 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSerial-OE: Anomalous sound detection based on serial method with outlier exposure capable of using small amounts of anomalous data for training
May 25, 2025We introduce Serial-OE, a new approach to anomalous sound detection (ASD) that leverages small amounts of anomalous data to improve the performance. Conventional ASD methods rely primarily on the modeling of normal data, due to the cost of collecting anomalous data from various possible types of equipment breakdowns. Our method improves upon existing ASD systems by implementing an outlier exposure framework that utilizes normal and pseudo-anomalous data for training, with the capability to also use small amounts of real anomalous data. A comprehensive evaluation using the DCASE2020 Task2 dataset shows that our method outperforms state-of-the-art ASD models. We also investigate the impact on performance of using a small amount of anomalous data during training, of using data without machine ID information, and of using contaminated training data. Our experimental results reveal the potential of using a very limited amount of anomalous data during training to address the limitations of existing methods using only normal data for training due to the scarcity of anomalous data. This study contributes to the field by presenting a method that can be dynamically adapted to include anomalous data during the operational phase of an ASD system, paving the way for more accurate ASD.
ESPnet-ST-v2: Multipurpose Spoken Language Translation Toolkit
Apr 11, 2023

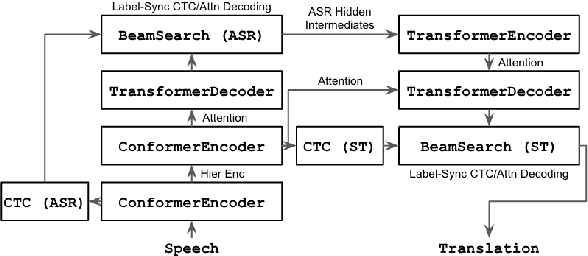
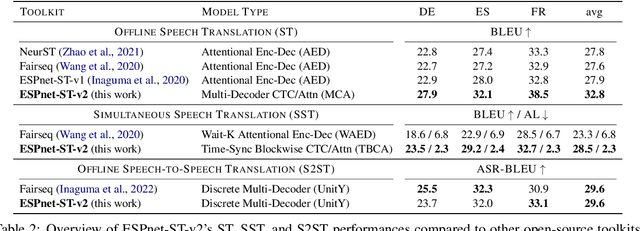
ESPnet-ST-v2 is a revamp of the open-source ESPnet-ST toolkit necessitated by the broadening interests of the spoken language translation community. ESPnet-ST-v2 supports 1) offline speech-to-text translation (ST), 2) simultaneous speech-to-text translation (SST), and 3) offline speech-to-speech translation (S2ST) -- each task is supported with a wide variety of approaches, differentiating ESPnet-ST-v2 from other open source spoken language translation toolkits. This toolkit offers state-of-the-art architectures such as transducers, hybrid CTC/attention, multi-decoders with searchable intermediates, time-synchronous blockwise CTC/attention, Translatotron models, and direct discrete unit models. In this paper, we describe the overall design, example models for each task, and performance benchmarking behind ESPnet-ST-v2, which is publicly available at https://github.com/espnet/espnet.
Unsupervised Data Selection for TTS: Using Arabic Broadcast News as a Case Study
Jan 26, 2023



Several high-resource Text to Speech (TTS) systems currently produce natural, well-established human-like speech. In contrast, low-resource languages, including Arabic, have very limited TTS systems due to the lack of resources. We propose a fully unsupervised method for building TTS, including automatic data selection and pre-training/fine-tuning strategies for TTS training, using broadcast news as a case study. We show how careful selection of data, yet smaller amounts, can improve the efficiency of TTS system in generating more natural speech than a system trained on a bigger dataset. We adopt to propose different approaches for the: 1) data: we applied automatic annotations using DNSMOS, automatic vowelization, and automatic speech recognition (ASR) for fixing transcriptions' errors; 2) model: we used transfer learning from high-resource language in TTS model and fine-tuned it with one hour broadcast recording then we used this model to guide a FastSpeech2-based Conformer model for duration. Our objective evaluation shows 3.9% character error rate (CER), while the groundtruth has 1.3% CER. As for the subjective evaluation, where 1 is bad and 5 is excellent, our FastSpeech2-based Conformer model achieved a mean opinion score (MOS) of 4.4 for intelligibility and 4.2 for naturalness, where many annotators recognized the voice of the broadcaster, which proves the effectiveness of our proposed unsupervised method.
ESPnet-ONNX: Bridging a Gap Between Research and Production
Sep 20, 2022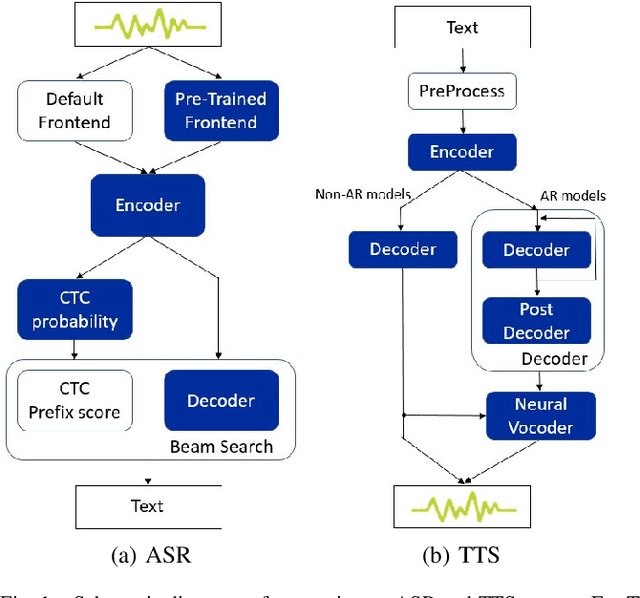
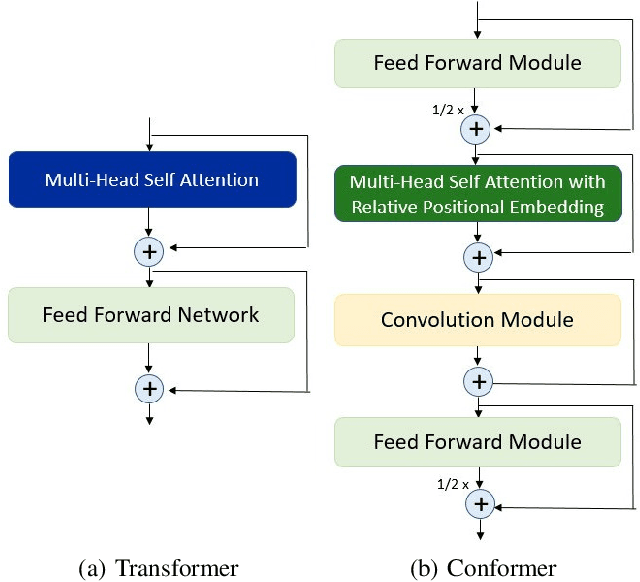
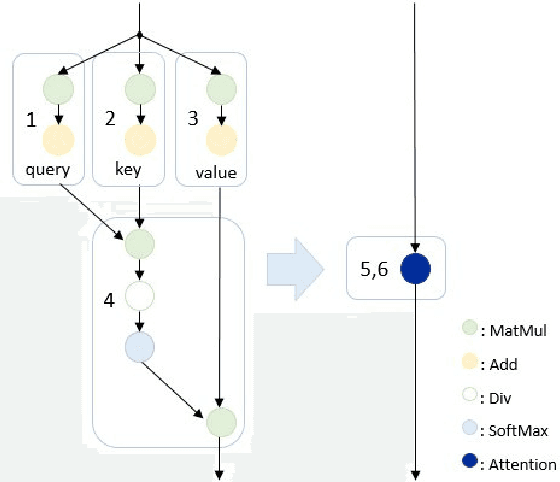

In the field of deep learning, researchers often focus on inventing novel neural network models and improving benchmarks. In contrast, application developers are interested in making models suitable for actual products, which involves optimizing a model for faster inference and adapting a model to various platforms (e.g., C++ and Python). In this work, to fill the gap between the two, we establish an effective procedure for optimizing a PyTorch-based research-oriented model for deployment, taking ESPnet, a widely used toolkit for speech processing, as an instance. We introduce different techniques to ESPnet, including converting a model into an ONNX format, fusing nodes in a graph, and quantizing parameters, which lead to approximately 1.3-2$\times$ speedup in various tasks (i.e., ASR, TTS, speech translation, and spoken language understanding) while keeping its performance without any additional training. Our ESPnet-ONNX will be publicly available at https://github.com/espnet/espnet_onnx
A Comparative Study of Self-supervised Speech Representation Based Voice Conversion
Jul 10, 2022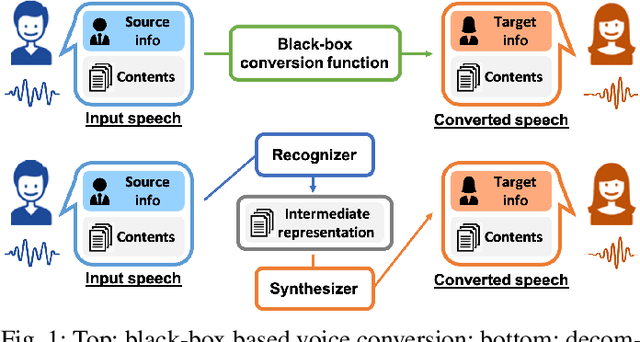
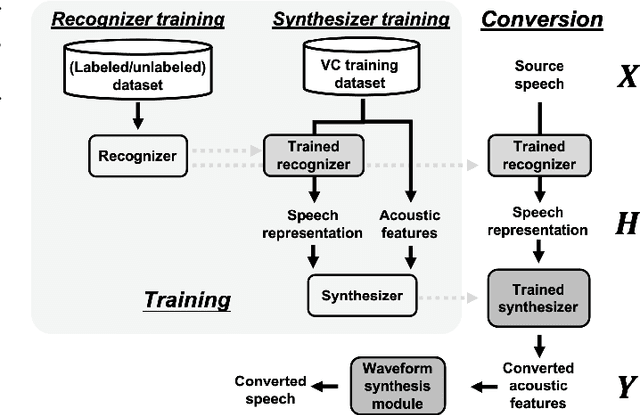
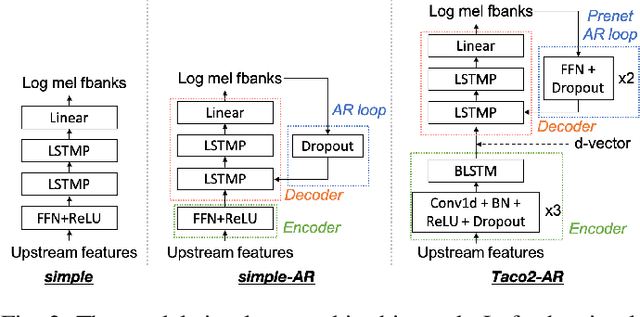
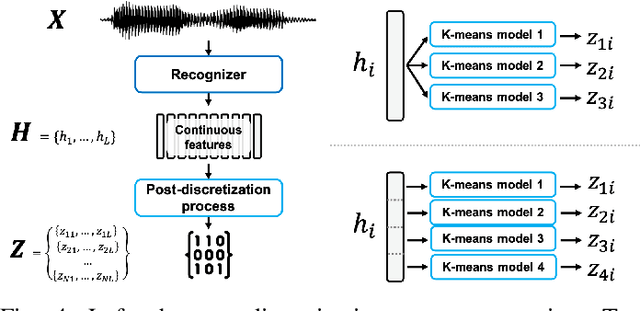
We present a large-scale comparative study of self-supervised speech representation (S3R)-based voice conversion (VC). In the context of recognition-synthesis VC, S3Rs are attractive owing to their potential to replace expensive supervised representations such as phonetic posteriorgrams (PPGs), which are commonly adopted by state-of-the-art VC systems. Using S3PRL-VC, an open-source VC software we previously developed, we provide a series of in-depth objective and subjective analyses under three VC settings: intra-/cross-lingual any-to-one (A2O) and any-to-any (A2A) VC, using the voice conversion challenge 2020 (VCC2020) dataset. We investigated S3R-based VC in various aspects, including model type, multilinguality, and supervision. We also studied the effect of a post-discretization process with k-means clustering and showed how it improves in the A2A setting. Finally, the comparison with state-of-the-art VC systems demonstrates the competitiveness of S3R-based VC and also sheds light on the possible improving directions.
Improvement of Serial Approach to Anomalous Sound Detection by Incorporating Two Binary Cross-Entropies for Outlier Exposure
Jun 13, 2022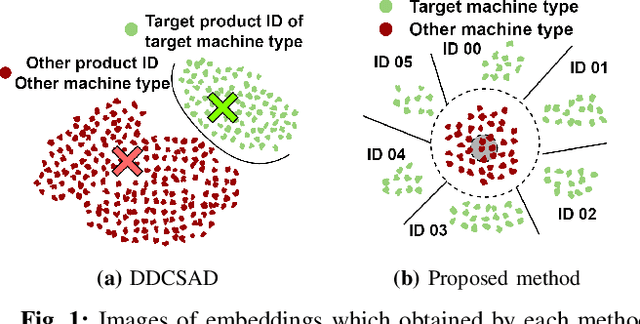
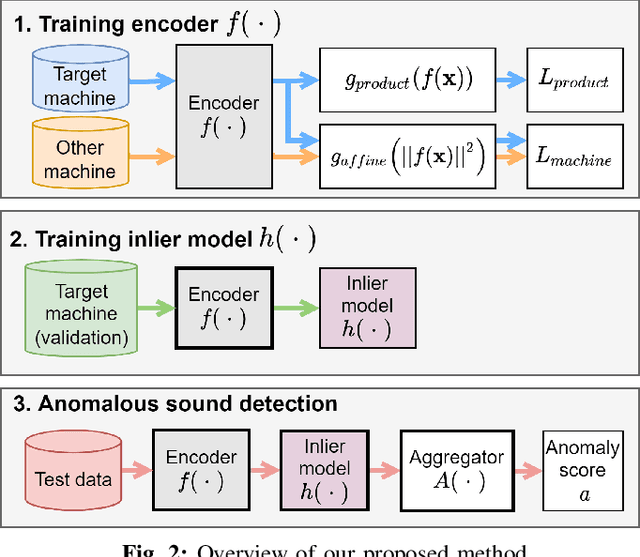
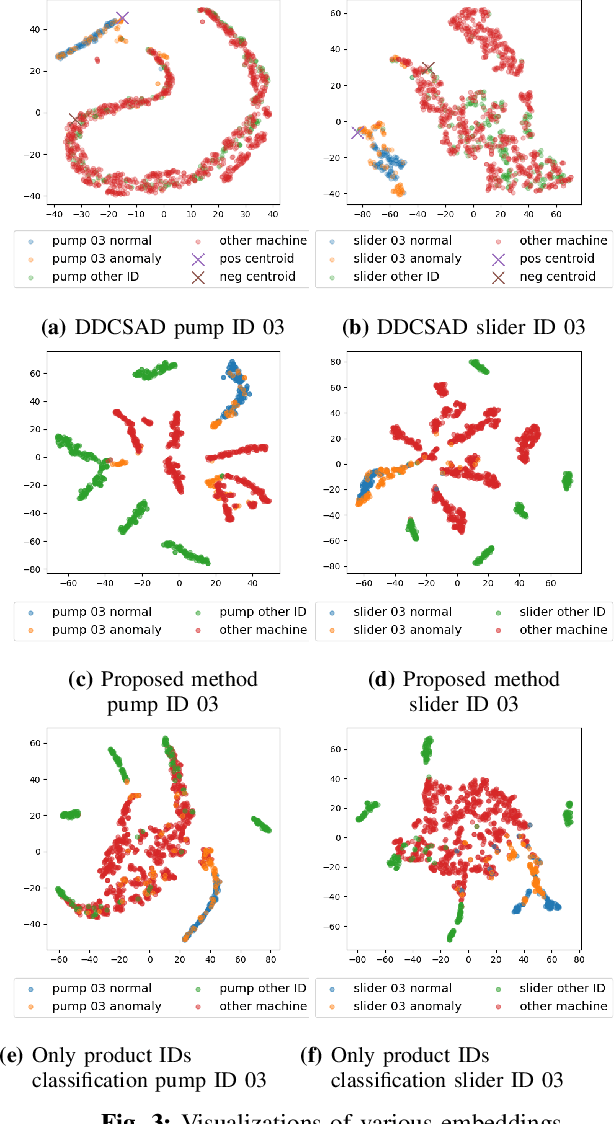
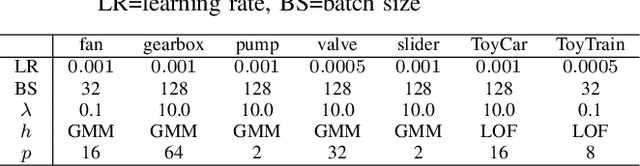
Anomalous sound detection systems must detect unknown, atypical sounds using only normal audio data. Conventional methods use the serial method, a combination of outlier exposure (OE), which classifies normal and pseudo-anomalous data and obtains embedding, and inlier modeling (IM), which models the probability distribution of the embedding. Although the serial method shows high performance due to the powerful feature extraction of OE and the robustness of IM, OE still has a problem that doesn't work well when the normal and pseudo-anomalous data are too similar or too different. To explicitly distinguish these data, the proposed method uses multi-task learning of two binary cross-entropies when training OE. The first is a loss that classifies the sound of the target machine to which product it is emitted from, which deals with the case where the normal data and the pseudo-anomalous data are too similar. The second is a loss that identifies whether the sound is emitted from the target machine or not, which deals with the case where the normal data and the pseudo-anomalous data are too different. We perform our experiments with DCASE 2021 Task~2 dataset. Our proposed single-model method outperforms the top-ranked method, which combines multiple models, by 2.1% in AUC.
Muskits: an End-to-End Music Processing Toolkit for Singing Voice Synthesis
May 09, 2022



This paper introduces a new open-source platform named Muskits for end-to-end music processing, which mainly focuses on end-to-end singing voice synthesis (E2E-SVS). Muskits supports state-of-the-art SVS models, including RNN SVS, transformer SVS, and XiaoiceSing. The design of Muskits follows the style of widely-used speech processing toolkits, ESPnet and Kaldi, for data prepossessing, training, and recipe pipelines. To the best of our knowledge, this toolkit is the first platform that allows a fair and highly-reproducible comparison between several published works in SVS. In addition, we also demonstrate several advanced usages based on the toolkit functionalities, including multilingual training and transfer learning. This paper describes the major framework of Muskits, its functionalities, and experimental results in single-singer, multi-singer, multilingual, and transfer learning scenarios. The toolkit is publicly available at https://github.com/SJTMusicTeam/Muskits.
Acoustic Event Detection with Classifier Chains
Feb 17, 2022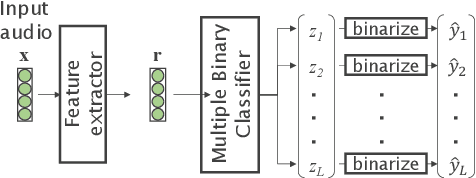

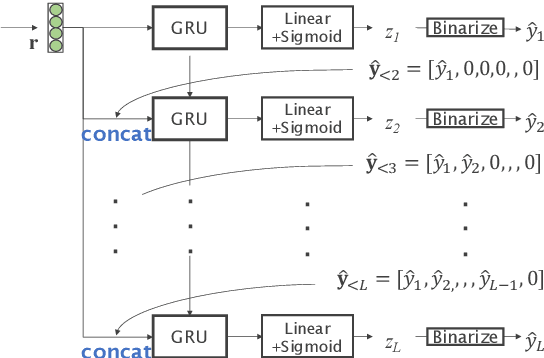
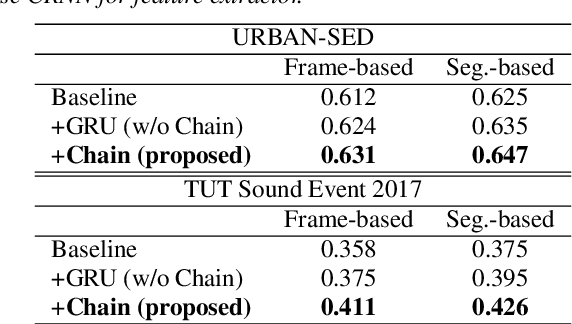
This paper proposes acoustic event detection (AED) with classifier chains, a new classifier based on the probabilistic chain rule. The proposed AED with classifier chains consists of a gated recurrent unit and performs iterative binary detection of each event one by one. In each iteration, the event's activity is estimated and used to condition the next output based on the probabilistic chain rule to form classifier chains. Therefore, the proposed method can handle the interdependence among events upon classification, while the conventional AED methods with multiple binary classifiers with a linear layer and sigmoid function have placed an assumption of conditional independence. In the experiments with a real-recording dataset, the proposed method demonstrates its superior AED performance to a relative 14.80% improvement compared to a convolutional recurrent neural network baseline system with the multiple binary classifiers.
Discretization and Re-synthesis: an alternative method to solve the Cocktail Party Problem
Jan 09, 2022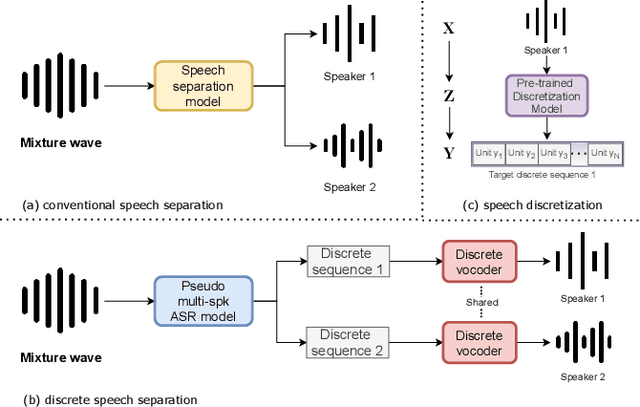

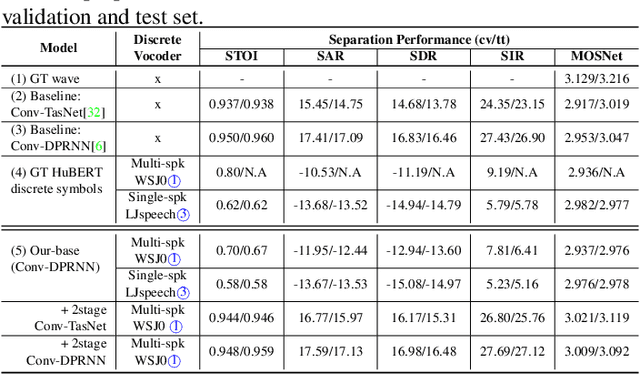
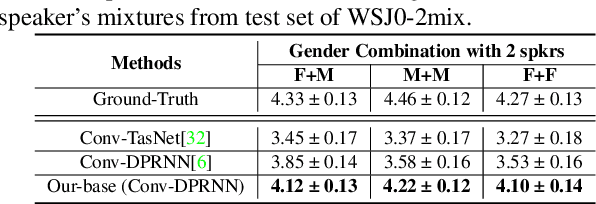
Deep learning based models have significantly improved the performance of speech separation with input mixtures like the cocktail party. Prominent methods (e.g., frequency-domain and time-domain speech separation) usually build regression models to predict the ground-truth speech from the mixture, using the masking-based design and the signal-level loss criterion (e.g., MSE or SI-SNR). This study demonstrates, for the first time, that the synthesis-based approach can also perform well on this problem, with great flexibility and strong potential. Specifically, we propose a novel speech separation/enhancement model based on the recognition of discrete symbols, and convert the paradigm of the speech separation/enhancement related tasks from regression to classification. By utilizing the synthesis model with the input of discrete symbols, after the prediction of discrete symbol sequence, each target speech could be re-synthesized. Evaluation results based on the WSJ0-2mix and VCTK-noisy corpora in various settings show that our proposed method can steadily synthesize the separated speech with high speech quality and without any interference, which is difficult to avoid in regression-based methods. In addition, with negligible loss of listening quality, the speaker conversion of enhanced/separated speech could be easily realized through our method.
ViCE: Self-Supervised Visual Concept Embeddings as Contextual and Pixel Appearance Invariant Semantic Representations
Nov 24, 2021

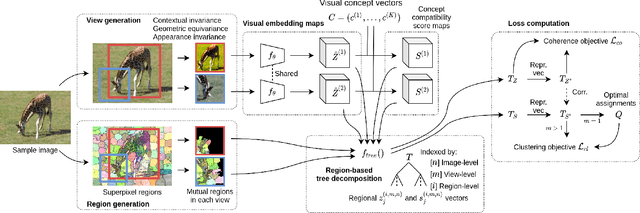

This work presents a self-supervised method to learn dense semantically rich visual concept embeddings for images inspired by methods for learning word embeddings in NLP. Our method improves on prior work by generating more expressive embeddings and by being applicable for high-resolution images. Viewing the generation of natural images as a stochastic process where a set of latent visual concepts give rise to observable pixel appearances, our method is formulated to learn the inverse mapping from pixels to concepts. Our method greatly improves the effectiveness of self-supervised learning for dense embedding maps by introducing superpixelization as a natural hierarchical step up from pixels to a small set of visually coherent regions. Additional contributions are regional contextual masking with nonuniform shapes matching visually coherent patches and complexity-based view sampling inspired by masked language models. The enhanced expressiveness of our dense embeddings is demonstrated by significantly improving the state-of-the-art representation quality benchmarks on COCO (+12.94 mIoU, +87.6\%) and Cityscapes (+16.52 mIoU, +134.2\%). Results show favorable scaling and domain generalization properties not demonstrated by prior work.