 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBFMD: A Full-Match Badminton Dense Dataset for Dense Shot Captioning
Mar 26, 2026Understanding tactical dynamics in badminton requires analyzing entire matches rather than isolated clips. However, existing badminton datasets mainly focus on short clips or task-specific annotations and rarely provide full-match data with dense multimodal annotations. This limitation makes it difficult to generate accurate shot captions and perform match-level analysis. To address this limitation, we introduce the first Badminton Full Match Dense (BFMD) dataset, with 19 broadcast matches (including both singles and doubles) covering over 20 hours of play, comprising 1,687 rallies and 16,751 hit events, each annotated with a shot caption. The dataset provides hierarchical annotations including match segments, rally events, and dense rally-level multimodal annotations such as shot types, shuttle trajectories, player pose keypoints, and shot captions. We develop a VideoMAE-based multimodal captioning framework with a Semantic Feedback mechanism that leverages shot semantics to guide caption generation and improve semantic consistency. Experimental results demonstrate that multimodal modeling and semantic feedback improve shot caption quality over RGB-only baselines. We further showcase the potential of BFMD by analyzing the temporal evolution of tactical patterns across full matches.
Expandable Decision-Making States for Multi-Agent Deep Reinforcement Learning in Soccer Tactical Analysis
Oct 01, 2025Invasion team sports such as soccer produce a high-dimensional, strongly coupled state space as many players continuously interact on a shared field, challenging quantitative tactical analysis. Traditional rule-based analyses are intuitive, while modern predictive machine learning models often perform pattern-matching without explicit agent representations. The problem we address is how to build player-level agent models from data, whose learned values and policies are both tactically interpretable and robust across heterogeneous data sources. Here, we propose Expandable Decision-Making States (EDMS), a semantically enriched state representation that augments raw positions and velocities with relational variables (e.g., scoring of space, pass, and score), combined with an action-masking scheme that gives on-ball and off-ball agents distinct decision sets. Compared to prior work, EDMS maps learned value functions and action policies to human-interpretable tactical concepts (e.g., marking pressure, passing lanes, ball accessibility) instead of raw coordinate features, and aligns agent choices with the rules of play. In the experiments, EDMS with action masking consistently reduced both action-prediction loss and temporal-difference (TD) error compared to the baseline. Qualitative case studies and Q-value visualizations further indicate that EDMS highlights high-risk, high-reward tactical patterns (e.g., fast counterattacks and defensive breakthroughs). We also integrated our approach into an open-source library and demonstrated compatibility with multiple commercial and open datasets, enabling cross-provider evaluation and reproducible experiments.
Evaluating Movement Initiation Timing in Ultimate Frisbee via Temporal Counterfactuals
Aug 25, 2025Ultimate is a sport where points are scored by passing a disc and catching it in the opposing team's end zone. In Ultimate, the player holding the disc cannot move, making field dynamics primarily driven by other players' movements. However, current literature in team sports has ignored quantitative evaluations of when players initiate such unlabeled movements in game situations. In this paper, we propose a quantitative evaluation method for movement initiation timing in Ultimate Frisbee. First, game footage was recorded using a drone camera, and players' positional data was obtained, which will be published as UltimateTrack dataset. Next, players' movement initiations were detected, and temporal counterfactual scenarios were generated by shifting the timing of movements using rule-based approaches. These scenarios were analyzed using a space evaluation metric based on soccer's pitch control reflecting the unique rules of Ultimate. By comparing the spatial evaluation values across scenarios, the difference between actual play and the most favorable counterfactual scenario was used to quantitatively assess the impact of movement timing. We validated our method and show that sequences in which the disc was actually thrown to the receiver received higher evaluation scores than the sequences without a throw. In practical verifications, the higher-skill group displays a broader distribution of time offsets from the model's optimal initiation point. These findings demonstrate that the proposed metric provides an objective means of assessing movement initiation timing, which has been difficult to quantify in unlabeled team sport plays.
VIFSS: View-Invariant and Figure Skating-Specific Pose Representation Learning for Temporal Action Segmentation
Aug 14, 2025Understanding human actions from videos plays a critical role across various domains, including sports analytics. In figure skating, accurately recognizing the type and timing of jumps a skater performs is essential for objective performance evaluation. However, this task typically requires expert-level knowledge due to the fine-grained and complex nature of jump procedures. While recent approaches have attempted to automate this task using Temporal Action Segmentation (TAS), there are two major limitations to TAS for figure skating: the annotated data is insufficient, and existing methods do not account for the inherent three-dimensional aspects and procedural structure of jump actions. In this work, we propose a new TAS framework for figure skating jumps that explicitly incorporates both the three-dimensional nature and the semantic procedure of jump movements. First, we propose a novel View-Invariant, Figure Skating-Specific pose representation learning approach (VIFSS) that combines contrastive learning as pre-training and action classification as fine-tuning. For view-invariant contrastive pre-training, we construct FS-Jump3D, the first publicly available 3D pose dataset specialized for figure skating jumps. Second, we introduce a fine-grained annotation scheme that marks the ``entry (preparation)'' and ``landing'' phases, enabling TAS models to learn the procedural structure of jumps. Extensive experiments demonstrate the effectiveness of our framework. Our method achieves over 92% F1@50 on element-level TAS, which requires recognizing both jump types and rotation levels. Furthermore, we show that view-invariant contrastive pre-training is particularly effective when fine-tuning data is limited, highlighting the practicality of our approach in real-world scenarios.
KASportsFormer: Kinematic Anatomy Enhanced Transformer for 3D Human Pose Estimation on Short Sports Scene Video
Jul 28, 2025Recent transformer based approaches have demonstrated impressive performance in solving real-world 3D human pose estimation problems. Albeit these approaches achieve fruitful results on benchmark datasets, they tend to fall short of sports scenarios where human movements are more complicated than daily life actions, as being hindered by motion blur, occlusions, and domain shifts. Moreover, due to the fact that critical motions in a sports game often finish in moments of time (e.g., shooting), the ability to focus on momentary actions is becoming a crucial factor in sports analysis, where current methods appear to struggle with instantaneous scenarios. To overcome these limitations, we introduce KASportsFormer, a novel transformer based 3D pose estimation framework for sports that incorporates a kinematic anatomy-informed feature representation and integration module. In which the inherent kinematic motion information is extracted with the Bone Extractor (BoneExt) and Limb Fuser (LimbFus) modules and encoded in a multimodal manner. This improved the capability of comprehending sports poses in short videos. We evaluate our method through two representative sports scene datasets: SportsPose and WorldPose. Experimental results show that our proposed method achieves state-of-the-art results with MPJPE errors of 58.0mm and 34.3mm, respectively. Our code and models are available at: https://github.com/jw0r1n/KASportsFormer
Velocity Completion Task and Method for Event-based Player Positional Data in Soccer
May 22, 2025In many real-world complex systems, the behavior can be observed as a collection of discrete events generated by multiple interacting agents. Analyzing the dynamics of these multi-agent systems, especially team sports, often relies on understanding the movement and interactions of individual agents. However, while providing valuable snapshots, event-based positional data typically lacks the continuous temporal information needed to directly calculate crucial properties such as velocity. This absence severely limits the depth of dynamic analysis, preventing a comprehensive understanding of individual agent behaviors and emergent team strategies. To address this challenge, we propose a new method to simultaneously complete the velocity of all agents using only the event-based positional data from team sports. Based on this completed velocity information, we investigate the applicability of existing team sports analysis and evaluation methods. Experiments using soccer event data demonstrate that neural network-based approaches outperformed rule-based methods regarding velocity completion error, considering the underlying temporal dependencies and graph structure of player-to-player or player-to-ball interaction. Moreover, the space evaluation results obtained using the completed velocity are closer to those derived from complete tracking data, highlighting our method's potential for enhanced team sports system analysis.
Automating quantum feature map design via large language models
Apr 10, 2025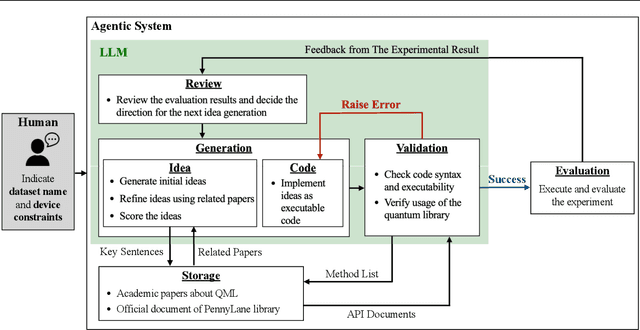
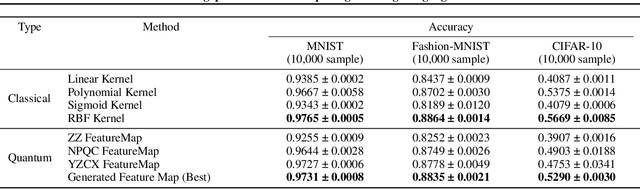
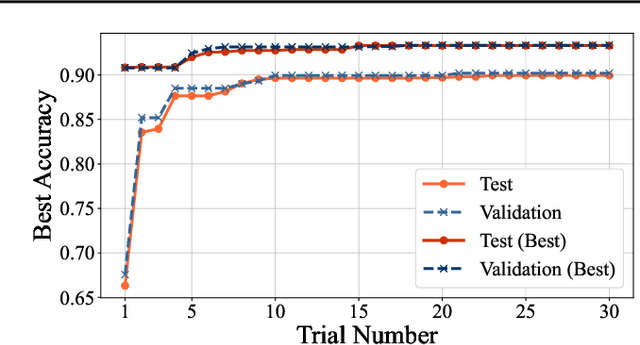
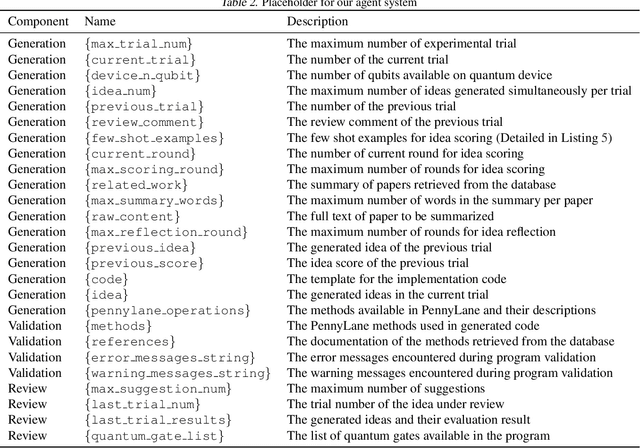
Quantum feature maps are a key component of quantum machine learning, encoding classical data into quantum states to exploit the expressive power of high-dimensional Hilbert spaces. Despite their theoretical promise, designing quantum feature maps that offer practical advantages over classical methods remains an open challenge. In this work, we propose an agentic system that autonomously generates, evaluates, and refines quantum feature maps using large language models. The system consists of five component: Generation, Storage, Validation, Evaluation, and Review. Using these components, it iteratively improves quantum feature maps. Experiments on the MNIST dataset show that it can successfully discover and refine feature maps without human intervention. The best feature map generated outperforms existing quantum baselines and achieves competitive accuracy compared to classical kernels across MNIST, Fashion-MNIST, and CIFAR-10. Our approach provides a framework for exploring dataset-adaptive quantum features and highlights the potential of LLM-driven automation in quantum algorithm design.
SoccerSynth Field: enhancing field detection with synthetic data from virtual soccer simulator
Mar 18, 2025
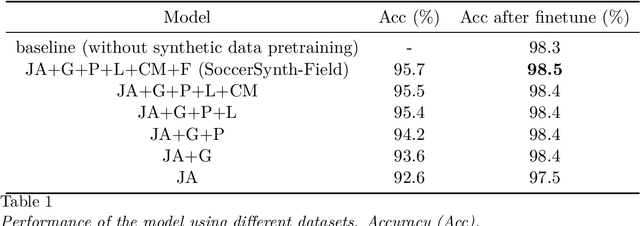
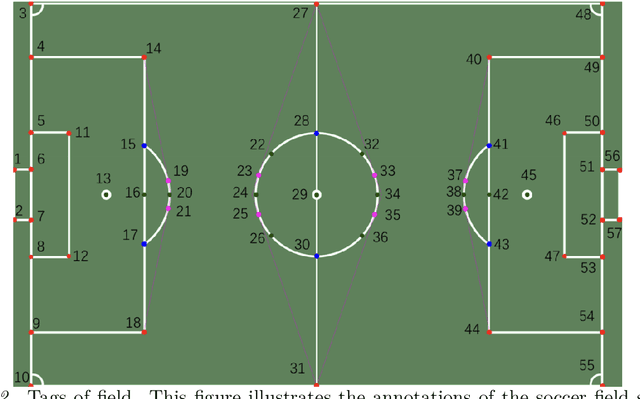

Field detection in team sports is an essential task in sports video analysis. However, collecting large-scale and diverse real-world datasets for training detection models is often cost and time-consuming. Synthetic datasets, which allow controlled variability in lighting, textures, and camera angles, will be a promising alternative for addressing these problems. This study addresses the challenges of high costs and difficulties in collecting real-world datasets by investigating the effectiveness of pretraining models using synthetic datasets. In this paper, we propose the effectiveness of using a synthetic dataset (SoccerSynth-Field) for soccer field detection. A synthetic soccer field dataset was created to pretrain models, and the performance of these models was compared with models trained on real-world datasets. The results demonstrate that models pretrained on the synthetic dataset exhibit superior performance in detecting soccer fields. This highlights the effectiveness of synthetic data in enhancing model robustness and accuracy, offering a cost-effective and scalable solution for advancing detection tasks in sports field detection.
AthletePose3D: A Benchmark Dataset for 3D Human Pose Estimation and Kinematic Validation in Athletic Movements
Mar 11, 2025Human pose estimation is a critical task in computer vision and sports biomechanics, with applications spanning sports science, rehabilitation, and biomechanical research. While significant progress has been made in monocular 3D pose estimation, current datasets often fail to capture the complex, high-acceleration movements typical of competitive sports. In this work, we introduce AthletePose3D, a novel dataset designed to address this gap. AthletePose3D includes 12 types of sports motions across various disciplines, with approximately 1.3 million frames and 165 thousand individual postures, specifically capturing high-speed, high-acceleration athletic movements. We evaluate state-of-the-art (SOTA) monocular 2D and 3D pose estimation models on the dataset, revealing that models trained on conventional datasets perform poorly on athletic motions. However, fine-tuning these models on AthletePose3D notably reduces the SOTA model mean per joint position error (MPJPE) from 214mm to 65mm-a reduction of over 69%. We also validate the kinematic accuracy of monocular pose estimations through waveform analysis, highlighting strong correlations in joint angle estimations but limitations in velocity estimation. Our work provides a comprehensive evaluation of monocular pose estimation models in the context of sports, contributing valuable insights for advancing monocular pose estimation techniques in high-performance sports environments. The dataset, code, and model checkpoints are available at: https://github.com/calvinyeungck/AthletePose3D
OpenSTARLab: Open Approach for Spatio-Temporal Agent Data Analysis in Soccer
Feb 06, 2025



Sports analytics has become both more professional and sophisticated, driven by the growing availability of detailed performance data. This progress enables applications such as match outcome prediction, player scouting, and tactical analysis. In soccer, the effective utilization of event and tracking data is fundamental for capturing and analyzing the dynamics of the game. However, there are two primary challenges: the limited availability of event data, primarily restricted to top-tier teams and leagues, and the scarcity and high cost of tracking data, which complicates its integration with event data for comprehensive analysis. Here we propose OpenSTARLab, an open-source framework designed to democratize spatio-temporal agent data analysis in sports by addressing these key challenges. OpenSTARLab includes the Pre-processing Package that standardizes event and tracking data through Unified and Integrated Event Data and State-Action-Reward formats, the Event Modeling Package that implements deep learning-based event prediction, alongside the RLearn Package for reinforcement learning tasks. These technical components facilitate the handling of diverse data sources and support advanced analytical tasks, thereby enhancing the overall functionality and usability of the framework. To assess OpenSTARLab's effectiveness, we conducted several experimental evaluations. These demonstrate the superior performance of the specific event prediction model in terms of action and time prediction accuracies and maintained its robust event simulation performance. Furthermore, reinforcement learning experiments reveal a trade-off between action accuracy and temporal difference loss and show comprehensive visualization. Overall, OpenSTARLab serves as a robust platform for researchers and practitioners, enhancing innovation and collaboration in the field of soccer data analytics.