 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Music Mixing using a Generative Model of Effect Embeddings
Nov 11, 2025Music mixing involves combining individual tracks into a cohesive mixture, a task characterized by subjectivity where multiple valid solutions exist for the same input. Existing automatic mixing systems treat this task as a deterministic regression problem, thus ignoring this multiplicity of solutions. Here we introduce MEGAMI (Multitrack Embedding Generative Auto MIxing), a generative framework that models the conditional distribution of professional mixes given unprocessed tracks. MEGAMI uses a track-agnostic effects processor conditioned on per-track generated embeddings, handles arbitrary unlabeled tracks through a permutation-equivariant architecture, and enables training on both dry and wet recordings via domain adaptation. Our objective evaluation using distributional metrics shows consistent improvements over existing methods, while listening tests indicate performances approaching human-level quality across diverse musical genres.
Concept-TRAK: Understanding how diffusion models learn concepts through concept-level attribution
Jul 09, 2025



While diffusion models excel at image generation, their growing adoption raises critical concerns around copyright issues and model transparency. Existing attribution methods identify training examples influencing an entire image, but fall short in isolating contributions to specific elements, such as styles or objects, that matter most to stakeholders. To bridge this gap, we introduce \emph{concept-level attribution} via a novel method called \emph{Concept-TRAK}. Concept-TRAK extends influence functions with two key innovations: (1) a reformulated diffusion training loss based on diffusion posterior sampling, enabling robust, sample-specific attribution; and (2) a concept-aware reward function that emphasizes semantic relevance. We evaluate Concept-TRAK on the AbC benchmark, showing substantial improvements over prior methods. Through diverse case studies--ranging from identifying IP-protected and unsafe content to analyzing prompt engineering and compositional learning--we demonstrate how concept-level attribution yields actionable insights for responsible generative AI development and governance.
SteerMusic: Enhanced Musical Consistency for Zero-shot Text-Guided and Personalized Music Editing
Apr 15, 2025Music editing is an important step in music production, which has broad applications, including game development and film production. Most existing zero-shot text-guided methods rely on pretrained diffusion models by involving forward-backward diffusion processes for editing. However, these methods often struggle to maintain the music content consistency. Additionally, text instructions alone usually fail to accurately describe the desired music. In this paper, we propose two music editing methods that enhance the consistency between the original and edited music by leveraging score distillation. The first method, SteerMusic, is a coarse-grained zero-shot editing approach using delta denoising score. The second method, SteerMusic+, enables fine-grained personalized music editing by manipulating a concept token that represents a user-defined musical style. SteerMusic+ allows for the editing of music into any user-defined musical styles that cannot be achieved by the text instructions alone. Experimental results show that our methods outperform existing approaches in preserving both music content consistency and editing fidelity. User studies further validate that our methods achieve superior music editing quality. Audio examples are available on https://steermusic.pages.dev/.
VRVQ: Variable Bitrate Residual Vector Quantization for Audio Compression
Oct 12, 2024Recent state-of-the-art neural audio compression models have progressively adopted residual vector quantization (RVQ). Despite this success, these models employ a fixed number of codebooks per frame, which can be suboptimal in terms of rate-distortion tradeoff, particularly in scenarios with simple input audio, such as silence. To address this limitation, we propose variable bitrate RVQ (VRVQ) for audio codecs, which allows for more efficient coding by adapting the number of codebooks used per frame. Furthermore, we propose a gradient estimation method for the non-differentiable masking operation that transforms from the importance map to the binary importance mask, improving model training via a straight-through estimator. We demonstrate that the proposed training framework achieves superior results compared to the baseline method and shows further improvement when applied to the current state-of-the-art codec.
Variable Bitrate Residual Vector Quantization for Audio Coding
Oct 08, 2024Recent state-of-the-art neural audio compression models have progressively adopted residual vector quantization (RVQ). Despite this success, these models employ a fixed number of codebooks per frame, which can be suboptimal in terms of rate-distortion tradeoff, particularly in scenarios with simple input audio, such as silence. To address this limitation, we propose variable bitrate RVQ (VRVQ) for audio codecs, which allows for more efficient coding by adapting the number of codebooks used per frame. Furthermore, we propose a gradient estimation method for the non-differentiable masking operation that transforms from the importance map to the binary importance mask, improving model training via a straight-through estimator. We demonstrate that the proposed training framework achieves superior results compared to the baseline method and shows further improvement when applied to the current state-of-the-art codec.
Latent Diffusion Bridges for Unsupervised Musical Audio Timbre Transfer
Sep 09, 2024Music timbre transfer is a challenging task that involves modifying the timbral characteristics of an audio signal while preserving its melodic structure. In this paper, we propose a novel method based on dual diffusion bridges, trained using the CocoChorales Dataset, which consists of unpaired monophonic single-instrument audio data. Each diffusion model is trained on a specific instrument with a Gaussian prior. During inference, a model is designated as the source model to map the input audio to its corresponding Gaussian prior, and another model is designated as the target model to reconstruct the target audio from this Gaussian prior, thereby facilitating timbre transfer. We compare our approach against existing unsupervised timbre transfer models such as VAEGAN and Gaussian Flow Bridges (GFB). Experimental results demonstrate that our method achieves both better Fr\'echet Audio Distance (FAD) and melody preservation, as reflected by lower pitch distances (DPD) compared to VAEGAN and GFB. Additionally, we discover that the noise level from the Gaussian prior, $\sigma$, can be adjusted to control the degree of melody preservation and amount of timbre transferred.
DisMix: Disentangling Mixtures of Musical Instruments for Source-level Pitch and Timbre Manipulation
Aug 20, 2024



Existing work on pitch and timbre disentanglement has been mostly focused on single-instrument music audio, excluding the cases where multiple instruments are presented. To fill the gap, we propose DisMix, a generative framework in which the pitch and timbre representations act as modular building blocks for constructing the melody and instrument of a source, and the collection of which forms a set of per-instrument latent representations underlying the observed mixture. By manipulating the representations, our model samples mixtures with novel combinations of pitch and timbre of the constituent instruments. We can jointly learn the disentangled pitch-timbre representations and a latent diffusion transformer that reconstructs the mixture conditioned on the set of source-level representations. We evaluate the model using both a simple dataset of isolated chords and a realistic four-part chorales in the style of J.S. Bach, identify the key components for the success of disentanglement, and demonstrate the application of mixture transformation based on source-level attribute manipulation.
Improving Unsupervised Clean-to-Rendered Guitar Tone Transformation Using GANs and Integrated Unaligned Clean Data
Jun 22, 2024



Recent years have seen increasing interest in applying deep learning methods to the modeling of guitar amplifiers or effect pedals. Existing methods are mainly based on the supervised approach, requiring temporally-aligned data pairs of unprocessed and rendered audio. However, this approach does not scale well, due to the complicated process involved in creating the data pairs. A very recent work done by Wright et al. has explored the potential of leveraging unpaired data for training, using a generative adversarial network (GAN)-based framework. This paper extends their work by using more advanced discriminators in the GAN, and using more unpaired data for training. Specifically, drawing inspiration from recent advancements in neural vocoders, we employ in our GAN-based model for guitar amplifier modeling two sets of discriminators, one based on multi-scale discriminator (MSD) and the other multi-period discriminator (MPD). Moreover, we experiment with adding unprocessed audio signals that do not have the corresponding rendered audio of a target tone to the training data, to see how much the GAN model benefits from the unpaired data. Our experiments show that the proposed two extensions contribute to the modeling of both low-gain and high-gain guitar amplifiers.
MR-MT3: Memory Retaining Multi-Track Music Transcription to Mitigate Instrument Leakage
Mar 15, 2024This paper presents enhancements to the MT3 model, a state-of-the-art (SOTA) token-based multi-instrument automatic music transcription (AMT) model. Despite SOTA performance, MT3 has the issue of instrument leakage, where transcriptions are fragmented across different instruments. To mitigate this, we propose MR-MT3, with enhancements including a memory retention mechanism, prior token sampling, and token shuffling are proposed. These methods are evaluated on the Slakh2100 dataset, demonstrating improved onset F1 scores and reduced instrument leakage. In addition to the conventional multi-instrument transcription F1 score, new metrics such as the instrument leakage ratio and the instrument detection F1 score are introduced for a more comprehensive assessment of transcription quality. The study also explores the issue of domain overfitting by evaluating MT3 on single-instrument monophonic datasets such as ComMU and NSynth. The findings, along with the source code, are shared to facilitate future work aimed at refining token-based multi-instrument AMT models.
Timbre-Trap: A Low-Resource Framework for Instrument-Agnostic Music Transcription
Sep 27, 2023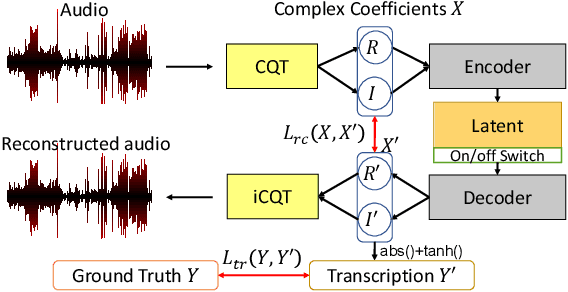
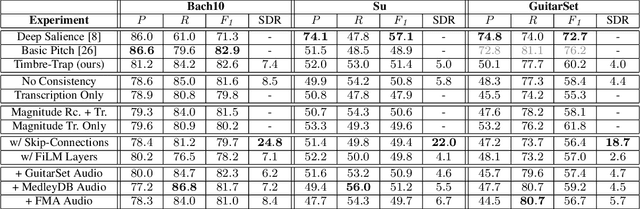
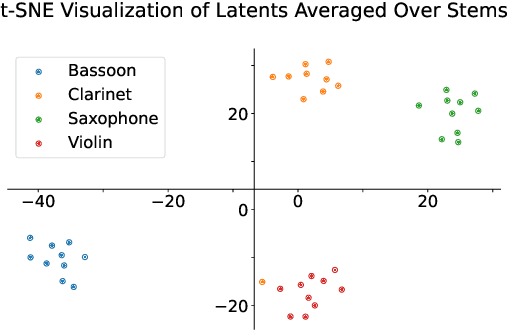
In recent years, research on music transcription has focused mainly on architecture design and instrument-specific data acquisition. With the lack of availability of diverse datasets, progress is often limited to solo-instrument tasks such as piano transcription. Several works have explored multi-instrument transcription as a means to bolster the performance of models on low-resource tasks, but these methods face the same data availability issues. We propose Timbre-Trap, a novel framework which unifies music transcription and audio reconstruction by exploiting the strong separability between pitch and timbre. We train a single U-Net to simultaneously estimate pitch salience and reconstruct complex spectral coefficients, selecting between either output during the decoding stage via a simple switch mechanism. In this way, the model learns to produce coefficients corresponding to timbre-less audio, which can be interpreted as pitch salience. We demonstrate that the framework leads to performance comparable to state-of-the-art instrument-agnostic transcription methods, while only requiring a small amount of annotated data.