 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Speech Representation Aggregation in Speech Enhancement: A Phonetic Mutual Information Perspective
Jan 30, 2026Recent speech enhancement (SE) models increasingly leverage self-supervised learning (SSL) representations for their rich semantic information. Typically, intermediate features are aggregated into a single representation via a lightweight adaptation module. However, most SSL models are not trained for noise robustness, which can lead to corrupted semantic representations. Moreover, the adaptation module is trained jointly with the SE model, potentially prioritizing acoustic details over semantic information, contradicting the original purpose. To address this issue, we first analyze the behavior of SSL models on noisy speech from an information-theoretic perspective. Specifically, we measure the mutual information (MI) between the corrupted SSL representations and the corresponding phoneme labels, focusing on preservation of linguistic contents. Building upon this analysis, we introduce the linguistic aggregation layer, which is pre-trained to maximize MI with phoneme labels (with optional dynamic aggregation) and then frozen during SE training. Experiments show that this decoupled approach improves Word Error Rate (WER) over jointly optimized baselines, demonstrating the benefit of explicitly aligning the adaptation module with linguistic contents.
Differentiable Acoustic Radiance Transfer
Sep 19, 2025Geometric acoustics is an efficient approach to room acoustics modeling, governed by the canonical time-dependent rendering equation. Acoustic radiance transfer (ART) solves the equation through discretization, modeling the time- and direction-dependent energy exchange between surface patches given with flexible material properties. We introduce DART, a differentiable and efficient implementation of ART that enables gradient-based optimization of material properties. We evaluate DART on a simpler variant of the acoustic field learning task, which aims to predict the energy responses of novel source-receiver settings. Experimental results show that DART exhibits favorable properties, e.g., better generalization under a sparse measurement scenario, compared to existing signal processing and neural network baselines, while remaining a simple, fully interpretable system.
Reverse Engineering of Music Mixing Graphs with Differentiable Processors and Iterative Pruning
Sep 19, 2025



Reverse engineering of music mixes aims to uncover how dry source signals are processed and combined to produce a final mix. We extend the prior works to reflect the compositional nature of mixing and search for a graph of audio processors. First, we construct a mixing console, applying all available processors to every track and subgroup. With differentiable processor implementations, we optimize their parameters with gradient descent. Then, we repeat the process of removing negligible processors and fine-tuning the remaining ones. This way, the quality of the full mixing console can be preserved while removing approximately two-thirds of the processors. The proposed method can be used not only to analyze individual music mixes but also to collect large-scale graph data that can be used for downstream tasks, e.g., automatic mixing. Especially for the latter purpose, efficient implementation of the search is crucial. To this end, we present an efficient batch-processing method that computes multiple processors in parallel. We also exploit the "dry/wet" parameter of the processors to accelerate the search. Extensive quantitative and qualitative analyses are conducted to evaluate the proposed method's performance, behavior, and computational cost.
MGE-LDM: Joint Latent Diffusion for Simultaneous Music Generation and Source Extraction
May 29, 2025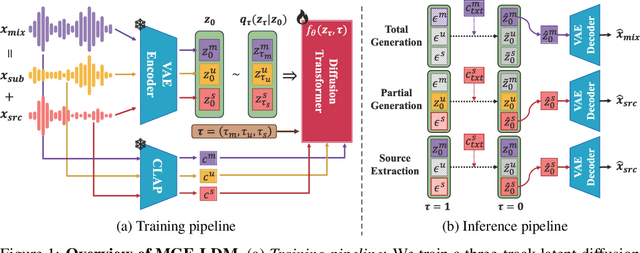
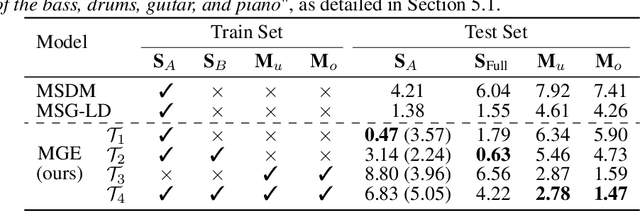

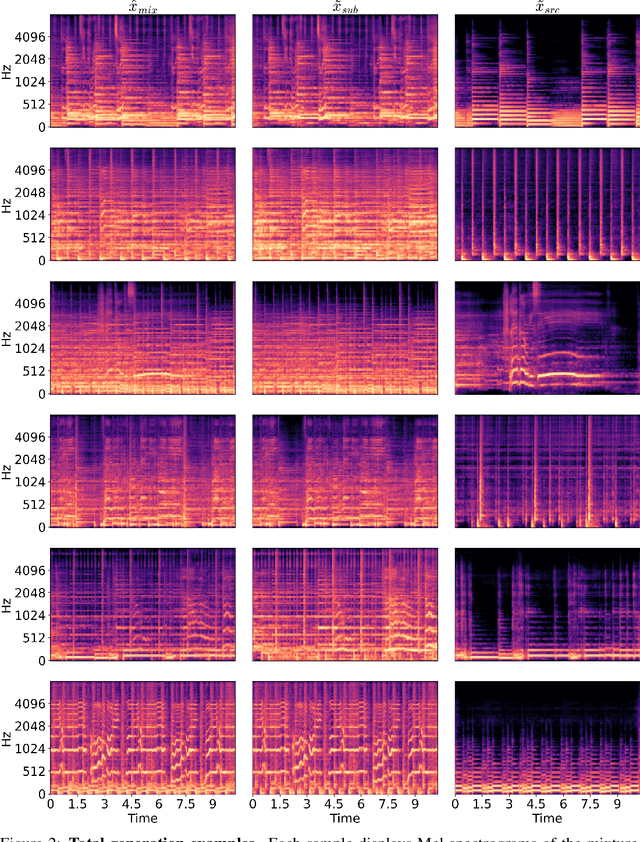
We present MGE-LDM, a unified latent diffusion framework for simultaneous music generation, source imputation, and query-driven source separation. Unlike prior approaches constrained to fixed instrument classes, MGE-LDM learns a joint distribution over full mixtures, submixtures, and individual stems within a single compact latent diffusion model. At inference, MGE-LDM enables (1) complete mixture generation, (2) partial generation (i.e., source imputation), and (3) text-conditioned extraction of arbitrary sources. By formulating both separation and imputation as conditional inpainting tasks in the latent space, our approach supports flexible, class-agnostic manipulation of arbitrary instrument sources. Notably, MGE-LDM can be trained jointly across heterogeneous multi-track datasets (e.g., Slakh2100, MUSDB18, MoisesDB) without relying on predefined instrument categories. Audio samples are available at our project page: https://yoongi43.github.io/MGELDM_Samples/.
DOSE : Drum One-Shot Extraction from Music Mixture
Apr 25, 2025Drum one-shot samples are crucial for music production, particularly in sound design and electronic music. This paper introduces Drum One-Shot Extraction, a task in which the goal is to extract drum one-shots that are present in the music mixture. To facilitate this, we propose the Random Mixture One-shot Dataset (RMOD), comprising large-scale, randomly arranged music mixtures paired with corresponding drum one-shot samples. Our proposed model, Drum One- Shot Extractor (DOSE), leverages neural audio codec language models for end-to-end extraction, bypassing traditional source separation steps. Additionally, we introduce a novel onset loss, designed to encourage accurate prediction of the initial transient of drum one-shots, which is essential for capturing timbral characteristics. We compare this approach against a source separation-based extraction method as a baseline. The results, evaluated using Frechet Audio Distance (FAD) and Multi-Scale Spectral loss (MSS), demonstrate that DOSE, enhanced with onset loss, outperforms the baseline, providing more accurate and higher-quality drum one-shots from music mixtures. The code, model checkpoint, and audio examples are available at https://github.com/HSUNEH/DOSE
TokenSynth: A Token-based Neural Synthesizer for Instrument Cloning and Text-to-Instrument
Feb 13, 2025Recent advancements in neural audio codecs have enabled the use of tokenized audio representations in various audio generation tasks, such as text-to-speech, text-to-audio, and text-to-music generation. Leveraging this approach, we propose TokenSynth, a novel neural synthesizer that utilizes a decoder-only transformer to generate desired audio tokens from MIDI tokens and CLAP (Contrastive Language-Audio Pretraining) embedding, which has timbre-related information. Our model is capable of performing instrument cloning, text-to-instrument synthesis, and text-guided timbre manipulation without any fine-tuning. This flexibility enables diverse sound design and intuitive timbre control. We evaluated the quality of the synthesized audio, the timbral similarity between synthesized and target audio/text, and synthesis accuracy (i.e., how accurately it follows the input MIDI) using objective measures. TokenSynth demonstrates the potential of leveraging advanced neural audio codecs and transformers to create powerful and versatile neural synthesizers. The source code, model weights, and audio demos are available at: https://github.com/KyungsuKim42/tokensynth
Song Form-aware Full-Song Text-to-Lyrics Generation with Multi-Level Granularity Syllable Count Control
Nov 20, 2024Lyrics generation presents unique challenges, particularly in achieving precise syllable control while adhering to song form structures such as verses and choruses. Conventional line-by-line approaches often lead to unnatural phrasing, underscoring the need for more granular syllable management. We propose a framework for lyrics generation that enables multi-level syllable control at the word, phrase, line, and paragraph levels, aware of song form. Our approach generates complete lyrics conditioned on input text and song form, ensuring alignment with specified syllable constraints. Generated lyrics samples are available at: https://tinyurl.com/lyrics9999
Do Captioning Metrics Reflect Music Semantic Alignment?
Nov 18, 2024Music captioning has emerged as a promising task, fueled by the advent of advanced language generation models. However, the evaluation of music captioning relies heavily on traditional metrics such as BLEU, METEOR, and ROUGE which were developed for other domains, without proper justification for their use in this new field. We present cases where traditional metrics are vulnerable to syntactic changes, and show they do not correlate well with human judgments. By addressing these issues, we aim to emphasize the need for a critical reevaluation of how music captions are assessed.
VRVQ: Variable Bitrate Residual Vector Quantization for Audio Compression
Oct 12, 2024Recent state-of-the-art neural audio compression models have progressively adopted residual vector quantization (RVQ). Despite this success, these models employ a fixed number of codebooks per frame, which can be suboptimal in terms of rate-distortion tradeoff, particularly in scenarios with simple input audio, such as silence. To address this limitation, we propose variable bitrate RVQ (VRVQ) for audio codecs, which allows for more efficient coding by adapting the number of codebooks used per frame. Furthermore, we propose a gradient estimation method for the non-differentiable masking operation that transforms from the importance map to the binary importance mask, improving model training via a straight-through estimator. We demonstrate that the proposed training framework achieves superior results compared to the baseline method and shows further improvement when applied to the current state-of-the-art codec.
Variable Bitrate Residual Vector Quantization for Audio Coding
Oct 08, 2024Recent state-of-the-art neural audio compression models have progressively adopted residual vector quantization (RVQ). Despite this success, these models employ a fixed number of codebooks per frame, which can be suboptimal in terms of rate-distortion tradeoff, particularly in scenarios with simple input audio, such as silence. To address this limitation, we propose variable bitrate RVQ (VRVQ) for audio codecs, which allows for more efficient coding by adapting the number of codebooks used per frame. Furthermore, we propose a gradient estimation method for the non-differentiable masking operation that transforms from the importance map to the binary importance mask, improving model training via a straight-through estimator. We demonstrate that the proposed training framework achieves superior results compared to the baseline method and shows further improvement when applied to the current state-of-the-art codec.