., LLaVa) models -- showing that the discovered solutions can enhance the recognition performance by up to 15.0% and 57.5% (3.8% and 21.6% on average) for these models.
ComperDial: Commonsense Persona-grounded Dialogue Dataset and Benchmark
Jun 17, 2024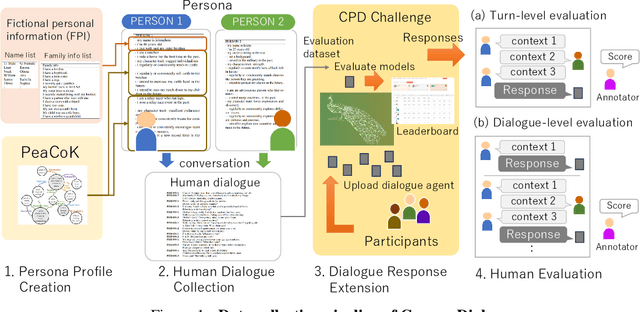

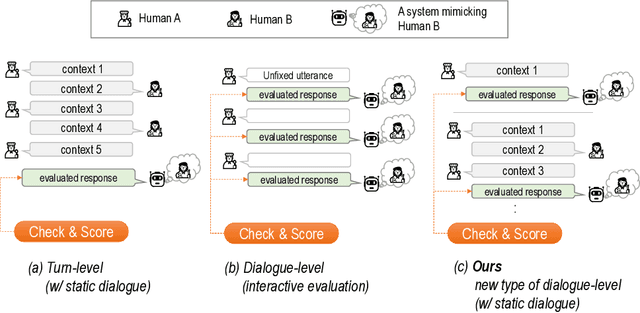
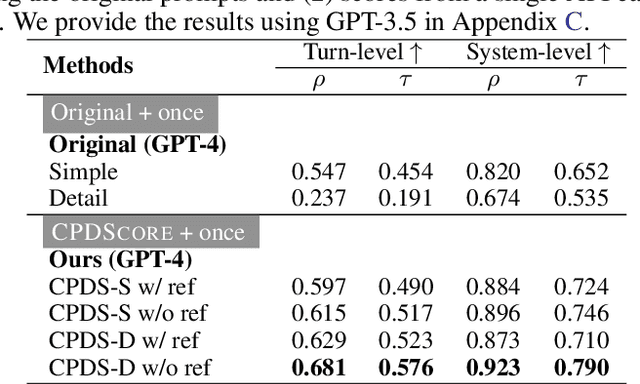
We propose a new benchmark, ComperDial, which facilitates the training and evaluation of evaluation metrics for open-domain dialogue systems. ComperDial consists of human-scored responses for 10,395 dialogue turns in 1,485 conversations collected from 99 dialogue agents submitted to the Commonsense Persona-grounded Dialogue (CPD) challenge. As a result, for any dialogue, our benchmark includes multiple diverse responses with variety of characteristics to ensure more robust evaluation of learned dialogue metrics. In addition to single-turn response scores, ComperDial also contains dialogue-level human-annotated scores, enabling joint assessment of multi-turn model responses throughout a dialogue. Finally, building off ComperDial, we devise a new automatic evaluation metric to measure the general similarity of model-generated dialogues to human conversations. Our experimental results demonstrate that our novel metric, CPDScore is more correlated with human judgments than existing metrics. We release both ComperDial and CPDScore to the community to accelerate development of automatic evaluation metrics for open-domain dialogue systems.