 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUDA: Counterfactual Group-wise Training Data Attribution for Diffusion Models via Unlearning
Jan 30, 2026Training-data attribution for vision generative models aims to identify which training data influenced a given output. While most methods score individual examples, practitioners often need group-level answers (e.g., artistic styles or object classes). Group-wise attribution is counterfactual: how would a model's behavior on a generated sample change if a group were absent from training? A natural realization of this counterfactual is Leave-One-Group-Out (LOGO) retraining, which retrains the model with each group removed; however, it becomes computationally prohibitive as the number of groups grows. We propose GUDA (Group Unlearning-based Data Attribution) for diffusion models, which approximates each counterfactual model by applying machine unlearning to a shared full-data model instead of training from scratch. GUDA quantifies group influence using differences in a likelihood-based scoring rule (ELBO) between the full model and each unlearned counterfactual. Experiments on CIFAR-10 and artistic style attribution with Stable Diffusion show that GUDA identifies primary contributing groups more reliably than semantic similarity, gradient-based attribution, and instance-level unlearning approaches, while achieving x100 speedup on CIFAR-10 over LOGO retraining.
Improved Object-Centric Diffusion Learning with Registers and Contrastive Alignment
Jan 03, 2026Slot Attention (SA) with pretrained diffusion models has recently shown promise for object-centric learning (OCL), but suffers from slot entanglement and weak alignment between object slots and image content. We propose Contrastive Object-centric Diffusion Alignment (CODA), a simple extension that (i) employs register slots to absorb residual attention and reduce interference between object slots, and (ii) applies a contrastive alignment loss to explicitly encourage slot-image correspondence. The resulting training objective serves as a tractable surrogate for maximizing mutual information (MI) between slots and inputs, strengthening slot representation quality. On both synthetic (MOVi-C/E) and real-world datasets (VOC, COCO), CODA improves object discovery (e.g., +6.1% FG-ARI on COCO), property prediction, and compositional image generation over strong baselines. Register slots add negligible overhead, keeping CODA efficient and scalable. These results indicate potential applications of CODA as an effective framework for robust OCL in complex, real-world scenes.
PAVAS: Physics-Aware Video-to-Audio Synthesis
Dec 09, 2025



Recent advances in Video-to-Audio (V2A) generation have achieved impressive perceptual quality and temporal synchronization, yet most models remain appearance-driven, capturing visual-acoustic correlations without considering the physical factors that shape real-world sounds. We present Physics-Aware Video-to-Audio Synthesis (PAVAS), a method that incorporates physical reasoning into a latent diffusion-based V2A generation through the Physics-Driven Audio Adapter (Phy-Adapter). The adapter receives object-level physical parameters estimated by the Physical Parameter Estimator (PPE), which uses a Vision-Language Model (VLM) to infer the moving-object mass and a segmentation-based dynamic 3D reconstruction module to recover its motion trajectory for velocity computation. These physical cues enable the model to synthesize sounds that reflect underlying physical factors. To assess physical realism, we curate VGG-Impact, a benchmark focusing on object-object interactions, and introduce Audio-Physics Correlation Coefficient (APCC), an evaluation metric that measures consistency between physical and auditory attributes. Comprehensive experiments show that PAVAS produces physically plausible and perceptually coherent audio, outperforming existing V2A models in both quantitative and qualitative evaluations. Visit https://physics-aware-video-to-audio-synthesis.github.io for demo videos.
Demystifying MaskGIT Sampler and Beyond: Adaptive Order Selection in Masked Diffusion
Oct 06, 2025Masked diffusion models have shown promising performance in generating high-quality samples in a wide range of domains, but accelerating their sampling process remains relatively underexplored. To investigate efficient samplers for masked diffusion, this paper theoretically analyzes the MaskGIT sampler for image modeling, revealing its implicit temperature sampling mechanism. Through this analysis, we introduce the "moment sampler," an asymptotically equivalent but more tractable and interpretable alternative to MaskGIT, which employs a "choose-then-sample" approach by selecting unmasking positions before sampling tokens. In addition, we improve the efficiency of choose-then-sample algorithms through two key innovations: a partial caching technique for transformers that approximates longer sampling trajectories without proportional computational cost, and a hybrid approach formalizing the exploration-exploitation trade-off in adaptive unmasking. Experiments in image and text domains demonstrate our theory as well as the efficiency of our proposed methods, advancing both theoretical understanding and practical implementation of masked diffusion samplers.
SONA: Learning Conditional, Unconditional, and Mismatching-Aware Discriminator
Oct 06, 2025Deep generative models have made significant advances in generating complex content, yet conditional generation remains a fundamental challenge. Existing conditional generative adversarial networks often struggle to balance the dual objectives of assessing authenticity and conditional alignment of input samples within their conditional discriminators. To address this, we propose a novel discriminator design that integrates three key capabilities: unconditional discrimination, matching-aware supervision to enhance alignment sensitivity, and adaptive weighting to dynamically balance all objectives. Specifically, we introduce Sum of Naturalness and Alignment (SONA), which employs separate projections for naturalness (authenticity) and alignment in the final layer with an inductive bias, supported by dedicated objective functions and an adaptive weighting mechanism. Extensive experiments on class-conditional generation tasks show that \ours achieves superior sample quality and conditional alignment compared to state-of-the-art methods. Furthermore, we demonstrate its effectiveness in text-to-image generation, confirming the versatility and robustness of our approach.
Concept-TRAK: Understanding how diffusion models learn concepts through concept-level attribution
Jul 09, 2025



While diffusion models excel at image generation, their growing adoption raises critical concerns around copyright issues and model transparency. Existing attribution methods identify training examples influencing an entire image, but fall short in isolating contributions to specific elements, such as styles or objects, that matter most to stakeholders. To bridge this gap, we introduce \emph{concept-level attribution} via a novel method called \emph{Concept-TRAK}. Concept-TRAK extends influence functions with two key innovations: (1) a reformulated diffusion training loss based on diffusion posterior sampling, enabling robust, sample-specific attribution; and (2) a concept-aware reward function that emphasizes semantic relevance. We evaluate Concept-TRAK on the AbC benchmark, showing substantial improvements over prior methods. Through diverse case studies--ranging from identifying IP-protected and unsafe content to analyzing prompt engineering and compositional learning--we demonstrate how concept-level attribution yields actionable insights for responsible generative AI development and governance.
Denoising Multi-Beta VAE: Representation Learning for Disentanglement and Generation
Jul 09, 2025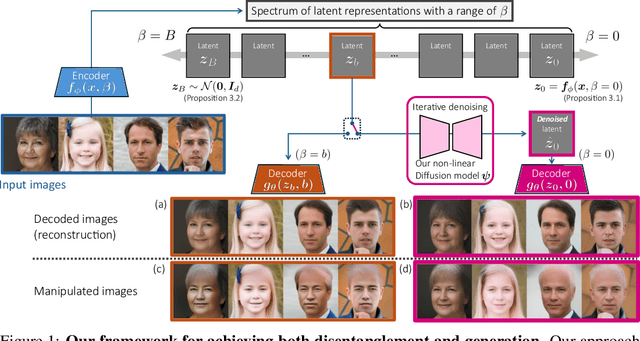



Disentangled and interpretable latent representations in generative models typically come at the cost of generation quality. The $\beta$-VAE framework introduces a hyperparameter $\beta$ to balance disentanglement and reconstruction quality, where setting $\beta > 1$ introduces an information bottleneck that favors disentanglement over sharp, accurate reconstructions. To address this trade-off, we propose a novel generative modeling framework that leverages a range of $\beta$ values to learn multiple corresponding latent representations. First, we obtain a slew of representations by training a single variational autoencoder (VAE), with a new loss function that controls the information retained in each latent representation such that the higher $\beta$ value prioritize disentanglement over reconstruction fidelity. We then, introduce a non-linear diffusion model that smoothly transitions latent representations corresponding to different $\beta$ values. This model denoises towards less disentangled and more informative representations, ultimately leading to (almost) lossless representations, enabling sharp reconstructions. Furthermore, our model supports sample generation without input images, functioning as a standalone generative model. We evaluate our framework in terms of both disentanglement and generation quality. Additionally, we observe smooth transitions in the latent spaces with respect to changes in $\beta$, facilitating consistent manipulation of generated outputs.
Forging and Removing Latent-Noise Diffusion Watermarks Using a Single Image
Apr 27, 2025Watermarking techniques are vital for protecting intellectual property and preventing fraudulent use of media. Most previous watermarking schemes designed for diffusion models embed a secret key in the initial noise. The resulting pattern is often considered hard to remove and forge into unrelated images. In this paper, we propose a black-box adversarial attack without presuming access to the diffusion model weights. Our attack uses only a single watermarked example and is based on a simple observation: there is a many-to-one mapping between images and initial noises. There are regions in the clean image latent space pertaining to each watermark that get mapped to the same initial noise when inverted. Based on this intuition, we propose an adversarial attack to forge the watermark by introducing perturbations to the images such that we can enter the region of watermarked images. We show that we can also apply a similar approach for watermark removal by learning perturbations to exit this region. We report results on multiple watermarking schemes (Tree-Ring, RingID, WIND, and Gaussian Shading) across two diffusion models (SDv1.4 and SDv2.0). Our results demonstrate the effectiveness of the attack and expose vulnerabilities in the watermarking methods, motivating future research on improving them.
Training Consistency Models with Variational Noise Coupling
Feb 25, 2025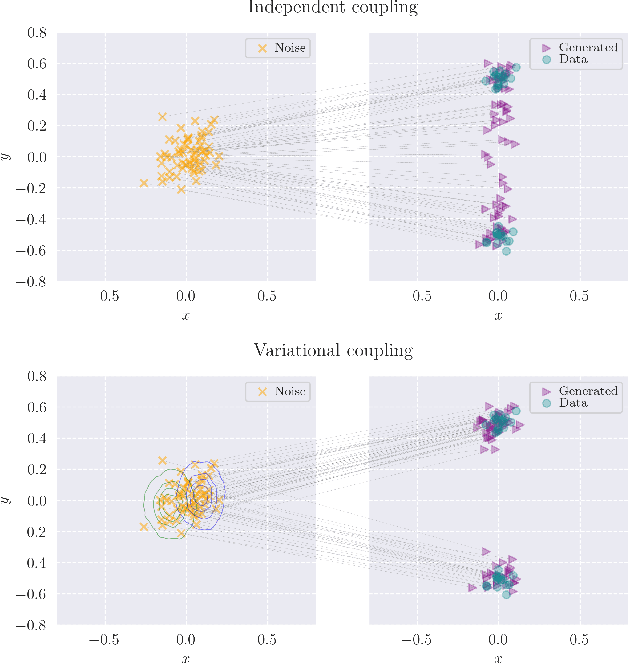



Consistency Training (CT) has recently emerged as a promising alternative to diffusion models, achieving competitive performance in image generation tasks. However, non-distillation consistency training often suffers from high variance and instability, and analyzing and improving its training dynamics is an active area of research. In this work, we propose a novel CT training approach based on the Flow Matching framework. Our main contribution is a trained noise-coupling scheme inspired by the architecture of Variational Autoencoders (VAE). By training a data-dependent noise emission model implemented as an encoder architecture, our method can indirectly learn the geometry of the noise-to-data mapping, which is instead fixed by the choice of the forward process in classical CT. Empirical results across diverse image datasets show significant generative improvements, with our model outperforming baselines and achieving the state-of-the-art (SoTA) non-distillation CT FID on CIFAR-10, and attaining FID on par with SoTA on ImageNet at $64 \times 64$ resolution in 2-step generation. Our code is available at https://github.com/sony/vct .
Transformed Low-rank Adaptation via Tensor Decomposition and Its Applications to Text-to-image Models
Jan 15, 2025
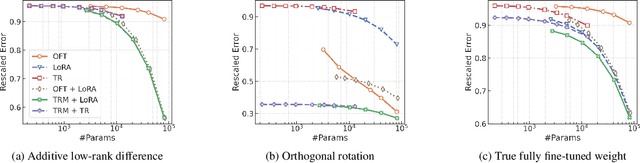
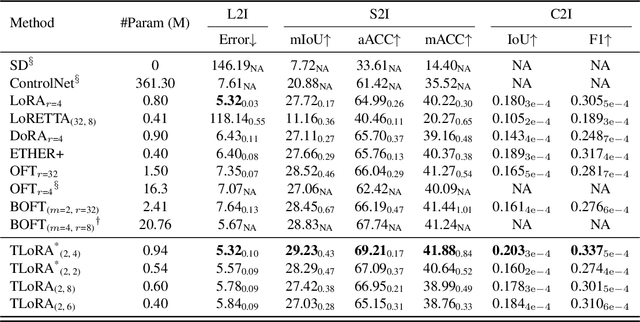
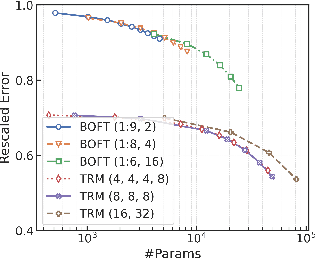
Parameter-Efficient Fine-Tuning (PEFT) of text-to-image models has become an increasingly popular technique with many applications. Among the various PEFT methods, Low-Rank Adaptation (LoRA) and its variants have gained significant attention due to their effectiveness, enabling users to fine-tune models with limited computational resources. However, the approximation gap between the low-rank assumption and desired fine-tuning weights prevents the simultaneous acquisition of ultra-parameter-efficiency and better performance. To reduce this gap and further improve the power of LoRA, we propose a new PEFT method that combines two classes of adaptations, namely, transform and residual adaptations. In specific, we first apply a full-rank and dense transform to the pre-trained weight. This learnable transform is expected to align the pre-trained weight as closely as possible to the desired weight, thereby reducing the rank of the residual weight. Then, the residual part can be effectively approximated by more compact and parameter-efficient structures, with a smaller approximation error. To achieve ultra-parameter-efficiency in practice, we design highly flexible and effective tensor decompositions for both the transform and residual adaptations. Additionally, popular PEFT methods such as DoRA can be summarized under this transform plus residual adaptation scheme. Experiments are conducted on fine-tuning Stable Diffusion models in subject-driven and controllable generation. The results manifest that our method can achieve better performances and parameter efficiency compared to LoRA and several baselines.