 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHARP 2.0: Expanding Hosted, Asynchronous, Remote Processing for Deep Learning in the DAW
Mar 04, 2025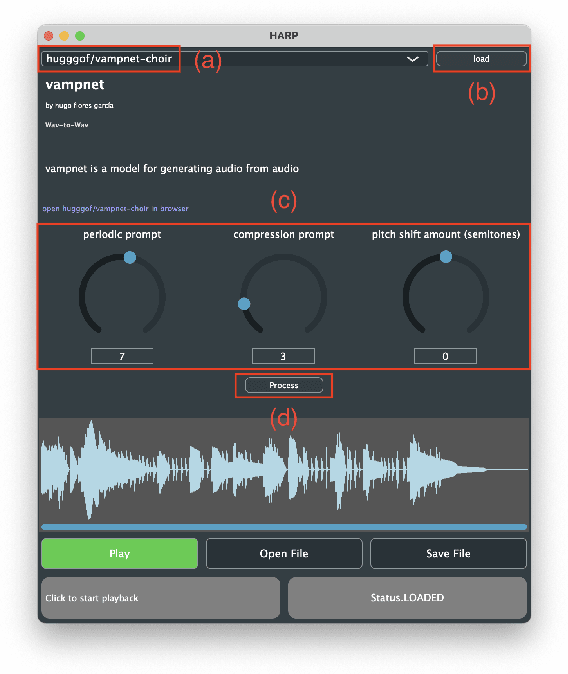
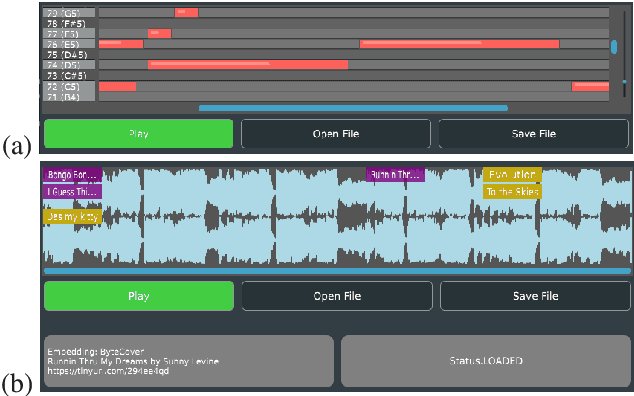
HARP 2.0 brings deep learning models to digital audio workstation (DAW) software through hosted, asynchronous, remote processing, allowing users to route audio from a plug-in interface through any compatible Gradio endpoint to perform arbitrary transformations. HARP renders endpoint-defined controls and processed audio in-plugin, meaning users can explore a variety of cutting-edge deep learning models without ever leaving the DAW. In the 2.0 release we introduce support for MIDI-based models and audio/MIDI labeling models, provide a streamlined pyharp Python API for model developers, and implement numerous interface and stability improvements. Through this work, we hope to bridge the gap between model developers and creatives, improving access to deep learning models by seamlessly integrating them into DAW workflows.
Toward Fully Self-Supervised Multi-Pitch Estimation
Feb 23, 2024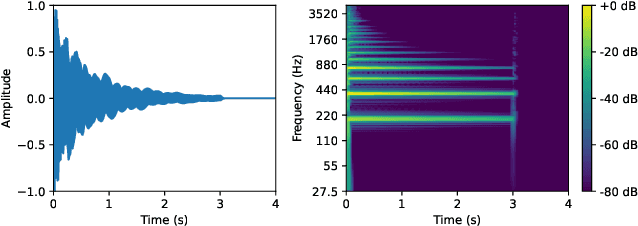
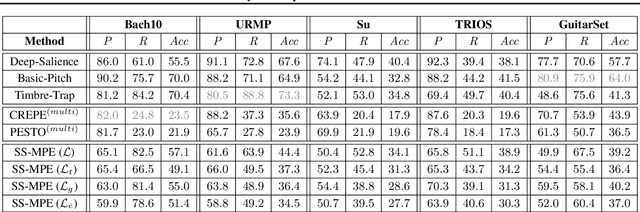
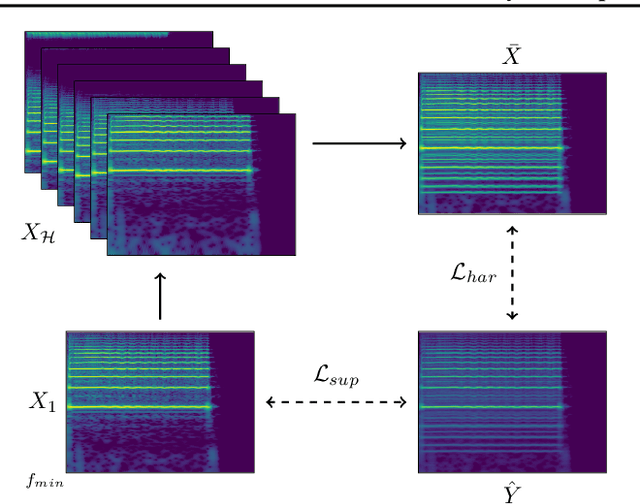
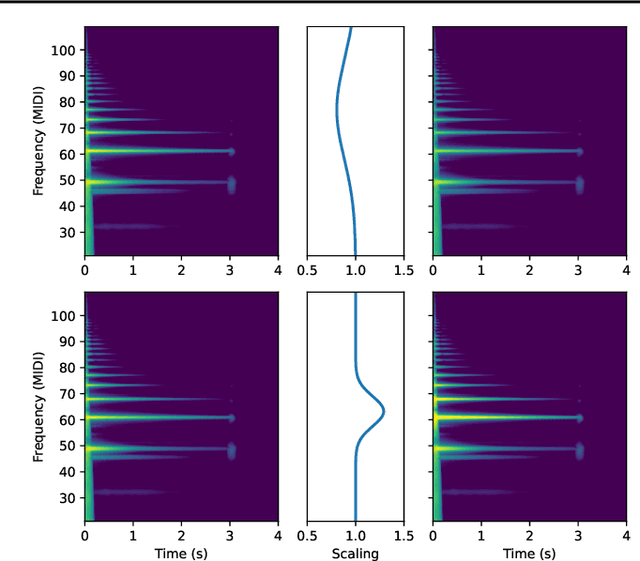
Multi-pitch estimation is a decades-long research problem involving the detection of pitch activity associated with concurrent musical events within multi-instrument mixtures. Supervised learning techniques have demonstrated solid performance on more narrow characterizations of the task, but suffer from limitations concerning the shortage of large-scale and diverse polyphonic music datasets with multi-pitch annotations. We present a suite of self-supervised learning objectives for multi-pitch estimation, which encourage the concentration of support around harmonics, invariance to timbral transformations, and equivariance to geometric transformations. These objectives are sufficient to train an entirely convolutional autoencoder to produce multi-pitch salience-grams directly, without any fine-tuning. Despite training exclusively on a collection of synthetic single-note audio samples, our fully self-supervised framework generalizes to polyphonic music mixtures, and achieves performance comparable to supervised models trained on conventional multi-pitch datasets.
Timbre-Trap: A Low-Resource Framework for Instrument-Agnostic Music Transcription
Sep 27, 2023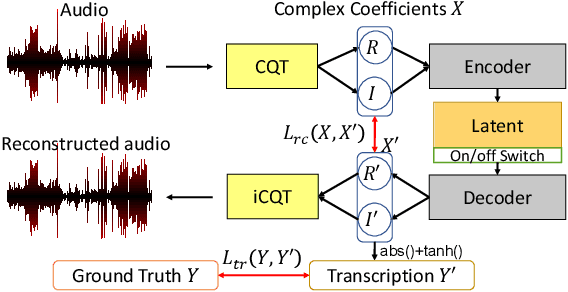
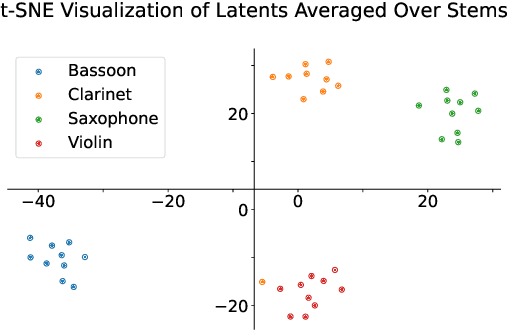
In recent years, research on music transcription has focused mainly on architecture design and instrument-specific data acquisition. With the lack of availability of diverse datasets, progress is often limited to solo-instrument tasks such as piano transcription. Several works have explored multi-instrument transcription as a means to bolster the performance of models on low-resource tasks, but these methods face the same data availability issues. We propose Timbre-Trap, a novel framework which unifies music transcription and audio reconstruction by exploiting the strong separability between pitch and timbre. We train a single U-Net to simultaneously estimate pitch salience and reconstruct complex spectral coefficients, selecting between either output during the decoding stage via a simple switch mechanism. In this way, the model learns to produce coefficients corresponding to timbre-less audio, which can be interpreted as pitch salience. We demonstrate that the framework leads to performance comparable to state-of-the-art instrument-agnostic transcription methods, while only requiring a small amount of annotated data.
SynthTab: Leveraging Synthesized Data for Guitar Tablature Transcription
Sep 22, 2023Guitar tablature is a form of music notation widely used among guitarists. It captures not only the musical content of a piece, but also its implementation and ornamentation on the instrument. Guitar Tablature Transcription (GTT) is an important task with broad applications in music education and entertainment. Existing datasets are limited in size and scope, causing state-of-the-art GTT models trained on such datasets to suffer from overfitting and to fail in generalization across datasets. To address this issue, we developed a methodology for synthesizing SynthTab, a large-scale guitar tablature transcription dataset using multiple commercial acoustic and electric guitar plugins. This dataset is built on tablatures from DadaGP, which offers a vast collection and the degree of specificity we wish to transcribe. The proposed synthesis pipeline produces audio which faithfully adheres to the original fingerings, styles, and techniques specified in the tablature with diverse timbre. Experiments show that pre-training state-of-the-art GTT model on SynthTab improves transcription accuracy in same-dataset tests. More importantly, it significantly mitigates overfitting problems of GTT models in cross-dataset evaluation.
FretNet: Continuous-Valued Pitch Contour Streaming for Polyphonic Guitar Tablature Transcription
Dec 06, 2022In recent years, the task of Automatic Music Transcription (AMT), whereby various attributes of music notes are estimated from audio, has received increasing attention. At the same time, the related task of Multi-Pitch Estimation (MPE) remains a challenging but necessary component of almost all AMT approaches, even if only implicitly. In the context of AMT, pitch information is typically quantized to the nominal pitches of the Western music scale. Even in more general contexts, MPE systems typically produce pitch predictions with some degree of quantization. In certain applications of AMT, such as Guitar Tablature Transcription (GTT), it is more meaningful to estimate continuous-valued pitch contours. Guitar tablature has the capacity to represent various playing techniques, some of which involve pitch modulation. Contemporary approaches to AMT do not adequately address pitch modulation, and offer only less quantization at the expense of more model complexity. In this paper, we present a GTT formulation that estimates continuous-valued pitch contours, grouping them according to their string and fret of origin. We demonstrate that for this task, the proposed method significantly improves the resolution of MPE and simultaneously yields tablature estimation results competitive with baseline models.
A Data-Driven Methodology for Considering Feasibility and Pairwise Likelihood in Deep Learning Based Guitar Tablature Transcription Systems
Apr 17, 2022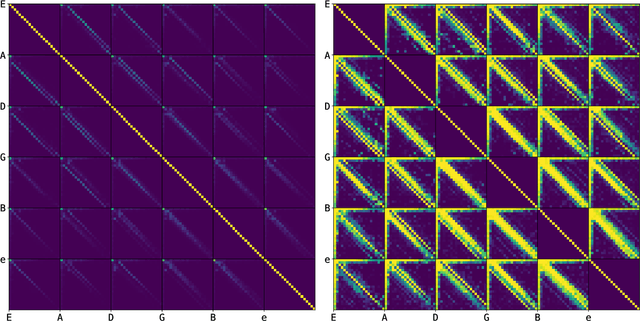
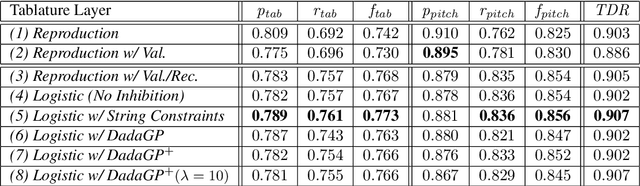
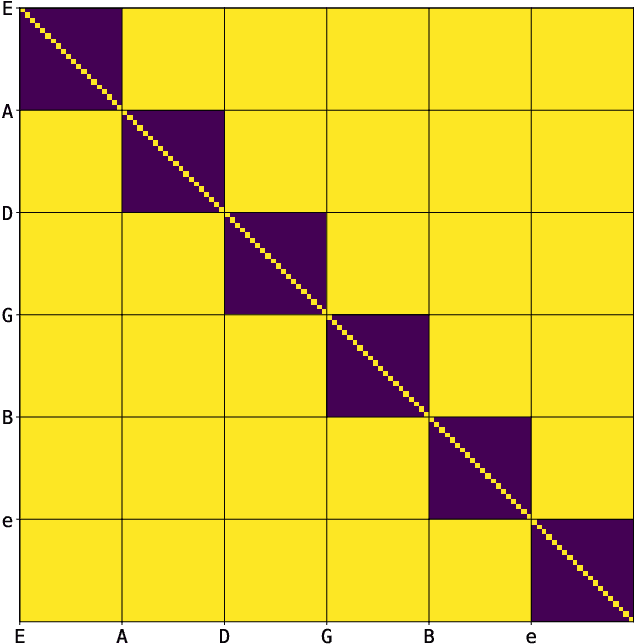
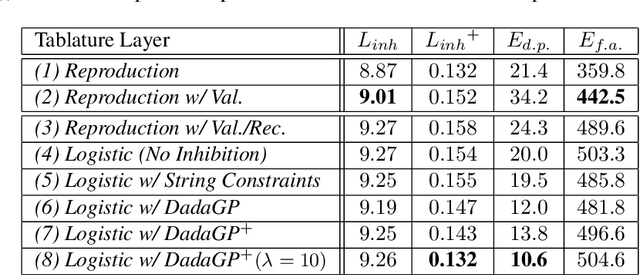
Guitar tablature transcription is an important but understudied problem within the field of music information retrieval. Traditional signal processing approaches offer only limited performance on the task, and there is little acoustic data with transcription labels for training machine learning models. However, guitar transcription labels alone are more widely available in the form of tablature, which is commonly shared among guitarists online. In this work, a collection of symbolic tablature is leveraged to estimate the pairwise likelihood of notes on the guitar. The output layer of a baseline tablature transcription model is reformulated, such that an inhibition loss can be incorporated to discourage the co-activation of unlikely note pairs. This naturally enforces playability constraints for guitar, and yields tablature which is more consistent with the symbolic data used to estimate pairwise likelihoods. With this methodology, we show that symbolic tablature can be used to shape the distribution of a tablature transcription model's predictions, even when little acoustic data is available.
A study of the robustness of raw waveform based speaker embeddings under mismatched conditions
Oct 11, 2021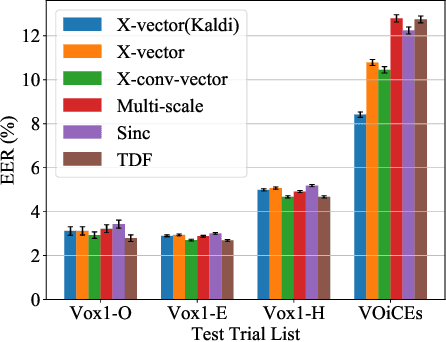
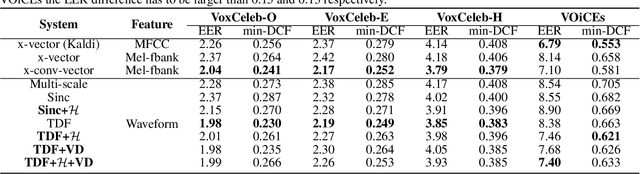
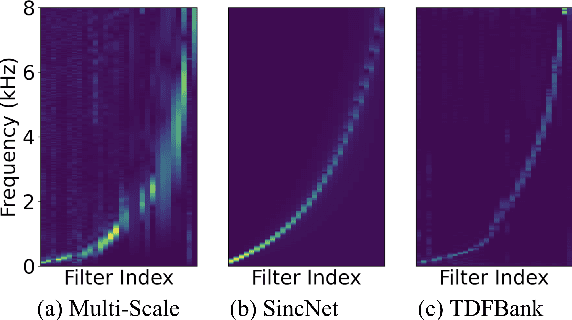
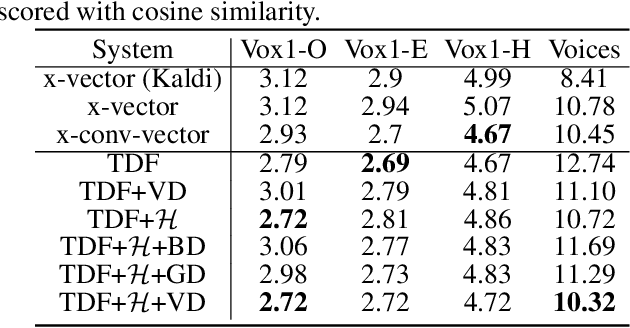
In this paper, we conduct a cross-dataset study on parametric and non-parametric raw-waveform based speaker embeddings through speaker verification experiments. In general, we observe a more significant performance degradation of these raw-waveform systems compared to spectral based systems. We then propose two strategies to improve the performance of raw-waveform based systems on cross-dataset tests. The first strategy is to change the real-valued filters into analytic filters to ensure shift-invariance. The second strategy is to apply variational dropout to non-parametric filters to prevent them from overfitting irrelevant nuance features.
Learning Sparse Analytic Filters for Piano Transcription
Aug 23, 2021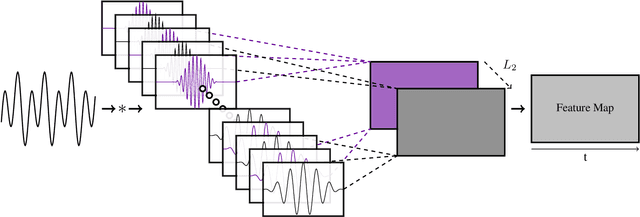
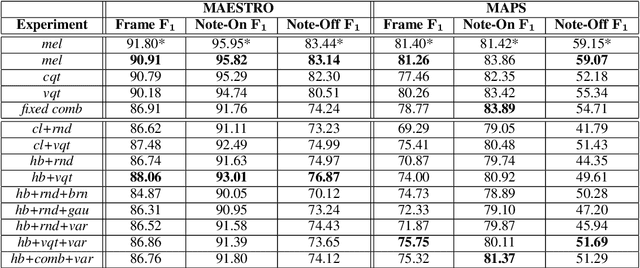
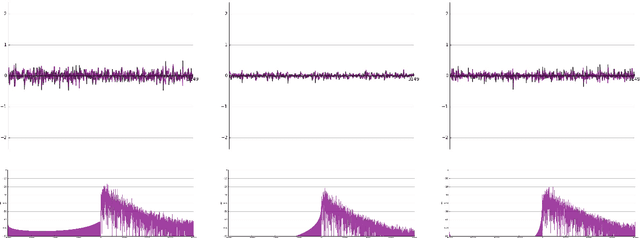
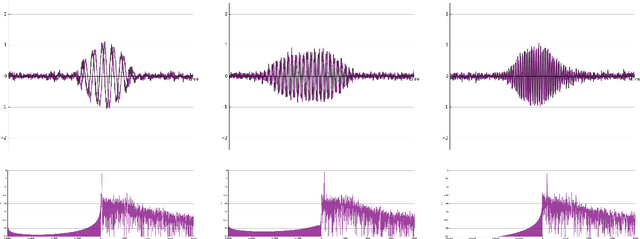
In recent years, filterbank learning has become an increasingly popular strategy for various audio-related machine learning tasks. This is partly due to its ability to discover task-specific audio characteristics which can be leveraged in downstream processing. It is also a natural extension of the nearly ubiquitous deep learning methods employed to tackle a diverse array of audio applications. In this work, several variations of a frontend filterbank learning module are investigated for piano transcription, a challenging low-level music information retrieval task. We build upon a standard piano transcription model, modifying only the feature extraction stage. The filterbank module is designed such that its complex filters are unconstrained 1D convolutional kernels with long receptive fields. Additional variations employ the Hilbert transform to render the filters intrinsically analytic and apply variational dropout to promote filterbank sparsity. Transcription results are compared across all experiments, and we offer visualization and analysis of the filterbanks.
BeatNet: CRNN and Particle Filtering for Online Joint Beat Downbeat and Meter Tracking
Aug 08, 2021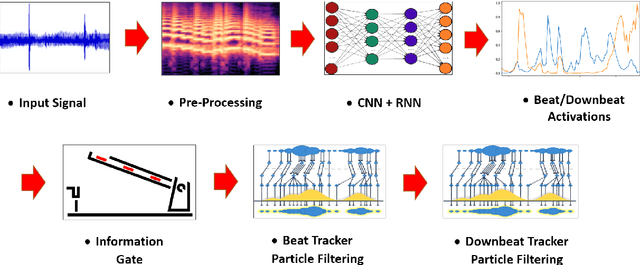
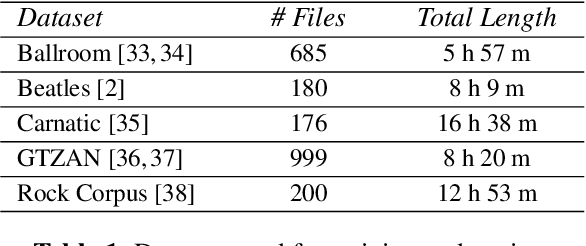
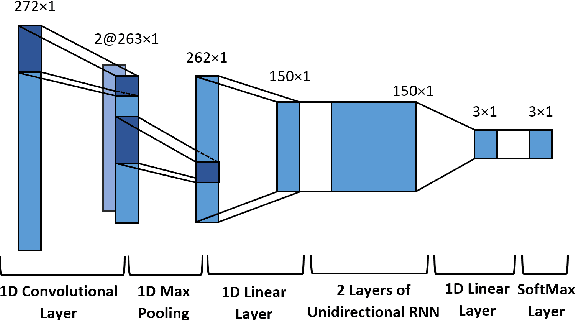
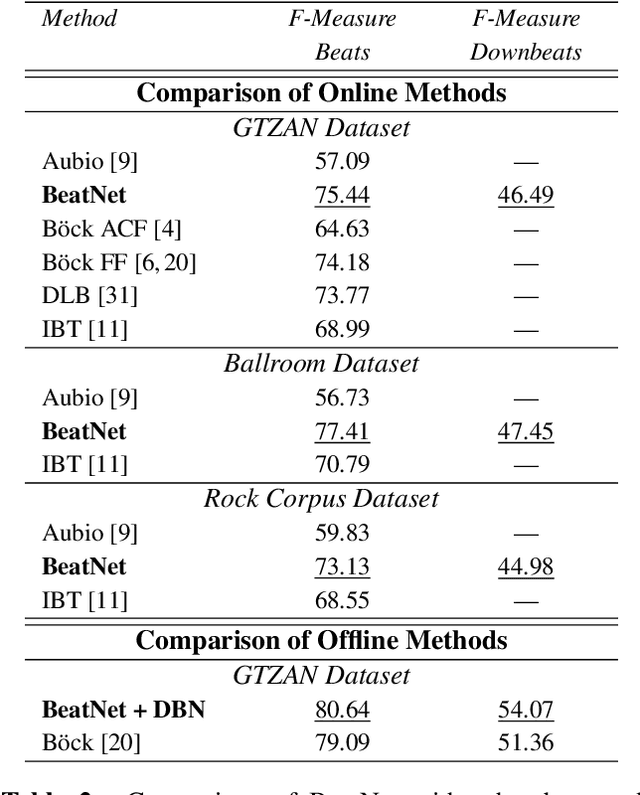
The online estimation of rhythmic information, such as beat positions, downbeat positions, and meter, is critical for many real-time music applications. Musical rhythm comprises complex hierarchical relationships across time, rendering its analysis intrinsically challenging and at times subjective. Furthermore, systems which attempt to estimate rhythmic information in real-time must be causal and must produce estimates quickly and efficiently. In this work, we introduce an online system for joint beat, downbeat, and meter tracking, which utilizes causal convolutional and recurrent layers, followed by a pair of sequential Monte Carlo particle filters applied during inference. The proposed system does not need to be primed with a time signature in order to perform downbeat tracking, and is instead able to estimate meter and adjust the predictions over time. Additionally, we propose an information gate strategy to significantly decrease the computational cost of particle filtering during the inference step, making the system much faster than previous sampling-based methods. Experiments on the GTZAN dataset, which is unseen during training, show that the system outperforms various online beat and downbeat tracking systems and achieves comparable performance to a baseline offline joint method.