 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisMix: Disentangling Mixtures of Musical Instruments for Source-level Pitch and Timbre Manipulation
Aug 20, 2024



Existing work on pitch and timbre disentanglement has been mostly focused on single-instrument music audio, excluding the cases where multiple instruments are presented. To fill the gap, we propose DisMix, a generative framework in which the pitch and timbre representations act as modular building blocks for constructing the melody and instrument of a source, and the collection of which forms a set of per-instrument latent representations underlying the observed mixture. By manipulating the representations, our model samples mixtures with novel combinations of pitch and timbre of the constituent instruments. We can jointly learn the disentangled pitch-timbre representations and a latent diffusion transformer that reconstructs the mixture conditioned on the set of source-level representations. We evaluate the model using both a simple dataset of isolated chords and a realistic four-part chorales in the style of J.S. Bach, identify the key components for the success of disentanglement, and demonstrate the application of mixture transformation based on source-level attribute manipulation.
Towards Robust Unsupervised Disentanglement of Sequential Data -- A Case Study Using Music Audio
May 12, 2022



Disentangled sequential autoencoders (DSAEs) represent a class of probabilistic graphical models that describes an observed sequence with dynamic latent variables and a static latent variable. The former encode information at a frame rate identical to the observation, while the latter globally governs the entire sequence. This introduces an inductive bias and facilitates unsupervised disentanglement of the underlying local and global factors. In this paper, we show that the vanilla DSAE suffers from being sensitive to the choice of model architecture and capacity of the dynamic latent variables, and is prone to collapse the static latent variable. As a countermeasure, we propose TS-DSAE, a two-stage training framework that first learns sequence-level prior distributions, which are subsequently employed to regularise the model and facilitate auxiliary objectives to promote disentanglement. The proposed framework is fully unsupervised and robust against the global factor collapse problem across a wide range of model configurations. It also avoids typical solutions such as adversarial training which usually involves laborious parameter tuning, and domain-specific data augmentation. We conduct quantitative and qualitative evaluations to demonstrate its robustness in terms of disentanglement on both artificial and real-world music audio datasets.
Omnizart: A General Toolbox for Automatic Music Transcription
Jun 01, 2021We present and release Omnizart, a new Python library that provides a streamlined solution to automatic music transcription (AMT). Omnizart encompasses modules that construct the life-cycle of deep learning-based AMT, and is designed for ease of use with a compact command-line interface. To the best of our knowledge, Omnizart is the first transcription toolkit which offers models covering a wide class of instruments ranging from solo, instrument ensembles, percussion instruments to vocal, as well as models for chord recognition and beat/downbeat tracking, two music information retrieval (MIR) tasks highly related to AMT.
Revisiting the Onsets and Frames Model with Additive Attention
Apr 14, 2021



Recent advances in automatic music transcription (AMT) have achieved highly accurate polyphonic piano transcription results by incorporating onset and offset detection. The existing literature, however, focuses mainly on the leverage of deep and complex models to achieve state-of-the-art (SOTA) accuracy, without understanding model behaviour. In this paper, we conduct a comprehensive examination of the Onsets-and-Frames AMT model, and pinpoint the essential components contributing to a strong AMT performance. This is achieved through exploitation of a modified additive attention mechanism. The experimental results suggest that the attention mechanism beyond a moderate temporal context does not benefit the model, and that rule-based post-processing is largely responsible for the SOTA performance. We also demonstrate that the onsets are the most significant attentive feature regardless of model complexity. The findings encourage AMT research to weigh more on both a robust onset detector and an effective post-processor.
The Effect of Spectrogram Reconstruction on Automatic Music Transcription: An Alternative Approach to Improve Transcription Accuracy
Oct 20, 2020



Most of the state-of-the-art automatic music transcription (AMT) models break down the main transcription task into sub-tasks such as onset prediction and offset prediction and train them with onset and offset labels. These predictions are then concatenated together and used as the input to train another model with the pitch labels to obtain the final transcription. We attempt to use only the pitch labels (together with spectrogram reconstruction loss) and explore how far this model can go without introducing supervised sub-tasks. In this paper, we do not aim at achieving state-of-the-art transcription accuracy, instead, we explore the effect that spectrogram reconstruction has on our AMT model. Our proposed model consists of two U-nets: the first U-net transcribes the spectrogram into a posteriorgram, and a second U-net transforms the posteriorgram back into a spectrogram. A reconstruction loss is applied between the original spectrogram and the reconstructed spectrogram to constrain the second U-net to focus only on reconstruction. We train our model on three different datasets: MAPS, MAESTRO, and MusicNet. Our experiments show that adding the reconstruction loss can generally improve the note-level transcription accuracy when compared to the same model without the reconstruction part. Moreover, it can also boost the frame-level precision to be higher than the state-of-the-art models. The feature maps learned by our U-net contain gridlike structures (not present in the baseline model) which implies that with the presence of the reconstruction loss, the model is probably trying to count along both the time and frequency axis, resulting in a higher note-level transcription accuracy.
Generative Modelling for Controllable Audio Synthesis of Expressive Piano Performance
Jul 13, 2020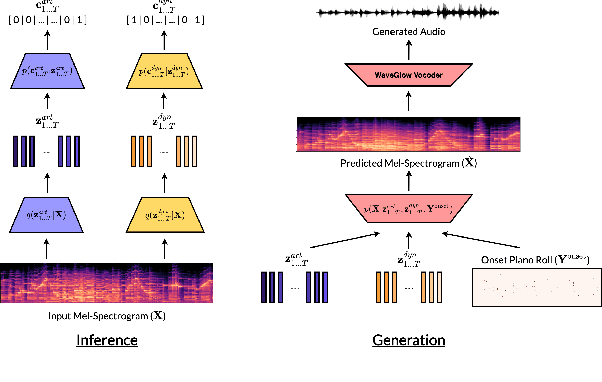
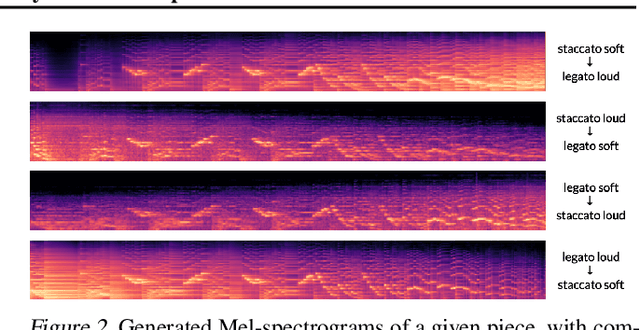
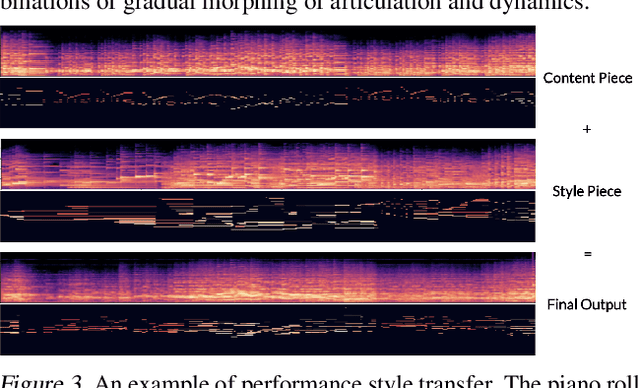
We present a controllable neural audio synthesizer based on Gaussian Mixture Variational Autoencoders (GM-VAE), which can generate realistic piano performances in the audio domain that closely follows temporal conditions of two essential style features for piano performances: articulation and dynamics. We demonstrate how the model is able to apply fine-grained style morphing over the course of synthesizing the audio. This is based on conditions which are latent variables that can be sampled from the prior or inferred from other pieces. One of the envisioned use cases is to inspire creative and brand new interpretations for existing pieces of piano music.
Singing Voice Conversion with Disentangled Representations of Singer and Vocal Technique Using Variational Autoencoders
Jan 28, 2020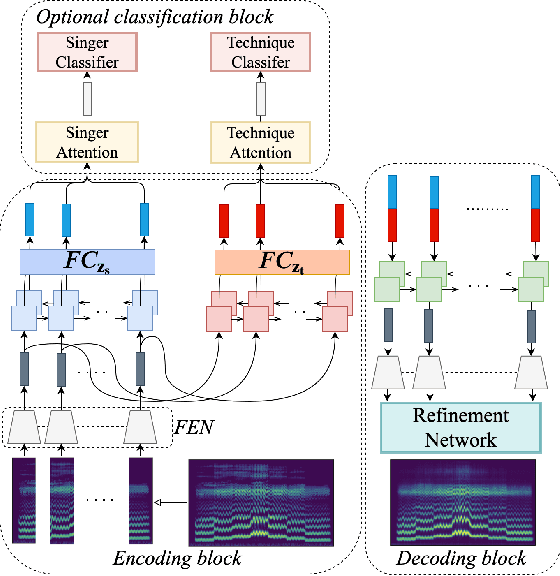

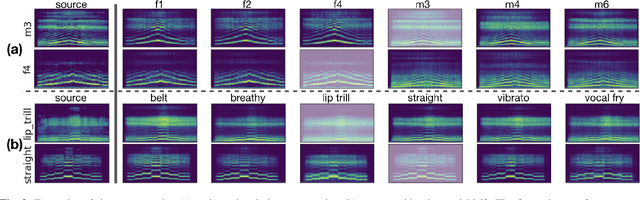
We propose a flexible framework that deals with both singer conversion and singers vocal technique conversion. The proposed model is trained on non-parallel corpora, accommodates many-to-many conversion, and leverages recent advances of variational autoencoders. It employs separate encoders to learn disentangled latent representations of singer identity and vocal technique separately, with a joint decoder for reconstruction. Conversion is carried out by simple vector arithmetic in the learned latent spaces. Both a quantitative analysis as well as a visualization of the converted spectrograms show that our model is able to disentangle singer identity and vocal technique and successfully perform conversion of these attributes. To the best of our knowledge, this is the first work to jointly tackle conversion of singer identity and vocal technique based on a deep learning approach.
Learning Disentangled Representations of Timbre and Pitch for Musical Instrument Sounds Using Gaussian Mixture Variational Autoencoders
Jun 29, 2019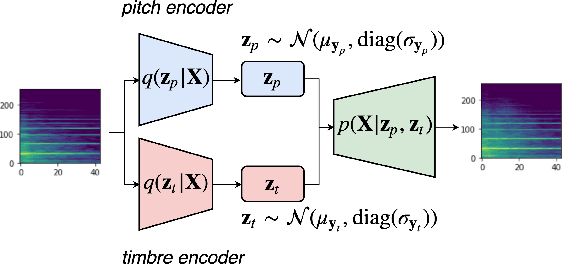
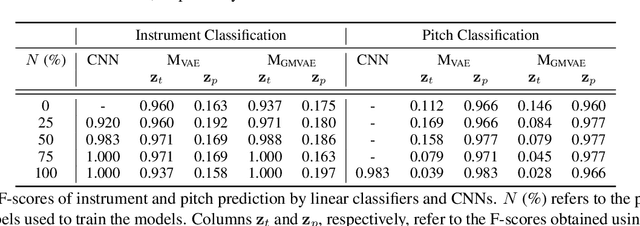

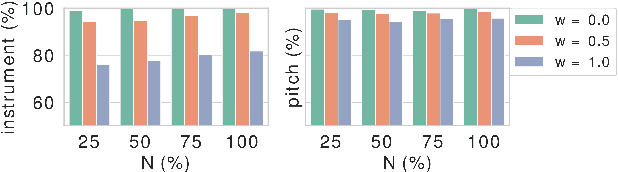
In this paper, we learn disentangled representations of timbre and pitch for musical instrument sounds. We adapt a framework based on variational autoencoders with Gaussian mixture latent distributions. Specifically, we use two separate encoders to learn distinct latent spaces for timbre and pitch, which form Gaussian mixture components representing instrument identity and pitch, respectively. For reconstruction, latent variables of timbre and pitch are sampled from corresponding mixture components, and are concatenated as the input to a decoder. We show the model efficacy by latent space visualization, and a quantitative analysis indicates the discriminability of these spaces, even with a limited number of instrument labels for training. The model allows for controllable synthesis of selected instrument sounds by sampling from the latent spaces. To evaluate this, we trained instrument and pitch classifiers using original labeled data. These classifiers achieve high accuracy when tested on our synthesized sounds, which verifies the model performance of controllable realistic timbre and pitch synthesis. Our model also enables timbre transfer between multiple instruments, with a single autoencoder architecture, which is evaluated by measuring the shift in posterior of instrument classification. Our in depth evaluation confirms the model ability to successfully disentangle timbre and pitch.