 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReverse Engineering of Music Mixing Graphs with Differentiable Processors and Iterative Pruning
Sep 19, 2025



Reverse engineering of music mixes aims to uncover how dry source signals are processed and combined to produce a final mix. We extend the prior works to reflect the compositional nature of mixing and search for a graph of audio processors. First, we construct a mixing console, applying all available processors to every track and subgroup. With differentiable processor implementations, we optimize their parameters with gradient descent. Then, we repeat the process of removing negligible processors and fine-tuning the remaining ones. This way, the quality of the full mixing console can be preserved while removing approximately two-thirds of the processors. The proposed method can be used not only to analyze individual music mixes but also to collect large-scale graph data that can be used for downstream tasks, e.g., automatic mixing. Especially for the latter purpose, efficient implementation of the search is crucial. To this end, we present an efficient batch-processing method that computes multiple processors in parallel. We also exploit the "dry/wet" parameter of the processors to accelerate the search. Extensive quantitative and qualitative analyses are conducted to evaluate the proposed method's performance, behavior, and computational cost.
GENIE-ASI: Generative Instruction and Executable Code for Analog Subcircuit Identification
Aug 26, 2025Analog subcircuit identification is a core task in analog design, essential for simulation, sizing, and layout. Traditional methods often require extensive human expertise, rule-based encoding, or large labeled datasets. To address these challenges, we propose GENIE-ASI, the first training-free, large language model (LLM)-based methodology for analog subcircuit identification. GENIE-ASI operates in two phases: it first uses in-context learning to derive natural language instructions from a few demonstration examples, then translates these into executable Python code to identify subcircuits in unseen SPICE netlists. In addition, to evaluate LLM-based approaches systematically, we introduce a new benchmark composed of operational amplifier netlists (op-amps) that cover a wide range of subcircuit variants. Experimental results on the proposed benchmark show that GENIE-ASI matches rule-based performance on simple structures (F1-score = 1.0), remains competitive on moderate abstractions (F1-score = 0.81), and shows potential even on complex subcircuits (F1-score = 0.31). These findings demonstrate that LLMs can serve as adaptable, general-purpose tools in analog design automation, opening new research directions for foundation model applications in analog design automation.
Locality-aware Surrogates for Gradient-based Black-box Optimization
Jan 31, 2025In physics and engineering, many processes are modeled using non-differentiable black-box simulators, making the optimization of such functions particularly challenging. To address such cases, inspired by the Gradient Theorem, we propose locality-aware surrogate models for active model-based black-box optimization. We first establish a theoretical connection between gradient alignment and the minimization of a Gradient Path Integral Equation (GradPIE) loss, which enforces consistency of the surrogate's gradients in local regions of the design space. Leveraging this theoretical insight, we develop a scalable training algorithm that minimizes the GradPIE loss, enabling both offline and online learning while maintaining computational efficiency. We evaluate our approach on three real-world tasks - spanning automated in silico experiments such as coupled nonlinear oscillators, analog circuits, and optical systems - and demonstrate consistent improvements in optimization efficiency under limited query budgets. Our results offer dependable solutions for both offline and online optimization tasks where reliable gradient estimation is needed.
Schemato -- An LLM for Netlist-to-Schematic Conversion
Nov 21, 2024



Machine learning models are advancing circuit design, particularly in analog circuits. They typically generate netlists that lack human interpretability. This is a problem as human designers heavily rely on the interpretability of circuit diagrams or schematics to intuitively understand, troubleshoot, and develop designs. Hence, to integrate domain knowledge effectively, it is crucial to translate ML-generated netlists into interpretable schematics quickly and accurately. We propose Schemato, a large language model (LLM) for netlist-to-schematic conversion. In particular, we consider our approach in the two settings of converting netlists to .asc files for LTSpice and LATEX files for CircuiTikz schematics. Experiments on our circuit dataset show that Schemato achieves up to 93% compilation success rate for the netlist-to-LaTeX conversion task, surpassing the 26% rate scored by the state-of-the-art LLMs. Furthermore, our experiments show that Schemato generates schematics with a mean structural similarity index measure that is 3xhigher than the best performing LLMs, therefore closer to the reference human design.
GraCo -- A Graph Composer for Integrated Circuits
Nov 21, 2024



Designing integrated circuits involves substantial complexity, posing challenges in revealing its potential applications - from custom digital cells to analog circuits. Despite extensive research over the past decades in building versatile and automated frameworks, there remains open room to explore more computationally efficient AI-based solutions. This paper introduces the graph composer GraCo, a novel method for synthesizing integrated circuits using reinforcement learning (RL). GraCo learns to construct a graph step-by-step, which is then converted into a netlist and simulated with SPICE. We demonstrate that GraCo is highly configurable, enabling the incorporation of prior design knowledge into the framework. We formalize how this prior knowledge can be utilized and, in particular, show that applying consistency checks enhances the efficiency of the sampling process. To evaluate its performance, we compare GraCo to a random baseline, which is known to perform well for smaller design space problems. We demonstrate that GraCo can discover circuits for tasks such as generating standard cells, including the inverter and the two-input NAND (NAND2) gate. Compared to a random baseline, GraCo requires 5x fewer sampling steps to design an inverter and successfully synthesizes a NAND2 gate that is 2.5x faster.
Music Foundation Model as Generic Booster for Music Downstream Tasks
Nov 05, 2024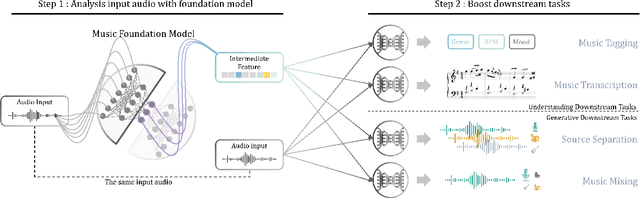

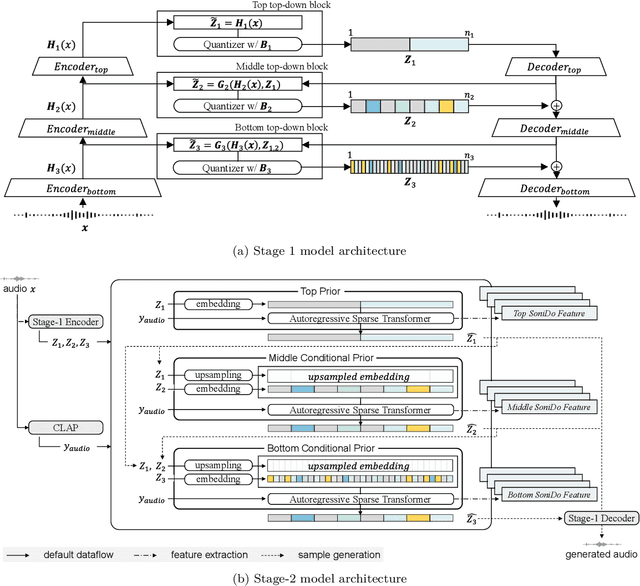

We demonstrate the efficacy of using intermediate representations from a single foundation model to enhance various music downstream tasks. We introduce SoniDo, a music foundation model (MFM) designed to extract hierarchical features from target music samples. By leveraging hierarchical intermediate features, SoniDo constrains the information granularity, leading to improved performance across various downstream tasks including both understanding and generative tasks. We specifically evaluated this approach on representative tasks such as music tagging, music transcription, music source separation, and music mixing. Our results reveal that the features extracted from foundation models provide valuable enhancements in training downstream task models. This highlights the capability of using features extracted from music foundation models as a booster for downstream tasks. Our approach not only benefits existing task-specific models but also supports music downstream tasks constrained by data scarcity. This paves the way for more effective and accessible music processing solutions.
Latent Diffusion Bridges for Unsupervised Musical Audio Timbre Transfer
Sep 09, 2024Music timbre transfer is a challenging task that involves modifying the timbral characteristics of an audio signal while preserving its melodic structure. In this paper, we propose a novel method based on dual diffusion bridges, trained using the CocoChorales Dataset, which consists of unpaired monophonic single-instrument audio data. Each diffusion model is trained on a specific instrument with a Gaussian prior. During inference, a model is designated as the source model to map the input audio to its corresponding Gaussian prior, and another model is designated as the target model to reconstruct the target audio from this Gaussian prior, thereby facilitating timbre transfer. We compare our approach against existing unsupervised timbre transfer models such as VAEGAN and Gaussian Flow Bridges (GFB). Experimental results demonstrate that our method achieves both better Fr\'echet Audio Distance (FAD) and melody preservation, as reflected by lower pitch distances (DPD) compared to VAEGAN and GFB. Additionally, we discover that the noise level from the Gaussian prior, $\sigma$, can be adjusted to control the degree of melody preservation and amount of timbre transferred.
GRAFX: An Open-Source Library for Audio Processing Graphs in PyTorch
Aug 06, 2024


We present GRAFX, an open-source library designed for handling audio processing graphs in PyTorch. Along with various library functionalities, we describe technical details on the efficient parallel computation of input graphs, signals, and processor parameters in GPU. Then, we show its example use under a music mixing scenario, where parameters of every differentiable processor in a large graph are optimized via gradient descent. The code is available at https://github.com/sh-lee97/grafx.
SAFT: Towards Out-of-Distribution Generalization in Fine-Tuning
Jul 03, 2024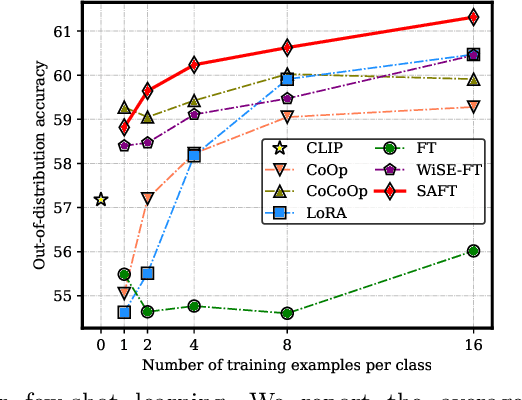
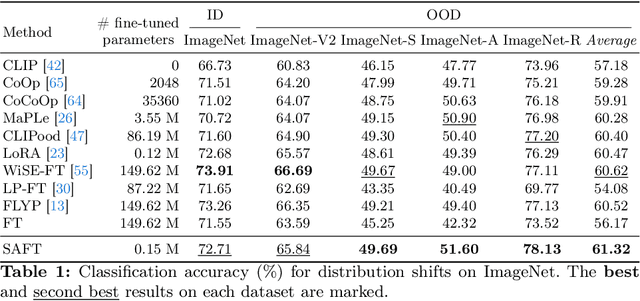
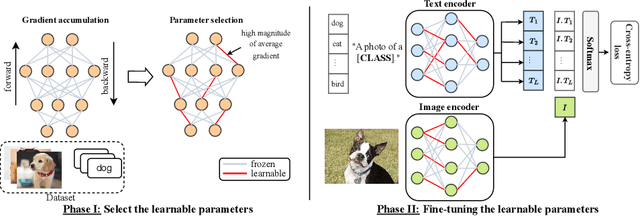
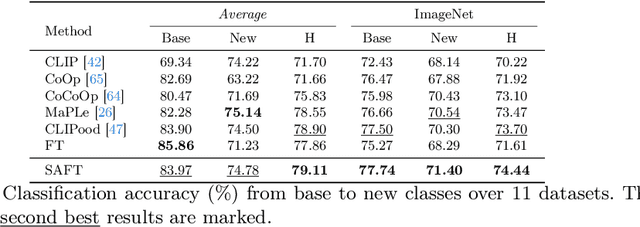
Handling distribution shifts from training data, known as out-of-distribution (OOD) generalization, poses a significant challenge in the field of machine learning. While a pre-trained vision-language model like CLIP has demonstrated remarkable zero-shot performance, further adaptation of the model to downstream tasks leads to undesirable degradation for OOD data. In this work, we introduce Sparse Adaptation for Fine-Tuning (SAFT), a method that prevents fine-tuning from forgetting the general knowledge in the pre-trained model. SAFT only updates a small subset of important parameters whose gradient magnitude is large, while keeping the other parameters frozen. SAFT is straightforward to implement and conceptually simple. Extensive experiments show that with only 0.1% of the model parameters, SAFT can significantly improve the performance of CLIP. It consistently outperforms baseline methods across several benchmarks. On the few-shot learning benchmark of ImageNet and its variants, SAFT gives a gain of 5.15% on average over the conventional fine-tuning method in OOD settings.
The Sound Demixing Challenge 2023 $\unicode{x2013}$ Music Demixing Track
Aug 14, 2023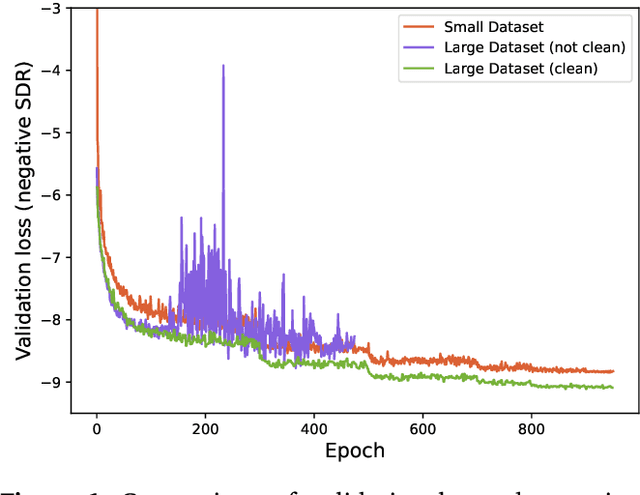
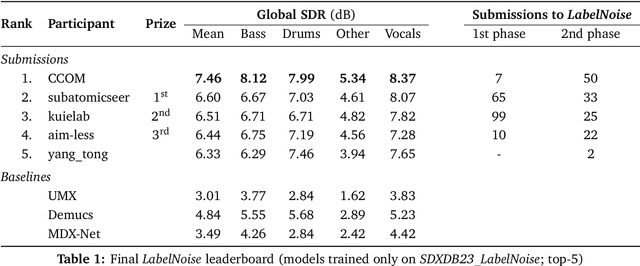

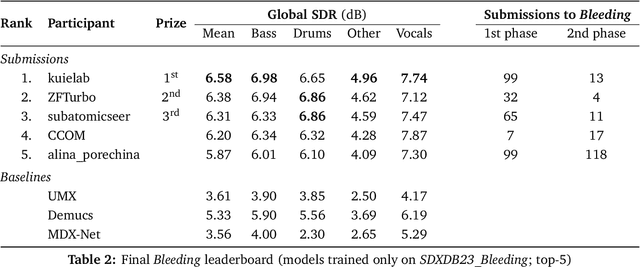
This paper summarizes the music demixing (MDX) track of the Sound Demixing Challenge (SDX'23). We provide a summary of the challenge setup and introduce the task of robust music source separation (MSS), i.e., training MSS models in the presence of errors in the training data. We propose a formalization of the errors that can occur in the design of a training dataset for MSS systems and introduce two new datasets that simulate such errors: SDXDB23_LabelNoise and SDXDB23_Bleeding1. We describe the methods that achieved the highest scores in the competition. Moreover, we present a direct comparison with the previous edition of the challenge (the Music Demixing Challenge 2021): the best performing system under the standard MSS formulation achieved an improvement of over 1.6dB in signal-to-distortion ratio over the winner of the previous competition, when evaluated on MDXDB21. Besides relying on the signal-to-distortion ratio as objective metric, we also performed a listening test with renowned producers/musicians to study the perceptual quality of the systems and report here the results. Finally, we provide our insights into the organization of the competition and our prospects for future editions.