 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwenty-Five Years of MIR Research: Achievements, Practices, Evaluations, and Future Challenges
Nov 10, 2025In this paper, we trace the evolution of Music Information Retrieval (MIR) over the past 25 years. While MIR gathers all kinds of research related to music informatics, a large part of it focuses on signal processing techniques for music data, fostering a close relationship with the IEEE Audio and Acoustic Signal Processing Technical Commitee. In this paper, we reflect the main research achievements of MIR along the three EDICS related to music analysis, processing and generation. We then review a set of successful practices that fuel the rapid development of MIR research. One practice is the annual research benchmark, the Music Information Retrieval Evaluation eXchange, where participants compete on a set of research tasks. Another practice is the pursuit of reproducible and open research. The active engagement with industry research and products is another key factor for achieving large societal impacts and motivating younger generations of students to join the field. Last but not the least, the commitment to diversity, equity and inclusion ensures MIR to be a vibrant and open community where various ideas, methodologies, and career pathways collide. We finish by providing future challenges MIR will have to face.
Generating Novel and Realistic Speakers for Voice Conversion
Nov 10, 2025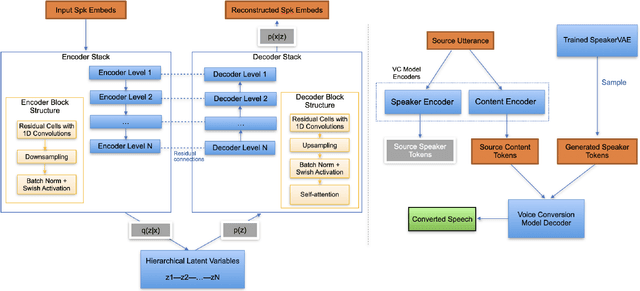



Voice conversion models modify timbre while preserving paralinguistic features, enabling applications like dubbing and identity protection. However, most VC systems require access to target utterances, limiting their use when target data is unavailable or when users desire conversion to entirely novel, unseen voices. To address this, we introduce a lightweight method SpeakerVAE to generate novel speakers for VC. Our approach uses a deep hierarchical variational autoencoder to model the speaker timbre space. By sampling from the trained model, we generate novel speaker representations for voice synthesis in a VC pipeline. The proposed method is a flexible plug-in module compatible with various VC models, without co-training or fine-tuning of the base VC system. We evaluated our approach with state-of-the-art VC models: FACodec and CosyVoice2. The results demonstrate that our method successfully generates novel, unseen speakers with quality comparable to that of the training speakers.
Towards Perception-Informed Latent HRTF Representations
Jul 03, 2025Personalized head-related transfer functions (HRTFs) are essential for ensuring a realistic auditory experience over headphones, because they take into account individual anatomical differences that affect listening. Most machine learning approaches to HRTF personalization rely on a learned low-dimensional latent space to generate or select custom HRTFs for a listener. However, these latent representations are typically learned in a manner that optimizes for spectral reconstruction but not for perceptual compatibility, meaning they may not necessarily align with perceptual distance. In this work, we first study whether traditionally learned HRTF representations are well correlated with perceptual relations using auditory-based objective perceptual metrics; we then propose a method for explicitly embedding HRTFs into a perception-informed latent space, leveraging a metric-based loss function and supervision via Metric Multidimensional Scaling (MMDS). Finally, we demonstrate the applicability of these learned representations to the task of HRTF personalization. We suggest that our method has the potential to render personalized spatial audio, leading to an improved listening experience.
A Review on Score-based Generative Models for Audio Applications
Jun 10, 2025Diffusion models have emerged as powerful deep generative techniques, producing high-quality and diverse samples in applications in various domains including audio. These models have many different design choices suitable for different applications, however, existing reviews lack in-depth discussions of these design choices. The audio diffusion model literature also lacks principled guidance for the implementation of these design choices and their comparisons for different applications. This survey provides a comprehensive review of diffusion model design with an emphasis on design principles for quality improvement and conditioning for audio applications. We adopt the score modeling perspective as a unifying framework that accommodates various interpretations, including recent approaches like flow matching. We systematically examine the training and sampling procedures of diffusion models, and audio applications through different conditioning mechanisms. To address the lack of audio diffusion model codebases and to promote reproducible research and rapid prototyping, we introduce an open-source codebase at https://github.com/gzhu06/AudioDiffuser that implements our reviewed framework for various audio applications. We demonstrate its capabilities through three case studies: audio generation, speech enhancement, and text-to-speech synthesis, with benchmark evaluations on standard datasets.
HARP 2.0: Expanding Hosted, Asynchronous, Remote Processing for Deep Learning in the DAW
Mar 04, 2025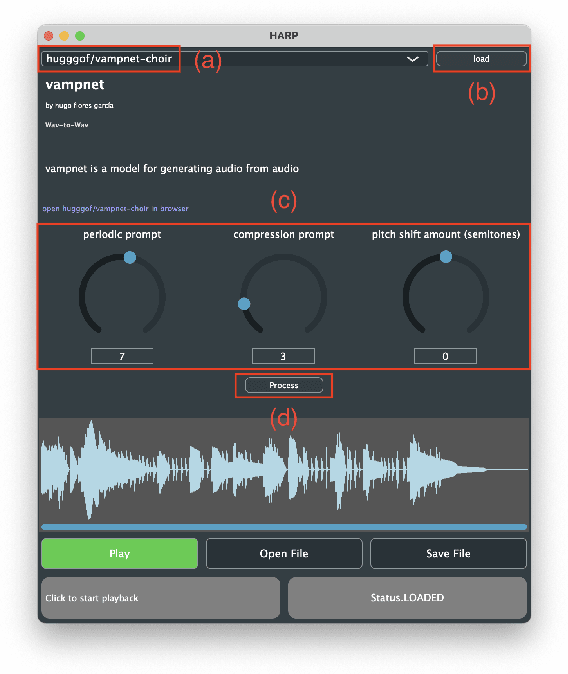
HARP 2.0 brings deep learning models to digital audio workstation (DAW) software through hosted, asynchronous, remote processing, allowing users to route audio from a plug-in interface through any compatible Gradio endpoint to perform arbitrary transformations. HARP renders endpoint-defined controls and processed audio in-plugin, meaning users can explore a variety of cutting-edge deep learning models without ever leaving the DAW. In the 2.0 release we introduce support for MIDI-based models and audio/MIDI labeling models, provide a streamlined pyharp Python API for model developers, and implement numerous interface and stability improvements. Through this work, we hope to bridge the gap between model developers and creatives, improving access to deep learning models by seamlessly integrating them into DAW workflows.
Audio Visual Segmentation Through Text Embeddings
Feb 22, 2025The goal of Audio-Visual Segmentation (AVS) is to localize and segment the sounding source objects from the video frames. Researchers working on AVS suffer from limited datasets because hand-crafted annotation is expensive. Recent works attempt to overcome the challenge of limited data by leveraging the segmentation foundation model, SAM, prompting it with audio to enhance its ability to segment sounding source objects. While this approach alleviates the model's burden on understanding visual modality by utilizing pre-trained knowledge of SAM, it does not address the fundamental challenge of the limited dataset for learning audio-visual relationships. To address these limitations, we propose \textbf{AV2T-SAM}, a novel framework that bridges audio features with the text embedding space of pre-trained text-prompted SAM. Our method leverages multimodal correspondence learned from rich text-image paired datasets to enhance audio-visual alignment. Furthermore, we introduce a novel feature, $\mathbf{\textit{\textbf{f}}_{CLIP} \odot \textit{\textbf{f}}_{CLAP}}$, which emphasizes shared semantics of audio and visual modalities while filtering irrelevant noise. Experiments on the AVSBench dataset demonstrate state-of-the-art performance on both datasets of AVSBench. Our approach outperforms existing methods by effectively utilizing pretrained segmentation models and cross-modal semantic alignment.
SVDD 2024: The Inaugural Singing Voice Deepfake Detection Challenge
Aug 28, 2024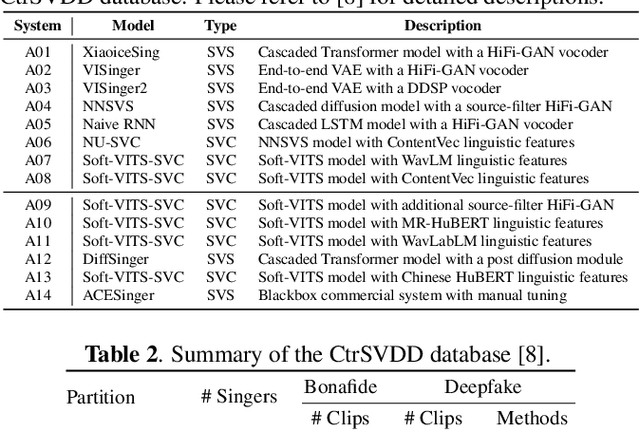
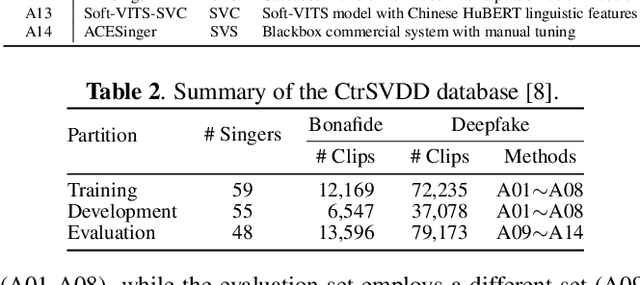
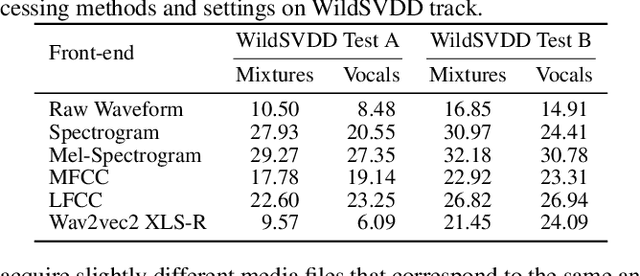
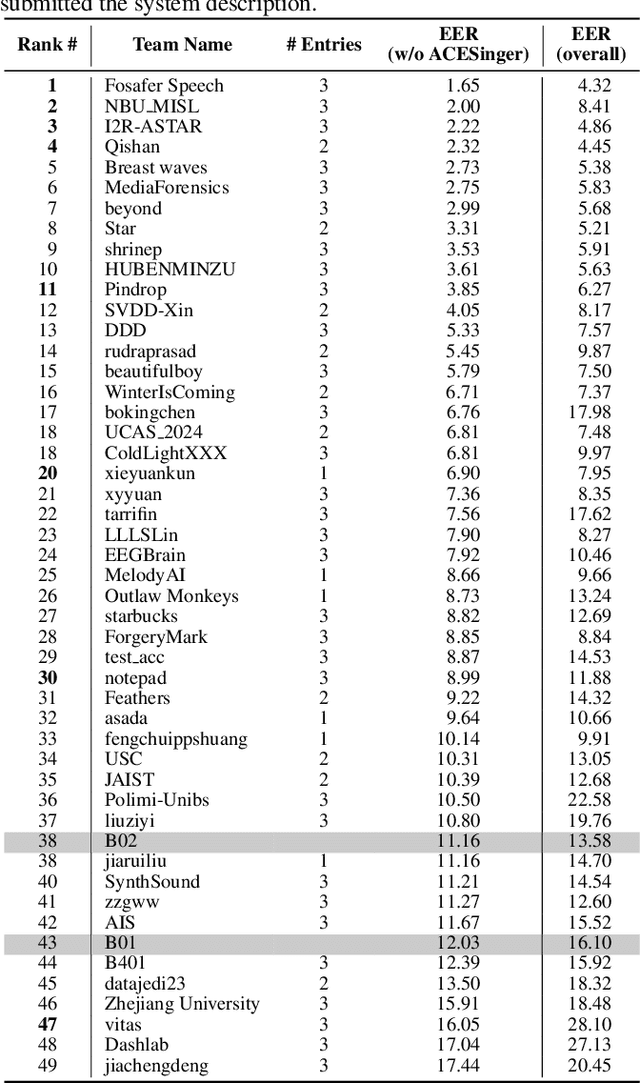
With the advancements in singing voice generation and the growing presence of AI singers on media platforms, the inaugural Singing Voice Deepfake Detection (SVDD) Challenge aims to advance research in identifying AI-generated singing voices from authentic singers. This challenge features two tracks: a controlled setting track (CtrSVDD) and an in-the-wild scenario track (WildSVDD). The CtrSVDD track utilizes publicly available singing vocal data to generate deepfakes using state-of-the-art singing voice synthesis and conversion systems. Meanwhile, the WildSVDD track expands upon the existing SingFake dataset, which includes data sourced from popular user-generated content websites. For the CtrSVDD track, we received submissions from 47 teams, with 37 surpassing our baselines and the top team achieving a 1.65% equal error rate. For the WildSVDD track, we benchmarked the baselines. This paper reviews these results, discusses key findings, and outlines future directions for SVDD research.
Generating Data with Text-to-Speech and Large-Language Models for Conversational Speech Recognition
Aug 17, 2024


Currently, a common approach in many speech processing tasks is to leverage large scale pre-trained models by fine-tuning them on in-domain data for a particular application. Yet obtaining even a small amount of such data can be problematic, especially for sensitive domains and conversational speech scenarios, due to both privacy issues and annotation costs. To address this, synthetic data generation using single speaker datasets has been employed. Yet, for multi-speaker cases, such an approach often requires extensive manual effort and is prone to domain mismatches. In this work, we propose a synthetic data generation pipeline for multi-speaker conversational ASR, leveraging a large language model (LLM) for content creation and a conversational multi-speaker text-to-speech (TTS) model for speech synthesis. We conduct evaluation by fine-tuning the Whisper ASR model for telephone and distant conversational speech settings, using both in-domain data and generated synthetic data. Our results show that the proposed method is able to significantly outperform classical multi-speaker generation approaches that use external, non-conversational speech datasets.
A Multi-Stream Fusion Approach with One-Class Learning for Audio-Visual Deepfake Detection
Jun 20, 2024



This paper addresses the challenge of developing a robust audio-visual deepfake detection model. In practical use cases, new generation algorithms are continually emerging, and these algorithms are not encountered during the development of detection methods. This calls for the generalization ability of the method. Additionally, to ensure the credibility of detection methods, it is beneficial for the model to interpret which cues from the video indicate it is fake. Motivated by these considerations, we then propose a multi-stream fusion approach with one-class learning as a representation-level regularization technique. We study the generalization problem of audio-visual deepfake detection by creating a new benchmark by extending and re-splitting the existing FakeAVCeleb dataset. The benchmark contains four categories of fake video(Real Audio-Fake Visual, Fake Audio-Fake Visual, Fake Audio-Real Visual, and unsynchronized video). The experimental results show that our approach improves the model's detection of unseen attacks by an average of 7.31% across four test sets, compared to the baseline model. Additionally, our proposed framework offers interpretability, indicating which modality the model identifies as fake.
Articulatory Phonetics Informed Controllable Expressive Speech Synthesis
Jun 15, 2024

Expressive speech synthesis aims to generate speech that captures a wide range of para-linguistic features, including emotion and articulation, though current research primarily emphasizes emotional aspects over the nuanced articulatory features mastered by professional voice actors. Inspired by this, we explore expressive speech synthesis through the lens of articulatory phonetics. Specifically, we define a framework with three dimensions: Glottalization, Tenseness, and Resonance (GTR), to guide the synthesis at the voice production level. With this framework, we record a high-quality speech dataset named GTR-Voice, featuring 20 Chinese sentences articulated by a professional voice actor across 125 distinct GTR combinations. We verify the framework and GTR annotations through automatic classification and listening tests, and demonstrate precise controllability along the GTR dimensions on two fine-tuned expressive TTS models. We open-source the dataset and TTS models.