 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSerial-OE: Anomalous sound detection based on serial method with outlier exposure capable of using small amounts of anomalous data for training
May 25, 2025We introduce Serial-OE, a new approach to anomalous sound detection (ASD) that leverages small amounts of anomalous data to improve the performance. Conventional ASD methods rely primarily on the modeling of normal data, due to the cost of collecting anomalous data from various possible types of equipment breakdowns. Our method improves upon existing ASD systems by implementing an outlier exposure framework that utilizes normal and pseudo-anomalous data for training, with the capability to also use small amounts of real anomalous data. A comprehensive evaluation using the DCASE2020 Task2 dataset shows that our method outperforms state-of-the-art ASD models. We also investigate the impact on performance of using a small amount of anomalous data during training, of using data without machine ID information, and of using contaminated training data. Our experimental results reveal the potential of using a very limited amount of anomalous data during training to address the limitations of existing methods using only normal data for training due to the scarcity of anomalous data. This study contributes to the field by presenting a method that can be dynamically adapted to include anomalous data during the operational phase of an ASD system, paving the way for more accurate ASD.
Improving Anomalous Sound Detection through Pseudo-anomalous Set Selection and Pseudo-label Utilization under Unlabeled Conditions
May 25, 2025This paper addresses performance degradation in anomalous sound detection (ASD) when neither sufficiently similar machine data nor operational state labels are available. We present an integrated pipeline that combines three complementary components derived from prior work and extends them to the unlabeled ASD setting. First, we adapt an anomaly score based selector to curate external audio data resembling the normal sounds of the target machine. Second, we utilize triplet learning to assign pseudo-labels to unlabeled data, enabling finer classification of operational sounds and detection of subtle anomalies. Third, we employ iterative training to refine both the pseudo-anomalous set selection and pseudo-label assignment, progressively improving detection accuracy. Experiments on the DCASE2022-2024 Task 2 datasets demonstrate that, in unlabeled settings, our approach achieves an average AUC increase of over 6.6 points compared to conventional methods. In labeled settings, incorporating external data from the pseudo-anomalous set further boosts performance. These results highlight the practicality and robustness of our methods in scenarios with scarce machine data and labels, facilitating ASD deployment across diverse industrial settings with minimal annotation effort.
Sparse Prototype Network for Explainable Pedestrian Behavior Prediction
Oct 16, 2024



Predicting pedestrian behavior is challenging yet crucial for applications such as autonomous driving and smart city. Recent deep learning models have achieved remarkable performance in making accurate predictions, but they fail to provide explanations of their inner workings. One reason for this problem is the multi-modal inputs. To bridge this gap, we present Sparse Prototype Network (SPN), an explainable method designed to simultaneously predict a pedestrian's future action, trajectory, and pose. SPN leverages an intermediate prototype bottleneck layer to provide sample-based explanations for its predictions. The prototypes are modality-independent, meaning that they can correspond to any modality from the input. Therefore, SPN can extend to arbitrary combinations of modalities. Regularized by mono-semanticity and clustering constraints, the prototypes learn consistent and human-understandable features and achieve state-of-the-art performance on action, trajectory and pose prediction on TITAN and PIE. Finally, we propose a metric named Top-K Mono-semanticity Scale to quantitatively evaluate the explainability. Qualitative results show the positive correlation between sparsity and explainability. Code available at https://github.com/Equinoxxxxx/SPN.
MulCPred: Learning Multi-modal Concepts for Explainable Pedestrian Action Prediction
Sep 14, 2024



Pedestrian action prediction is of great significance for many applications such as autonomous driving. However, state-of-the-art methods lack explainability to make trustworthy predictions. In this paper, a novel framework called MulCPred is proposed that explains its predictions based on multi-modal concepts represented by training samples. Previous concept-based methods have limitations including: 1) they cannot directly apply to multi-modal cases; 2) they lack locality to attend to details in the inputs; 3) they suffer from mode collapse. These limitations are tackled accordingly through the following approaches: 1) a linear aggregator to integrate the activation results of the concepts into predictions, which associates concepts of different modalities and provides ante-hoc explanations of the relevance between the concepts and the predictions; 2) a channel-wise recalibration module that attends to local spatiotemporal regions, which enables the concepts with locality; 3) a feature regularization loss that encourages the concepts to learn diverse patterns. MulCPred is evaluated on multiple datasets and tasks. Both qualitative and quantitative results demonstrate that MulCPred is promising in improving the explainability of pedestrian action prediction without obvious performance degradation. Furthermore, by removing unrecognizable concepts from MulCPred, the cross-dataset prediction performance is improved, indicating the feasibility of further generalizability of MulCPred.
DRUformer: Enhancing the driving scene Important object detection with driving relationship self-understanding
Nov 11, 2023
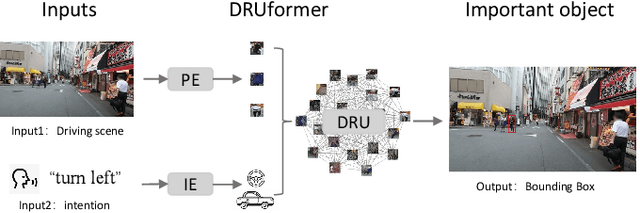
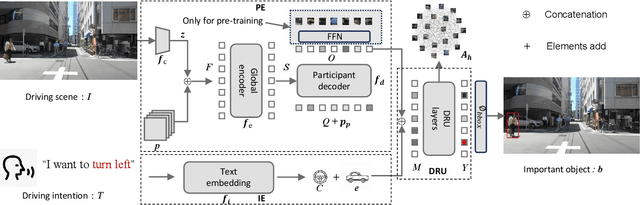
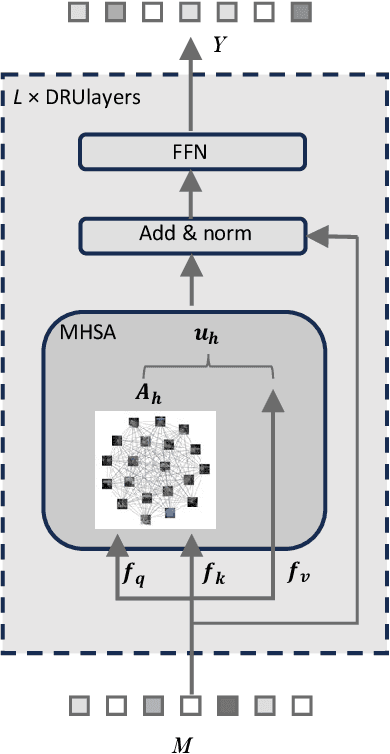
Traffic accidents frequently lead to fatal injuries, contributing to over 50 million deaths until 2023. To mitigate driving hazards and ensure personal safety, it is crucial to assist vehicles in anticipating important objects during travel. Previous research on important object detection primarily assessed the importance of individual participants, treating them as independent entities and frequently overlooking the connections between these participants. Unfortunately, this approach has proven less effective in detecting important objects in complex scenarios. In response, we introduce Driving scene Relationship self-Understanding transformer (DRUformer), designed to enhance the important object detection task. The DRUformer is a transformer-based multi-modal important object detection model that takes into account the relationships between all the participants in the driving scenario. Recognizing that driving intention also significantly affects the detection of important objects during driving, we have incorporated a module for embedding driving intention. To assess the performance of our approach, we conducted a comparative experiment on the DRAMA dataset, pitting our model against other state-of-the-art (SOTA) models. The results demonstrated a noteworthy 16.2\% improvement in mIoU and a substantial 12.3\% boost in ACC compared to SOTA methods. Furthermore, we conducted a qualitative analysis of our model's ability to detect important objects across different road scenarios and classes, highlighting its effectiveness in diverse contexts. Finally, we conducted various ablation studies to assess the efficiency of the proposed modules in our DRUformer model.
Runner re-identification from single-view video in the open-world setting
Oct 18, 2023In many sports, player re-identification is crucial for automatic video processing and analysis. However, most of the current studies on player re-identification in multi- or single-view sports videos focus on re-identification in the closed-world setting using labeled image dataset, and player re-identification in the open-world setting for automatic video analysis is not well developed. In this paper, we propose a runner re-identification system that directly processes single-view video to address the open-world setting. In the open-world setting, we cannot use labeled dataset and have to process video directly. The proposed system automatically processes raw video as input to identify runners, and it can identify runners even when they are framed out multiple times. For the automatic processing, we first detect the runners in the video using the pre-trained YOLOv8 and the fine-tuned EfficientNet. We then track the runners using ByteTrack and detect their shoes with the fine-tuned YOLOv8. Finally, we extract the image features of the runners using an unsupervised method using the gated recurrent unit autoencoder model. To improve the accuracy of runner re-identification, we use dynamic features of running sequence images. We evaluated the system on a running practice video dataset and showed that the proposed method identified runners with higher accuracy than one of the state-of-the-art models in unsupervised re-identification. We also showed that our unsupervised running dynamic feature extractor was effective for runner re-identification. Our runner re-identification system can be useful for the automatic analysis of running videos.
Compositional Semantics for Open Vocabulary Spatio-semantic Representations
Oct 08, 2023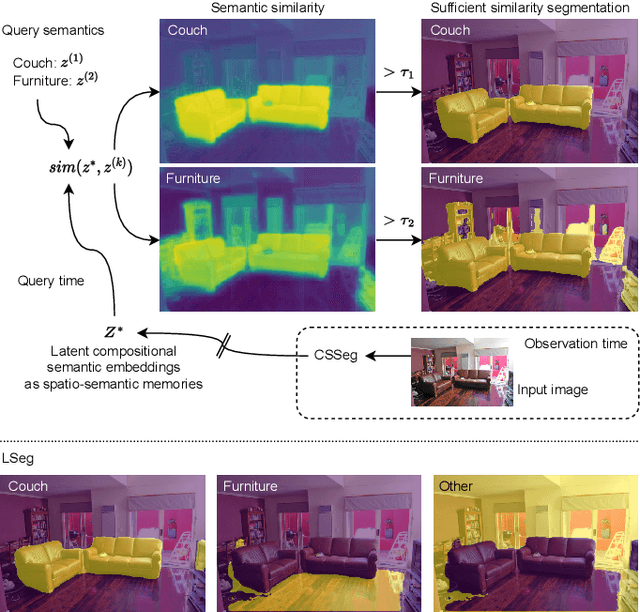
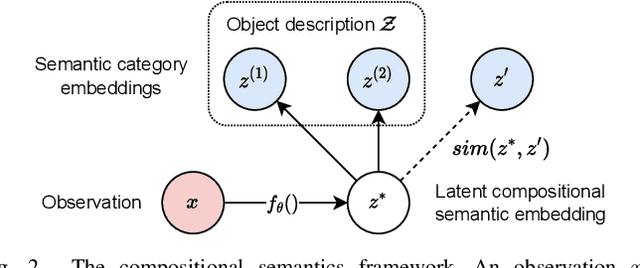
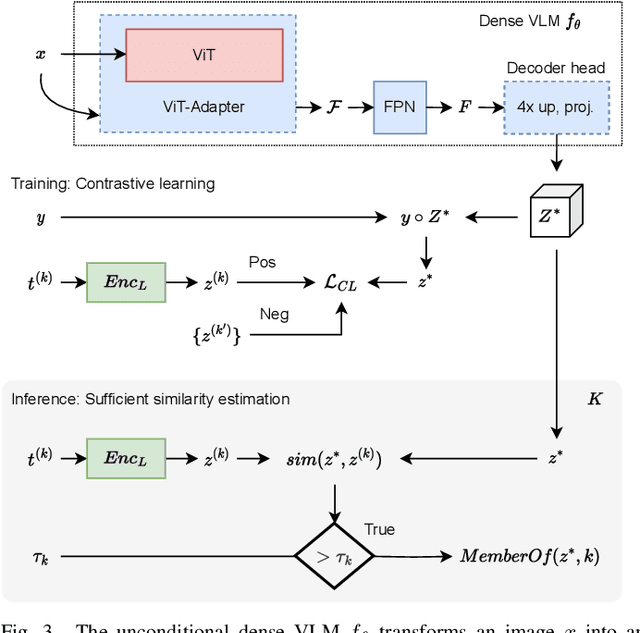
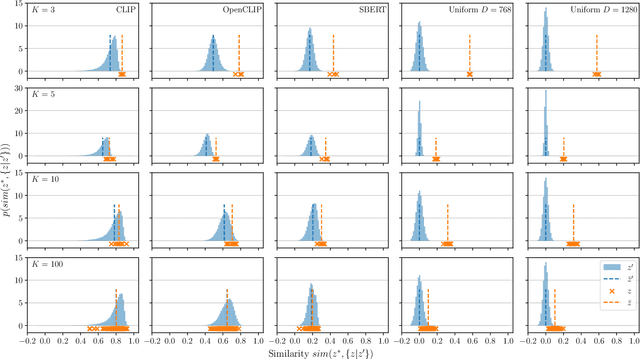
General-purpose mobile robots need to complete tasks without exact human instructions. Large language models (LLMs) is a promising direction for realizing commonsense world knowledge and reasoning-based planning. Vision-language models (VLMs) transform environment percepts into vision-language semantics interpretable by LLMs. However, completing complex tasks often requires reasoning about information beyond what is currently perceived. We propose latent compositional semantic embeddings z* as a principled learning-based knowledge representation for queryable spatio-semantic memories. We mathematically prove that z* can always be found, and the optimal z* is the centroid for any set Z. We derive a probabilistic bound for estimating separability of related and unrelated semantics. We prove that z* is discoverable by iterative optimization by gradient descent from visual appearance and singular descriptions. We experimentally verify our findings on four embedding spaces incl. CLIP and SBERT. Our results show that z* can represent up to 10 semantics encoded by SBERT, and up to 100 semantics for ideal uniformly distributed high-dimensional embeddings. We demonstrate that a simple dense VLM trained on the COCO-Stuff dataset can learn z* for 181 overlapping semantics by 42.23 mIoU, while improving conventional non-overlapping open-vocabulary segmentation performance by +3.48 mIoU compared with a popular SOTA model.
Audio Difference Learning for Audio Captioning
Sep 15, 2023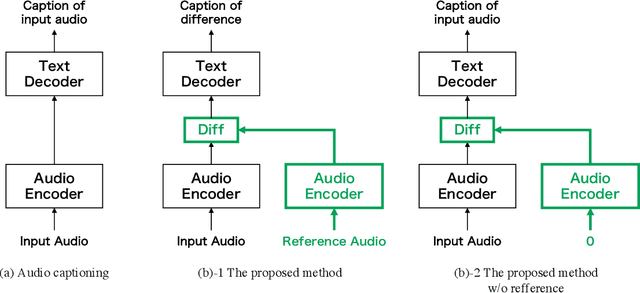

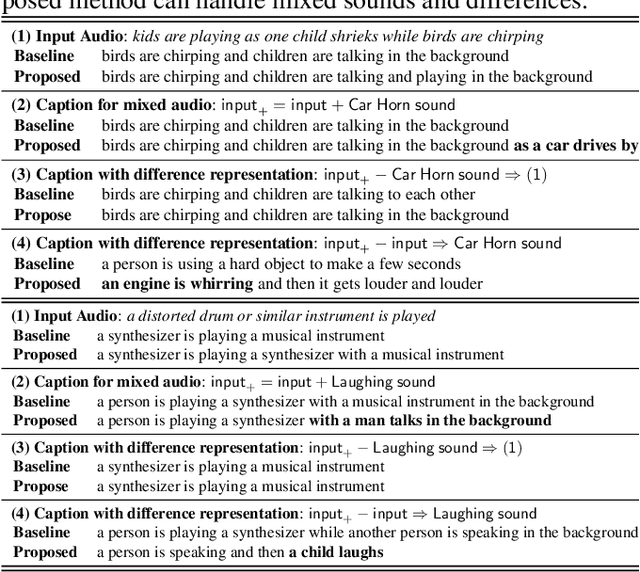
This study introduces a novel training paradigm, audio difference learning, for improving audio captioning. The fundamental concept of the proposed learning method is to create a feature representation space that preserves the relationship between audio, enabling the generation of captions that detail intricate audio information. This method employs a reference audio along with the input audio, both of which are transformed into feature representations via a shared encoder. Captions are then generated from these differential features to describe their differences. Furthermore, a unique technique is proposed that involves mixing the input audio with additional audio, and using the additional audio as a reference. This results in the difference between the mixed audio and the reference audio reverting back to the original input audio. This allows the original input's caption to be used as the caption for their difference, eliminating the need for additional annotations for the differences. In the experiments using the Clotho and ESC50 datasets, the proposed method demonstrated an improvement in the SPIDEr score by 7% compared to conventional methods.
R-Cut: Enhancing Explainability in Vision Transformers with Relationship Weighted Out and Cut
Jul 18, 2023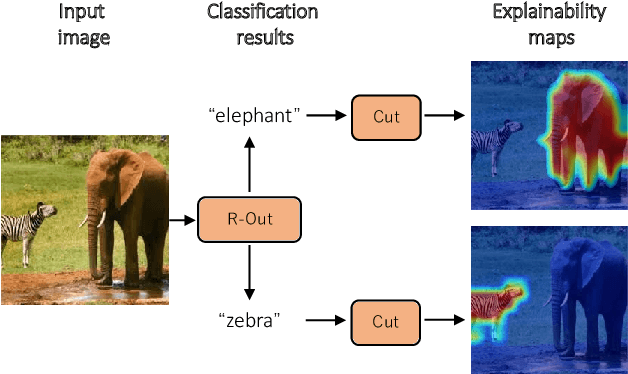
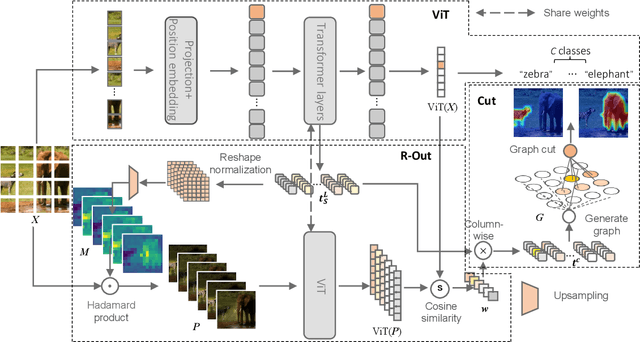


Transformer-based models have gained popularity in the field of natural language processing (NLP) and are extensively utilized in computer vision tasks and multi-modal models such as GPT4. This paper presents a novel method to enhance the explainability of Transformer-based image classification models. Our method aims to improve trust in classification results and empower users to gain a deeper understanding of the model for downstream tasks by providing visualizations of class-specific maps. We introduce two modules: the ``Relationship Weighted Out" and the ``Cut" modules. The ``Relationship Weighted Out" module focuses on extracting class-specific information from intermediate layers, enabling us to highlight relevant features. Additionally, the ``Cut" module performs fine-grained feature decomposition, taking into account factors such as position, texture, and color. By integrating these modules, we generate dense class-specific visual explainability maps. We validate our method with extensive qualitative and quantitative experiments on the ImageNet dataset. Furthermore, we conduct a large number of experiments on the LRN dataset, specifically designed for automatic driving danger alerts, to evaluate the explainability of our method in complex backgrounds. The results demonstrate a significant improvement over previous methods. Moreover, we conduct ablation experiments to validate the effectiveness of each module. Through these experiments, we are able to confirm the respective contributions of each module, thus solidifying the overall effectiveness of our proposed approach.
Action valuation of on- and off-ball soccer players based on multi-agent deep reinforcement learning
May 29, 2023



Analysis of invasive sports such as soccer is challenging because the game situation changes continuously in time and space, and multiple agents individually recognize the game situation and make decisions. Previous studies using deep reinforcement learning have often considered teams as a single agent and valued the teams and players who hold the ball in each discrete event. Then it was challenging to value the actions of multiple players, including players far from the ball, in a spatiotemporally continuous state space. In this paper, we propose a method of valuing possible actions for on- and off-ball soccer players in a single holistic framework based on multi-agent deep reinforcement learning. We consider a discrete action space in a continuous state space that mimics that of Google research football and leverages supervised learning for actions in reinforcement learning. In the experiment, we analyzed the relationships with conventional indicators, season goals, and game ratings by experts, and showed the effectiveness of the proposed method. Our approach can assess how multiple players move continuously throughout the game, which is difficult to be discretized or labeled but vital for teamwork, scouting, and fan engagement.