 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreak-the-Beat! Controllable MIDI-to-Drum Audio Synthesis
May 14, 2026Current methods for creating drum loop audio in digital music production, such as using one-shot samples or resampling, often demand non-trivial efforts of creators. While recent generative models achieve high fidelity and adhere to text, they lack the specific control needed for such a task. Existing symbolic-to-audio research often focuses on single, tonal instruments, leaving the challenge of polyphonic, percussive drum synthesis unaddressed. We address this gap by introducing ``Break-the-Beat!,'' a model capable of rendering a drum MIDI with the timbre of a reference audio. It is built by fine-tuning a pre-trained text-to-audio model with our proposed content encoder and a effective hybrid conditioning mechanism. To enable this, we construct a new dataset of paired target-reference drum audio from existing drum audio datasets. Experiments demonstrate that our model generates high-quality drum audio that follows high-resolution drum MIDI, achieving strong performance across metrics of audio quality, rhythmic alignment, and beat continuity. This offer producers a new, controllable tool for creative production. Demo page: https://ik4sumii.github.io/break-the-beat/
Do Foundational Audio Encoders Understand Music Structure?
Dec 19, 2025In music information retrieval (MIR) research, the use of pretrained foundational audio encoders (FAEs) has recently become a trend. FAEs pretrained on large amounts of music and audio data have been shown to improve performance on MIR tasks such as music tagging and automatic music transcription. However, their use for music structure analysis (MSA) remains underexplored. Although many open-source FAE models are available, only a small subset has been examined for MSA, and the impact of factors such as learning methods, training data, and model context length on MSA performance remains unclear. In this study, we conduct comprehensive experiments on 11 types of FAEs to investigate how these factors affect MSA performance. Our results demonstrate that FAEs using selfsupervised learning with masked language modeling on music data are particularly effective for MSA. These findings pave the way for future research in MSA.
SpecMaskFoley: Steering Pretrained Spectral Masked Generative Transformer Toward Synchronized Video-to-audio Synthesis via ControlNet
May 22, 2025



Foley synthesis aims to synthesize high-quality audio that is both semantically and temporally aligned with video frames. Given its broad application in creative industries, the task has gained increasing attention in the research community. To avoid the non-trivial task of training audio generative models from scratch, adapting pretrained audio generative models for video-synchronized foley synthesis presents an attractive direction. ControlNet, a method for adding fine-grained controls to pretrained generative models, has been applied to foley synthesis, but its use has been limited to handcrafted human-readable temporal conditions. In contrast, from-scratch models achieved success by leveraging high-dimensional deep features extracted using pretrained video encoders. We have observed a performance gap between ControlNet-based and from-scratch foley models. To narrow this gap, we propose SpecMaskFoley, a method that steers the pretrained SpecMaskGIT model toward video-synchronized foley synthesis via ControlNet. To unlock the potential of a single ControlNet branch, we resolve the discrepancy between the temporal video features and the time-frequency nature of the pretrained SpecMaskGIT via a frequency-aware temporal feature aligner, eliminating the need for complicated conditioning mechanisms widely used in prior arts. Evaluations on a common foley synthesis benchmark demonstrate that SpecMaskFoley could even outperform strong from-scratch baselines, substantially advancing the development of ControlNet-based foley synthesis models. Demo page: https://zzaudio.github.io/SpecMaskFoley_Demo/
Music Foundation Model as Generic Booster for Music Downstream Tasks
Nov 05, 2024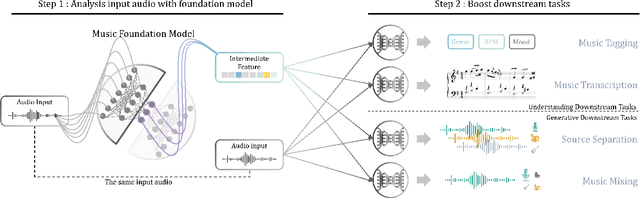


We demonstrate the efficacy of using intermediate representations from a single foundation model to enhance various music downstream tasks. We introduce SoniDo, a music foundation model (MFM) designed to extract hierarchical features from target music samples. By leveraging hierarchical intermediate features, SoniDo constrains the information granularity, leading to improved performance across various downstream tasks including both understanding and generative tasks. We specifically evaluated this approach on representative tasks such as music tagging, music transcription, music source separation, and music mixing. Our results reveal that the features extracted from foundation models provide valuable enhancements in training downstream task models. This highlights the capability of using features extracted from music foundation models as a booster for downstream tasks. Our approach not only benefits existing task-specific models but also supports music downstream tasks constrained by data scarcity. This paves the way for more effective and accessible music processing solutions.
DisMix: Disentangling Mixtures of Musical Instruments for Source-level Pitch and Timbre Manipulation
Aug 20, 2024



Existing work on pitch and timbre disentanglement has been mostly focused on single-instrument music audio, excluding the cases where multiple instruments are presented. To fill the gap, we propose DisMix, a generative framework in which the pitch and timbre representations act as modular building blocks for constructing the melody and instrument of a source, and the collection of which forms a set of per-instrument latent representations underlying the observed mixture. By manipulating the representations, our model samples mixtures with novel combinations of pitch and timbre of the constituent instruments. We can jointly learn the disentangled pitch-timbre representations and a latent diffusion transformer that reconstructs the mixture conditioned on the set of source-level representations. We evaluate the model using both a simple dataset of isolated chords and a realistic four-part chorales in the style of J.S. Bach, identify the key components for the success of disentanglement, and demonstrate the application of mixture transformation based on source-level attribute manipulation.
Timbre-Trap: A Low-Resource Framework for Instrument-Agnostic Music Transcription
Sep 27, 2023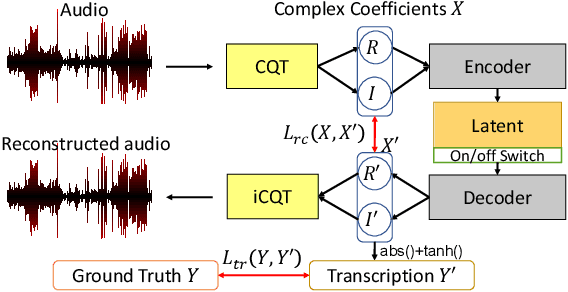
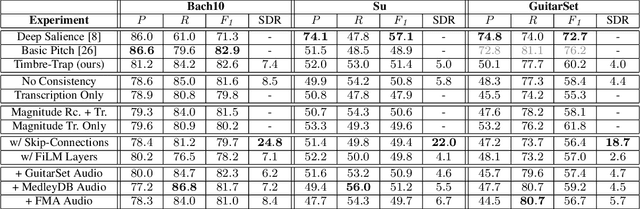
In recent years, research on music transcription has focused mainly on architecture design and instrument-specific data acquisition. With the lack of availability of diverse datasets, progress is often limited to solo-instrument tasks such as piano transcription. Several works have explored multi-instrument transcription as a means to bolster the performance of models on low-resource tasks, but these methods face the same data availability issues. We propose Timbre-Trap, a novel framework which unifies music transcription and audio reconstruction by exploiting the strong separability between pitch and timbre. We train a single U-Net to simultaneously estimate pitch salience and reconstruct complex spectral coefficients, selecting between either output during the decoding stage via a simple switch mechanism. In this way, the model learns to produce coefficients corresponding to timbre-less audio, which can be interpreted as pitch salience. We demonstrate that the framework leads to performance comparable to state-of-the-art instrument-agnostic transcription methods, while only requiring a small amount of annotated data.
Automatic Piano Transcription with Hierarchical Frequency-Time Transformer
Jul 10, 2023Taking long-term spectral and temporal dependencies into account is essential for automatic piano transcription. This is especially helpful when determining the precise onset and offset for each note in the polyphonic piano content. In this case, we may rely on the capability of self-attention mechanism in Transformers to capture these long-term dependencies in the frequency and time axes. In this work, we propose hFT-Transformer, which is an automatic music transcription method that uses a two-level hierarchical frequency-time Transformer architecture. The first hierarchy includes a convolutional block in the time axis, a Transformer encoder in the frequency axis, and a Transformer decoder that converts the dimension in the frequency axis. The output is then fed into the second hierarchy which consists of another Transformer encoder in the time axis. We evaluated our method with the widely used MAPS and MAESTRO v3.0.0 datasets, and it demonstrated state-of-the-art performance on all the F1-scores of the metrics among Frame, Note, Note with Offset, and Note with Offset and Velocity estimations.
E2E Refined Dataset
Nov 01, 2022



Although the well-known MR-to-text E2E dataset has been used by many researchers, its MR-text pairs include many deletion/insertion/substitution errors. Since such errors affect the quality of MR-to-text systems, they must be fixed as much as possible. Therefore, we developed a refined dataset and some python programs that convert the original E2E dataset into a refined dataset.