 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Singing Voice Conversion Challenge 2025: From Singer Identity Conversion To Singing Style Conversion
Sep 19, 2025We present the findings of the latest iteration of the Singing Voice Conversion Challenge, a scientific event aiming to compare and understand different voice conversion systems in a controlled environment. Compared to previous iterations which solely focused on converting the singer identity, this year we also focused on converting the singing style of the singer. To create a controlled environment and thorough evaluations, we developed a new challenge database, introduced two tasks, open-sourced baselines, and conducted large-scale crowd-sourced listening tests and objective evaluations. The challenge was ran for two months and in total we evaluated 26 different systems. The results of the large-scale crowd-sourced listening test showed that top systems had comparable singer identity scores to ground truth samples. However, modeling the singing style and consequently achieving high naturalness still remains a challenge in this task, primarily due to the difficulty in modeling dynamic information in breathy, glissando, and vibrato singing styles.
Layer-wise Analysis for Quality of Multilingual Synthesized Speech
Sep 05, 2025While supervised quality predictors for synthesized speech have demonstrated strong correlations with human ratings, their requirement for in-domain labeled training data hinders their generalization ability to new domains. Unsupervised approaches based on pretrained self-supervised learning (SSL) based models and automatic speech recognition (ASR) models are a promising alternative; however, little is known about how these models encode information about speech quality. Towards the goal of better understanding how different aspects of speech quality are encoded in a multilingual setting, we present a layer-wise analysis of multilingual pretrained speech models based on reference modeling. We find that features extracted from early SSL layers show correlations with human ratings of synthesized speech, and later layers of ASR models can predict quality of non-neural systems as well as intelligibility. We also demonstrate the importance of using well-matched reference data.
PARCO: Phoneme-Augmented Robust Contextual ASR via Contrastive Entity Disambiguation
Sep 04, 2025Automatic speech recognition (ASR) systems struggle with domain-specific named entities, especially homophones. Contextual ASR improves recognition but often fails to capture fine-grained phoneme variations due to limited entity diversity. Moreover, prior methods treat entities as independent tokens, leading to incomplete multi-token biasing. To address these issues, we propose Phoneme-Augmented Robust Contextual ASR via COntrastive entity disambiguation (PARCO), which integrates phoneme-aware encoding, contrastive entity disambiguation, entity-level supervision, and hierarchical entity filtering. These components enhance phonetic discrimination, ensure complete entity retrieval, and reduce false positives under uncertainty. Experiments show that PARCO achieves CER of 4.22% on Chinese AISHELL-1 and WER of 11.14% on English DATA2 under 1,000 distractors, significantly outperforming baselines. PARCO also demonstrates robust gains on out-of-domain datasets like THCHS-30 and LibriSpeech.
QHARMA-GAN: Quasi-Harmonic Neural Vocoder based on Autoregressive Moving Average Model
Jul 02, 2025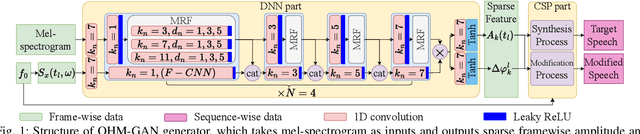
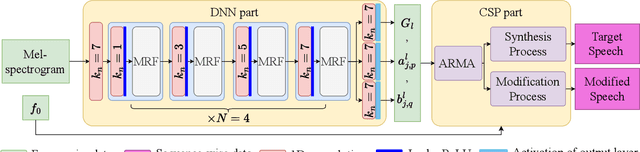
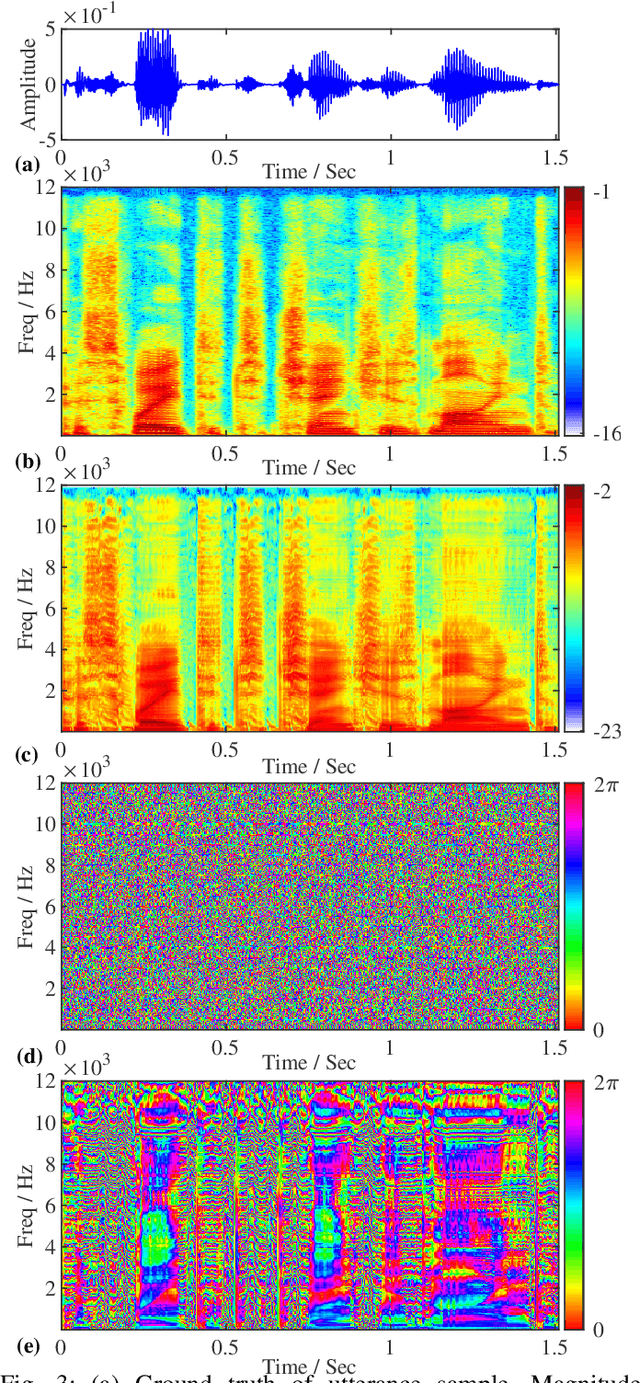
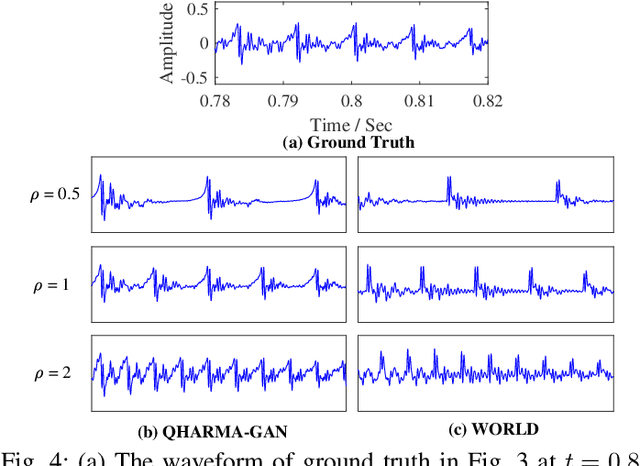
Vocoders, encoding speech signals into acoustic features and allowing for speech signal reconstruction from them, have been studied for decades. Recently, the rise of deep learning has particularly driven the development of neural vocoders to generate high-quality speech signals. On the other hand, the existing end-to-end neural vocoders suffer from a black-box nature that blinds the speech production mechanism and the intrinsic structure of speech, resulting in the ambiguity of separately modeling source excitation and resonance characteristics and the loss of flexibly synthesizing or modifying speech with high quality. Moreover, their sequence-wise waveform generation usually requires complicated networks, leading to substantial time consumption. In this work, inspired by the quasi-harmonic model (QHM) that represents speech as sparse components, we combine the neural network and QHM synthesis process to propose a novel framework for the neural vocoder. Accordingly, speech signals can be encoded into autoregressive moving average (ARMA) functions to model the resonance characteristics, yielding accurate estimates of the amplitudes and phases of quasi-harmonics at any frequency. Subsequently, the speech can be resynthesized and arbitrarily modified in terms of pitch shifting and time stretching with high quality, whereas the time consumption and network size decrease. The experiments indicate that the proposed method leverages the strengths of QHM, the ARMA model, and neural networks, leading to the outperformance of our methods over other methods in terms of generation speed, synthesis quality, and modification flexibility.
Improving Anomalous Sound Detection through Pseudo-anomalous Set Selection and Pseudo-label Utilization under Unlabeled Conditions
May 25, 2025This paper addresses performance degradation in anomalous sound detection (ASD) when neither sufficiently similar machine data nor operational state labels are available. We present an integrated pipeline that combines three complementary components derived from prior work and extends them to the unlabeled ASD setting. First, we adapt an anomaly score based selector to curate external audio data resembling the normal sounds of the target machine. Second, we utilize triplet learning to assign pseudo-labels to unlabeled data, enabling finer classification of operational sounds and detection of subtle anomalies. Third, we employ iterative training to refine both the pseudo-anomalous set selection and pseudo-label assignment, progressively improving detection accuracy. Experiments on the DCASE2022-2024 Task 2 datasets demonstrate that, in unlabeled settings, our approach achieves an average AUC increase of over 6.6 points compared to conventional methods. In labeled settings, incorporating external data from the pseudo-anomalous set further boosts performance. These results highlight the practicality and robustness of our methods in scenarios with scarce machine data and labels, facilitating ASD deployment across diverse industrial settings with minimal annotation effort.
Serial-OE: Anomalous sound detection based on serial method with outlier exposure capable of using small amounts of anomalous data for training
May 25, 2025We introduce Serial-OE, a new approach to anomalous sound detection (ASD) that leverages small amounts of anomalous data to improve the performance. Conventional ASD methods rely primarily on the modeling of normal data, due to the cost of collecting anomalous data from various possible types of equipment breakdowns. Our method improves upon existing ASD systems by implementing an outlier exposure framework that utilizes normal and pseudo-anomalous data for training, with the capability to also use small amounts of real anomalous data. A comprehensive evaluation using the DCASE2020 Task2 dataset shows that our method outperforms state-of-the-art ASD models. We also investigate the impact on performance of using a small amount of anomalous data during training, of using data without machine ID information, and of using contaminated training data. Our experimental results reveal the potential of using a very limited amount of anomalous data during training to address the limitations of existing methods using only normal data for training due to the scarcity of anomalous data. This study contributes to the field by presenting a method that can be dynamically adapted to include anomalous data during the operational phase of an ASD system, paving the way for more accurate ASD.
SHEET: A Multi-purpose Open-source Speech Human Evaluation Estimation Toolkit
May 21, 2025We introduce SHEET, a multi-purpose open-source toolkit designed to accelerate subjective speech quality assessment (SSQA) research. SHEET stands for the Speech Human Evaluation Estimation Toolkit, which focuses on data-driven deep neural network-based models trained to predict human-labeled quality scores of speech samples. SHEET provides comprehensive training and evaluation scripts, multi-dataset and multi-model support, as well as pre-trained models accessible via Torch Hub and HuggingFace Spaces. To demonstrate its capabilities, we re-evaluated SSL-MOS, a speech self-supervised learning (SSL)-based SSQA model widely used in recent scientific papers, on an extensive list of speech SSL models. Experiments were conducted on two representative SSQA datasets named BVCC and NISQA, and we identified the optimal speech SSL model, whose performance surpassed the original SSL-MOS implementation and was comparable to state-of-the-art methods.
Analysis and Extension of Noisy-target Training for Unsupervised Target Signal Enhancement
Mar 19, 2025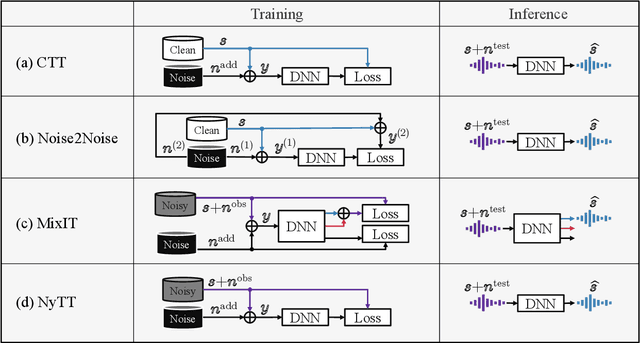
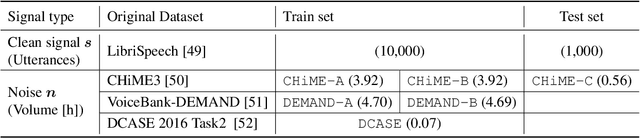

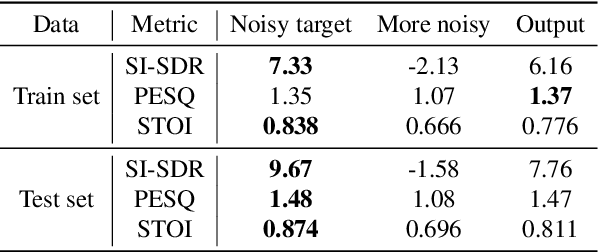
Deep neural network-based target signal enhancement (TSE) is usually trained in a supervised manner using clean target signals. However, collecting clean target signals is costly and such signals are not always available. Thus, it is desirable to develop an unsupervised method that does not rely on clean target signals. Among various studies on unsupervised TSE methods, Noisy-target Training (NyTT) has been established as a fundamental method. NyTT simply replaces clean target signals with noisy ones in the typical supervised training, and it has been experimentally shown to achieve TSE. Despite its effectiveness and simplicity, its mechanism and detailed behavior are still unclear. In this paper, to advance NyTT and, thus, unsupervised methods as a whole, we analyze NyTT from various perspectives. We experimentally demonstrate the mechanism of NyTT, the desirable conditions, and the effectiveness of utilizing noisy signals in situations where a small number of clean target signals are available. Furthermore, we propose an improved version of NyTT based on its properties and explore its capabilities in the dereverberation and declipping tasks, beyond the denoising task.
Serenade: A Singing Style Conversion Framework Based On Audio Infilling
Mar 16, 2025We propose Serenade, a novel framework for the singing style conversion (SSC) task. Although singer identity conversion has made great strides in the previous years, converting the singing style of a singer has been an unexplored research area. We find three main challenges in SSC: modeling the target style, disentangling source style, and retaining the source melody. To model the target singing style, we use an audio infilling task by predicting a masked segment of the target mel-spectrogram with a flow-matching model using the complement of the masked target mel-spectrogram along with disentangled acoustic features. On the other hand, to disentangle the source singing style, we use a cyclic training approach, where we use synthetic converted samples as source inputs and reconstruct the original source mel-spectrogram as a target. Finally, to retain the source melody better, we investigate a post-processing module using a source-filter-based vocoder and resynthesize the converted waveforms using the original F0 patterns. Our results showed that the Serenade framework can handle generalized SSC tasks with the best overall similarity score, especially in modeling breathy and mixed singing styles. Moreover, although resynthesizing with the original F0 patterns alleviated out-of-tune singing and improved naturalness, we found a slight tradeoff in similarity due to not changing the F0 patterns into the target style.
Handling Domain Shifts for Anomalous Sound Detection: A Review of DCASE-Related Work
Mar 13, 2025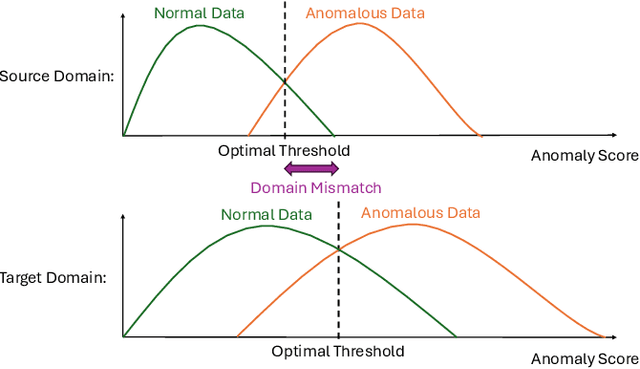
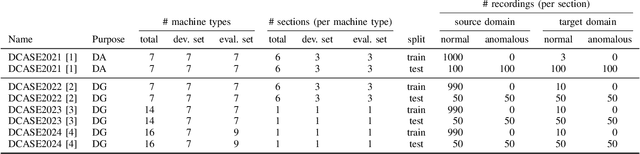
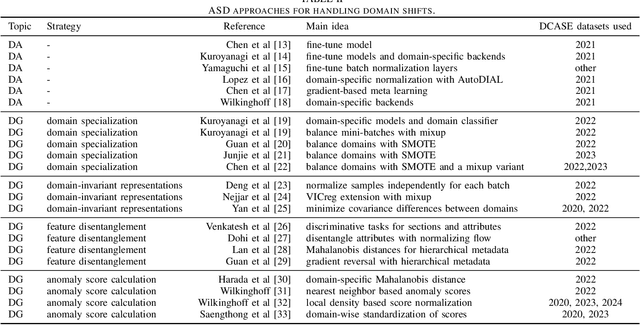
When detecting anomalous sounds in complex environments, one of the main difficulties is that trained models must be sensitive to subtle differences in monitored target signals, while many practical applications also require them to be insensitive to changes in acoustic domains. Examples of such domain shifts include changing the type of microphone or the location of acoustic sensors, which can have a much stronger impact on the acoustic signal than subtle anomalies themselves. Moreover, users typically aim to train a model only on source domain data, which they may have a relatively large collection of, and they hope that such a trained model will be able to generalize well to an unseen target domain by providing only a minimal number of samples to characterize the acoustic signals in that domain. In this work, we review and discuss recent publications focusing on this domain generalization problem for anomalous sound detection in the context of the DCASE challenges on acoustic machine condition monitoring.