 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Rhythm In Anything: Audio-Prompted Drums Generation with Masked Language Modeling
Sep 19, 2025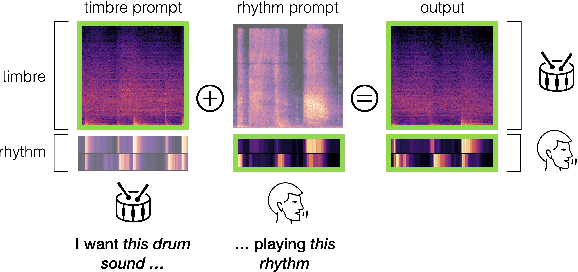
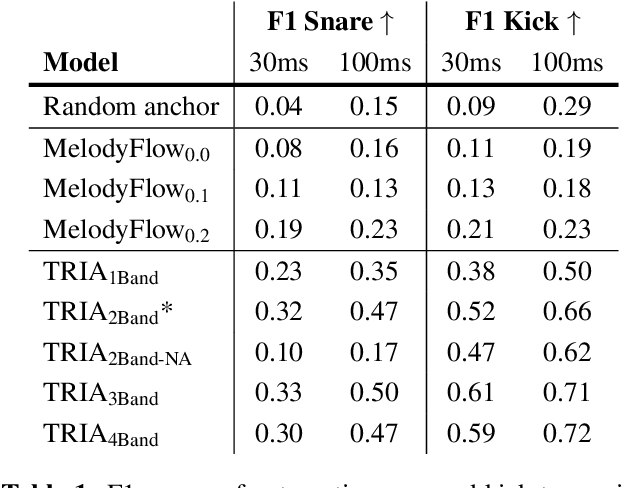
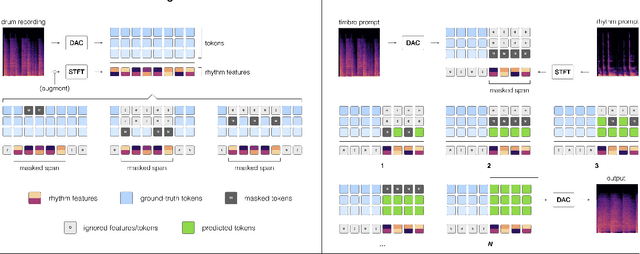
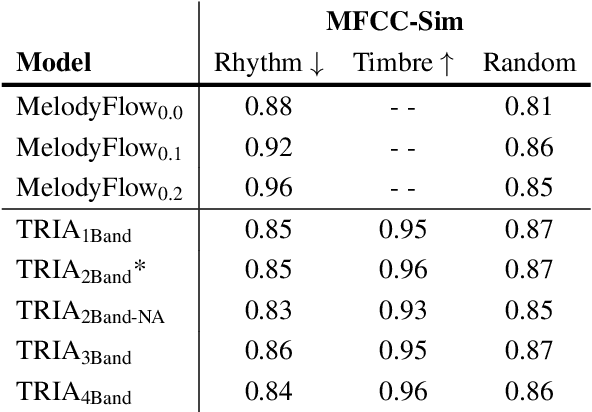
Musicians and nonmusicians alike use rhythmic sound gestures, such as tapping and beatboxing, to express drum patterns. While these gestures effectively communicate musical ideas, realizing these ideas as fully-produced drum recordings can be time-consuming, potentially disrupting many creative workflows. To bridge this gap, we present TRIA (The Rhythm In Anything), a masked transformer model for mapping rhythmic sound gestures to high-fidelity drum recordings. Given an audio prompt of the desired rhythmic pattern and a second prompt to represent drumkit timbre, TRIA produces audio of a drumkit playing the desired rhythm (with appropriate elaborations) in the desired timbre. Subjective and objective evaluations show that a TRIA model trained on less than 10 hours of publicly-available drum data can generate high-quality, faithful realizations of sound gestures across a wide range of timbres in a zero-shot manner.
HARP 2.0: Expanding Hosted, Asynchronous, Remote Processing for Deep Learning in the DAW
Mar 04, 2025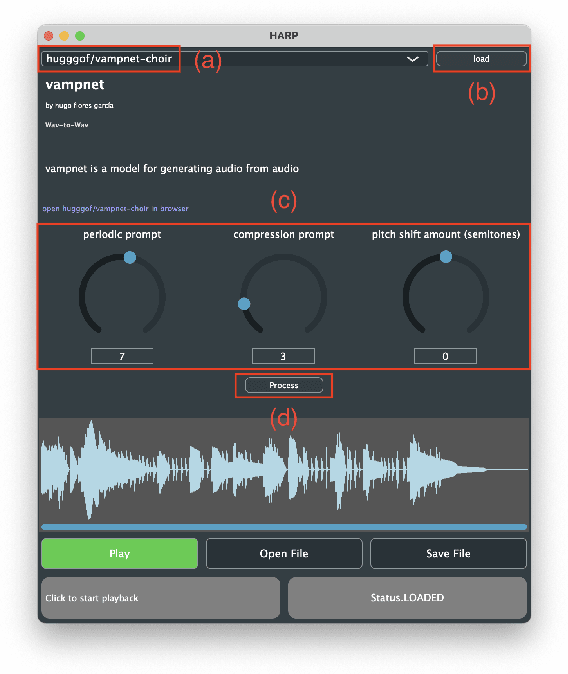
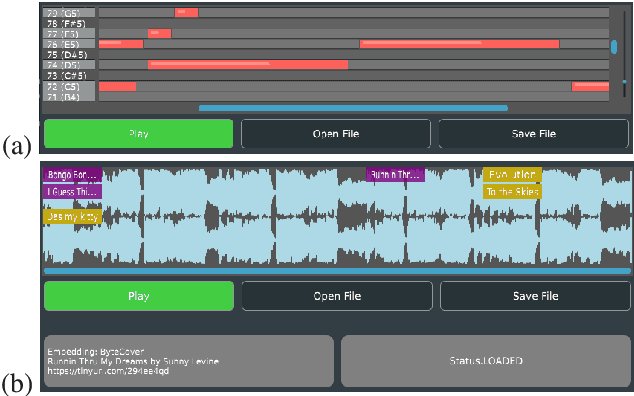
HARP 2.0 brings deep learning models to digital audio workstation (DAW) software through hosted, asynchronous, remote processing, allowing users to route audio from a plug-in interface through any compatible Gradio endpoint to perform arbitrary transformations. HARP renders endpoint-defined controls and processed audio in-plugin, meaning users can explore a variety of cutting-edge deep learning models without ever leaving the DAW. In the 2.0 release we introduce support for MIDI-based models and audio/MIDI labeling models, provide a streamlined pyharp Python API for model developers, and implement numerous interface and stability improvements. Through this work, we hope to bridge the gap between model developers and creatives, improving access to deep learning models by seamlessly integrating them into DAW workflows.
Fine-Grained and Interpretable Neural Speech Editing
Jul 07, 2024

Fine-grained editing of speech attributes$\unicode{x2014}$such as prosody (i.e., the pitch, loudness, and phoneme durations), pronunciation, speaker identity, and formants$\unicode{x2014}$is useful for fine-tuning and fixing imperfections in human and AI-generated speech recordings for creation of podcasts, film dialogue, and video game dialogue. Existing speech synthesis systems use representations that entangle two or more of these attributes, prohibiting their use in fine-grained, disentangled editing. In this paper, we demonstrate the first disentangled and interpretable representation of speech with comparable subjective and objective vocoding reconstruction accuracy to Mel spectrograms. Our interpretable representation, combined with our proposed data augmentation method, enables training an existing neural vocoder to perform fast, accurate, and high-quality editing of pitch, duration, volume, timbral correlates of volume, pronunciation, speaker identity, and spectral balance.
Crowdsourced and Automatic Speech Prominence Estimation
Oct 12, 2023



The prominence of a spoken word is the degree to which an average native listener perceives the word as salient or emphasized relative to its context. Speech prominence estimation is the process of assigning a numeric value to the prominence of each word in an utterance. These prominence labels are useful for linguistic analysis, as well as training automated systems to perform emphasis-controlled text-to-speech or emotion recognition. Manually annotating prominence is time-consuming and expensive, which motivates the development of automated methods for speech prominence estimation. However, developing such an automated system using machine-learning methods requires human-annotated training data. Using our system for acquiring such human annotations, we collect and open-source crowdsourced annotations of a portion of the LibriTTS dataset. We use these annotations as ground truth to train a neural speech prominence estimator that generalizes to unseen speakers, datasets, and speaking styles. We investigate design decisions for neural prominence estimation as well as how neural prominence estimation improves as a function of two key factors of annotation cost: dataset size and the number of annotations per utterance.
Cross-domain Neural Pitch and Periodicity Estimation
Jan 28, 2023



Pitch is a foundational aspect of our perception of audio signals. Pitch contours are commonly used to analyze speech and music signals and as input features for many audio tasks, including music transcription, singing voice synthesis, and prosody editing. In this paper, we describe a set of techniques for improving the accuracy of state-of-the-art neural pitch and periodicity estimators. We also introduce a novel entropy-based method for extracting periodicity and per-frame voiced-unvoiced classifications from statistical inference-based pitch estimators (e.g., neural networks), and show how to train a neural pitch estimator to simultaneously handle speech and music without performance degradation. While neural pitch trackers have historically been significantly slower than signal processing based pitch trackers, our estimator implementations approach the speed of state-of-the-art DSP-based pitch estimators on a standard CPU, but with significantly more accurate pitch and periodicity estimation. Our experiments show that an accurate, cross-domain pitch and periodicity estimator written in PyTorch with a hopsize of ten milliseconds can run 11.2x faster than real-time on a Intel i9-9820X 10-core 3.30 GHz CPU or 408x faster than real-time on a NVIDIA GeForce RTX 3090 GPU without hardware optimization. We release all of our code and models as Pitch-Estimating Neural Networks (penn), an open-source, pip-installable Python module for training, evaluating, and performing inference with pitch- and periodicity-estimating neural networks. The code for penn is available at https://github.com/interactiveaudiolab/penn.
3D Convolutional Neural Networks for Dendrite Segmentation Using Fine-Tuning and Hyperparameter Optimization
May 02, 2022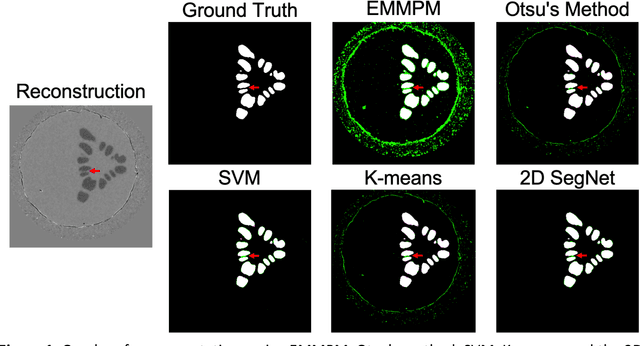
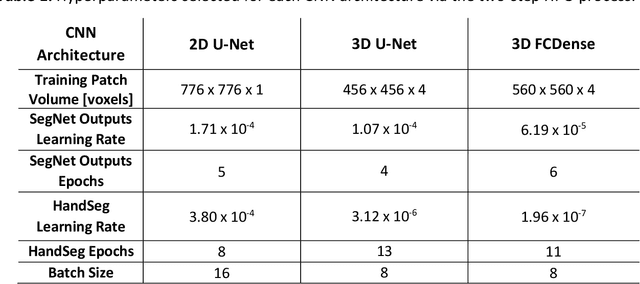

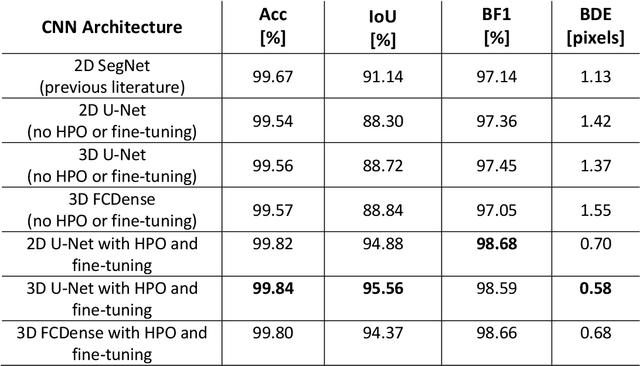
Dendritic microstructures are ubiquitous in nature and are the primary solidification morphologies in metallic materials. Techniques such as x-ray computed tomography (XCT) have provided new insights into dendritic phase transformation phenomena. However, manual identification of dendritic morphologies in microscopy data can be both labor intensive and potentially ambiguous. The analysis of 3D datasets is particularly challenging due to their large sizes (terabytes) and the presence of artifacts scattered within the imaged volumes. In this study, we trained 3D convolutional neural networks (CNNs) to segment 3D datasets. Three CNN architectures were investigated, including a new 3D version of FCDense. We show that using hyperparameter optimization (HPO) and fine-tuning techniques, both 2D and 3D CNN architectures can be trained to outperform the previous state of the art. The 3D U-Net architecture trained in this study produced the best segmentations according to quantitative metrics (pixel-wise accuracy of 99.84% and a boundary displacement error of 0.58 pixels), while 3D FCDense produced the smoothest boundaries and best segmentations according to visual inspection. The trained 3D CNNs are able to segment entire 852 x 852 x 250 voxel 3D volumes in only ~60 seconds, thus hastening the progress towards a deeper understanding of phase transformation phenomena such as dendritic solidification.