 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMR-MT3: Memory Retaining Multi-Track Music Transcription to Mitigate Instrument Leakage
Mar 15, 2024This paper presents enhancements to the MT3 model, a state-of-the-art (SOTA) token-based multi-instrument automatic music transcription (AMT) model. Despite SOTA performance, MT3 has the issue of instrument leakage, where transcriptions are fragmented across different instruments. To mitigate this, we propose MR-MT3, with enhancements including a memory retention mechanism, prior token sampling, and token shuffling are proposed. These methods are evaluated on the Slakh2100 dataset, demonstrating improved onset F1 scores and reduced instrument leakage. In addition to the conventional multi-instrument transcription F1 score, new metrics such as the instrument leakage ratio and the instrument detection F1 score are introduced for a more comprehensive assessment of transcription quality. The study also explores the issue of domain overfitting by evaluating MT3 on single-instrument monophonic datasets such as ComMU and NSynth. The findings, along with the source code, are shared to facilitate future work aimed at refining token-based multi-instrument AMT models.
Semi-supervised music emotion recognition using noisy student training and harmonic pitch class profiles
Dec 09, 2021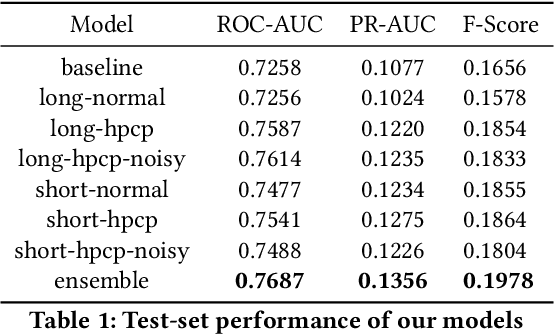
We present Mirable's submission to the 2021 Emotions and Themes in Music challenge. In this work, we intend to address the question: can we leverage semi-supervised learning techniques on music emotion recognition? With that, we experiment with noisy student training, which has improved model performance in the image classification domain. As the noisy student method requires a strong teacher model, we further delve into the factors including (i) input training length and (ii) complementary music representations to further boost the performance of the teacher model. For (i), we find that models trained with short input length perform better in PR-AUC, whereas those trained with long input length perform better in ROC-AUC. For (ii), we find that using harmonic pitch class profiles (HPCP) consistently improve tagging performance, which suggests that harmonic representation is useful for music emotion tagging. Finally, we find that noisy student method only improves tagging results for the case of long training length. Additionally, we find that ensembling representations trained with different training lengths can improve tagging results significantly, which suggest a possible direction to explore incorporating multiple temporal resolutions in the network architecture for future work.
Music FaderNets: Controllable Music Generation Based On High-Level Features via Low-Level Feature Modelling
Jul 29, 2020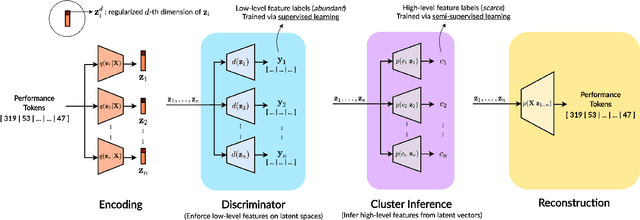
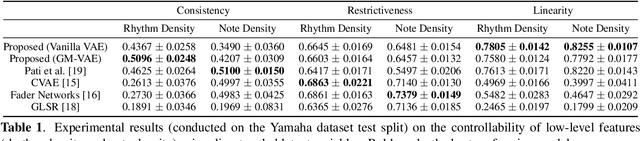
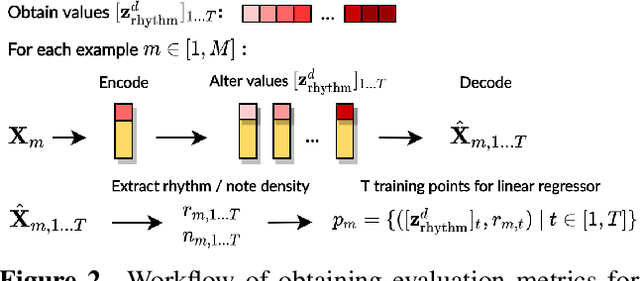
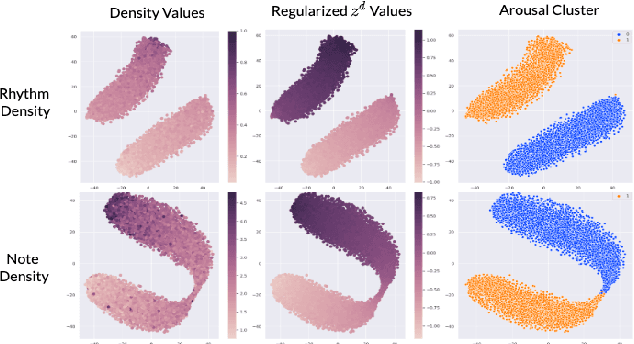
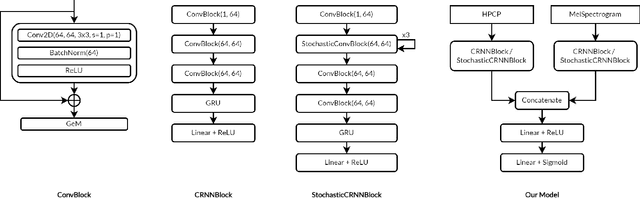
High-level musical qualities (such as emotion) are often abstract, subjective, and hard to quantify. Given these difficulties, it is not easy to learn good feature representations with supervised learning techniques, either because of the insufficiency of labels, or the subjectiveness (and hence large variance) in human-annotated labels. In this paper, we present a framework that can learn high-level feature representations with a limited amount of data, by first modelling their corresponding quantifiable low-level attributes. We refer to our proposed framework as Music FaderNets, which is inspired by the fact that low-level attributes can be continuously manipulated by separate "sliding faders" through feature disentanglement and latent regularization techniques. High-level features are then inferred from the low-level representations through semi-supervised clustering using Gaussian Mixture Variational Autoencoders (GM-VAEs). Using arousal as an example of a high-level feature, we show that the "faders" of our model are disentangled and change linearly w.r.t. the modelled low-level attributes of the generated output music. Furthermore, we demonstrate that the model successfully learns the intrinsic relationship between arousal and its corresponding low-level attributes (rhythm and note density), with only 1% of the training set being labelled. Finally, using the learnt high-level feature representations, we explore the application of our framework in style transfer tasks across different arousal states. The effectiveness of this approach is verified through a subjective listening test.
Generative Modelling for Controllable Audio Synthesis of Expressive Piano Performance
Jul 13, 2020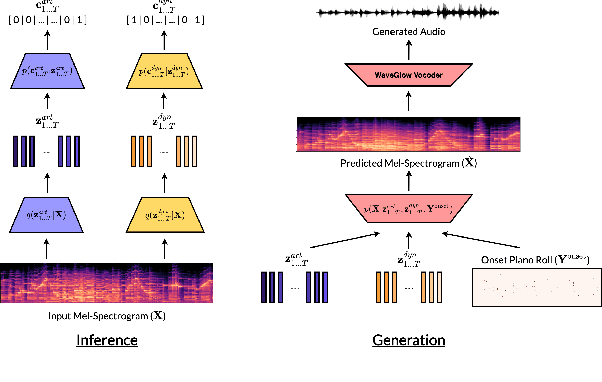
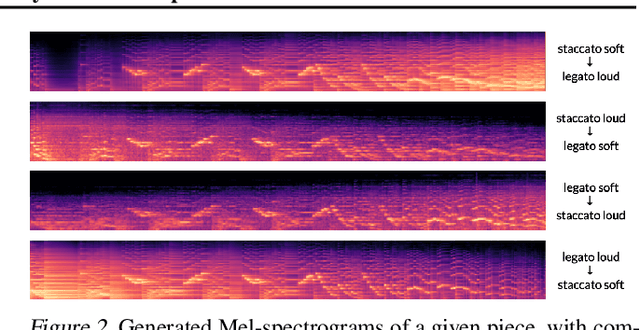
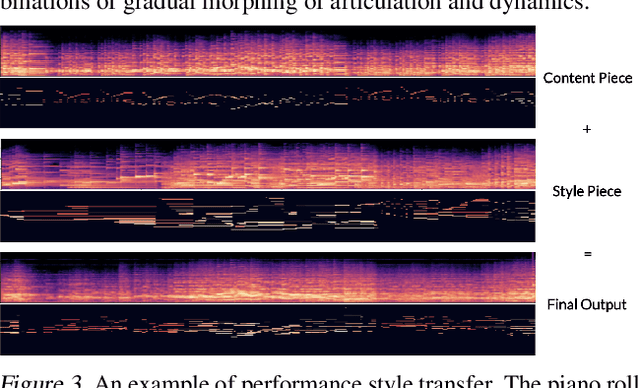
We present a controllable neural audio synthesizer based on Gaussian Mixture Variational Autoencoders (GM-VAE), which can generate realistic piano performances in the audio domain that closely follows temporal conditions of two essential style features for piano performances: articulation and dynamics. We demonstrate how the model is able to apply fine-grained style morphing over the course of synthesizing the audio. This is based on conditions which are latent variables that can be sampled from the prior or inferred from other pieces. One of the envisioned use cases is to inspire creative and brand new interpretations for existing pieces of piano music.