 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech-Worthy Alignment for Japanese SpeechLLMs via Direct Preference Optimization
Mar 13, 2026SpeechLLMs typically combine ASR-trained encoders with text-based LLM backbones, leading them to inherit written-style output patterns unsuitable for text-to-speech synthesis. This mismatch is particularly pronounced in Japanese, where spoken and written registers differ substantially in politeness markers, sentence-final particles, and syntactic complexity. We propose a preference-based alignment approach to adapt Japanese SpeechLLMs for speech-worthy outputs: text that is concise, conversational, and readily synthesized as natural speech. To rigorously evaluate this task, we introduce SpokenElyza, a benchmark for Japanese speech-worthiness derived from ELYZA-tasks-100 with auditory verification by native experts. Experiments show that our approach achieves substantial improvement on SpokenElyza while largely preserving performance on the original written-style evaluation. We will release SpokenElyza to support future research on Japanese spoken dialog systems.
Streaming Translation and Transcription Through Speech-to-Text Causal Alignment
Mar 12, 2026Simultaneous machine translation (SiMT) has traditionally relied on offline machine translation models coupled with human-engineered heuristics or learned policies. We propose Hikari, a policy-free, fully end-to-end model that performs simultaneous speech-to-text translation and streaming transcription by encoding READ/WRITE decisions into a probabilistic WAIT token mechanism. We also introduce Decoder Time Dilation, a mechanism that reduces autoregressive overhead and ensures a balanced training distribution. Additionally, we present a supervised fine-tuning strategy that trains the model to recover from delays, significantly improving the quality-latency trade-off. Evaluated on English-to-Japanese, German, and Russian, Hikari achieves new state-of-the-art BLEU scores in both low- and high-latency regimes, outperforming recent baselines.
DuplexCascade: Full-Duplex Speech-to-Speech Dialogue with VAD-Free Cascaded ASR-LLM-TTS Pipeline and Micro-Turn Optimization
Mar 10, 2026Spoken dialog systems with cascaded ASR-LLM-TTS modules retain strong LLM intelligence, but VAD segmentation often forces half-duplex turns and brittle control. On the other hand, VAD-free end-to-end model support full-duplex interaction but is hard to maintain conversational intelligence. In this paper, we present DuplexCascade, a VAD-free cascaded streaming pipeline for full-duplex speech-to-speech dialogue. Our key idea is to convert conventional utterance-wise long turns into chunk-wise micro-turn interactions, enabling rapid bidirectional exchange while preserving the strengths of a capable text LLM. To reliably coordinate turn-taking and response timing, we introduce a set of conversational special control tokens that steer the LLM's behavior under streaming constraints. On Full-DuplexBench and VoiceBench, DuplexCascade delivers state-of-the-art full-duplex turn-taking and strong conversational intelligence among open-source speech-to-speech dialogue systems.
AC/DC: LLM-based Audio Comprehension via Dialogue Continuation
Jun 12, 2025We propose an instruction-following audio comprehension model that leverages the dialogue continuation ability of large language models (LLMs). Instead of directly generating target captions in training data, the proposed method trains a model to produce responses as if the input caption triggered a dialogue. This dialogue continuation training mitigates the caption variation problem. Learning to continue a dialogue effectively captures the caption's meaning beyond its surface-level words. As a result, our model enables zero-shot instruction-following capability without multitask instruction tuning, even trained solely on audio captioning datasets. Experiments on AudioCaps, WavCaps, and Clotho datasets with AudioBench audio-scene question-answering tests demonstrate our model's ability to follow various unseen instructions.
OWSM-Biasing: Contextualizing Open Whisper-Style Speech Models for Automatic Speech Recognition with Dynamic Vocabulary
Jun 11, 2025



Speech foundation models (SFMs), such as Open Whisper-Style Speech Models (OWSM), are trained on massive datasets to achieve accurate automatic speech recognition. However, even SFMs struggle to accurately recognize rare and unseen words. While contextual biasing (CB) is a promising approach to improve recognition of such words, most CB methods are trained from scratch, resulting in lower performance than SFMs due to the lack of pre-trained knowledge. This paper integrates an existing CB method with OWSM v3.1 while freezing its pre-trained parameters. By leveraging the knowledge embedded in SFMs, the proposed method enables effective CB while preserving the advantages of SFMs, even with a small dataset. Experimental results show that the proposed method improves the biasing word error rate (B-WER) by 11.6 points, resulting in a 0.9 point improvement in the overall WER while reducing the real-time factor by 7.5% compared to the non-biasing baseline on the LibriSpeech 100 test-clean set.
Music Tagging with Classifier Group Chains
Jan 09, 2025



We propose music tagging with classifier chains that model the interplay of music tags. Most conventional methods estimate multiple tags independently by treating them as multiple independent binary classification problems. This treatment overlooks the conditional dependencies among music tags, leading to suboptimal tagging performance. Unlike most music taggers, the proposed method sequentially estimates each tag based on the idea of the classifier chains. Beyond the naive classifier chains, the proposed method groups the multiple tags by category, such as genre, and performs chains by unit of groups, which we call \textit{classifier group chains}. Our method allows the modeling of the dependence between tag groups. We evaluate the effectiveness of the proposed method for music tagging performance through music tagging experiments using the MTG-Jamendo dataset. Furthermore, we investigate the effective order of chains for music tagging.
Song Data Cleansing for End-to-End Neural Singer Diarization Using Neural Analysis and Synthesis Framework
Jun 24, 2024



We propose a data cleansing method that utilizes a neural analysis and synthesis (NANSY++) framework to train an end-to-end neural diarization model (EEND) for singer diarization. Our proposed model converts song data with choral singing which is commonly contained in popular music and unsuitable for generating a simulated dataset to the solo singing data. This cleansing is based on NANSY++, which is a framework trained to reconstruct an input non-overlapped audio signal. We exploit the pre-trained NANSY++ to convert choral singing into clean, non-overlapped audio. This cleansing process mitigates the mislabeling of choral singing to solo singing and helps the effective training of EEND models even when the majority of available song data contains choral singing sections. We experimentally evaluated the EEND model trained with a dataset using our proposed method using annotated popular duet songs. As a result, our proposed method improved 14.8 points in diarization error rate.
Audio Fingerprinting with Holographic Reduced Representations
Jun 19, 2024



This paper proposes an audio fingerprinting model with holographic reduced representation (HRR). The proposed method reduces the number of stored fingerprints, whereas conventional neural audio fingerprinting requires many fingerprints for each audio track to achieve high accuracy and time resolution. We utilize HRR to aggregate multiple fingerprints into a composite fingerprint via circular convolution and summation, resulting in fewer fingerprints with the same dimensional space as the original. Our search method efficiently finds a combined fingerprint in which a query fingerprint exists. Using HRR's inverse operation, it can recover the relative position within a combined fingerprint, retaining the original time resolution. Experiments show that our method can reduce the number of fingerprints with modest accuracy degradation while maintaining the time resolution, outperforming simple decimation and summation-based aggregation methods.
Universal Score-based Speech Enhancement with High Content Preservation
Jun 18, 2024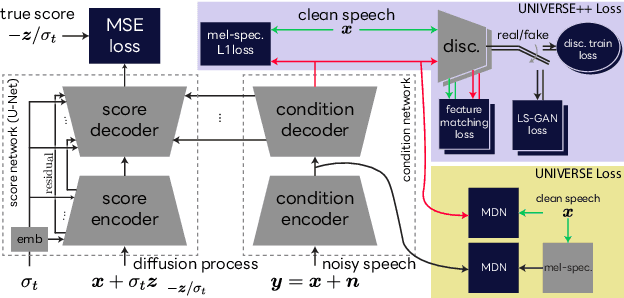
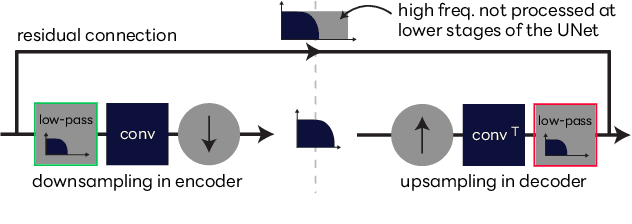
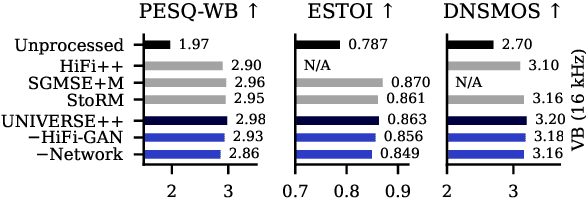
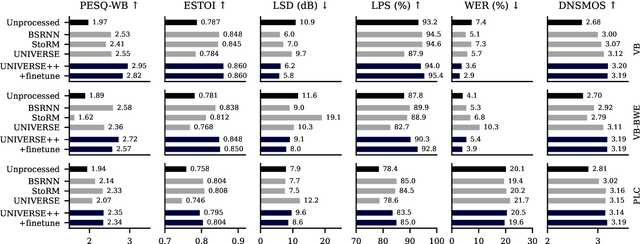
We propose UNIVERSE++, a universal speech enhancement method based on score-based diffusion and adversarial training. Specifically, we improve the existing UNIVERSE model that decouples clean speech feature extraction and diffusion. Our contributions are three-fold. First, we make several modifications to the network architecture, improving training stability and final performance. Second, we introduce an adversarial loss to promote learning high quality speech features. Third, we propose a low-rank adaptation scheme with a phoneme fidelity loss to improve content preservation in the enhanced speech. In the experiments, we train a universal enhancement model on a large scale dataset of speech degraded by noise, reverberation, and various distortions. The results on multiple public benchmark datasets demonstrate that UNIVERSE++ compares favorably to both discriminative and generative baselines for a wide range of qualitative and intelligibility metrics.
Acoustic modeling for Overlapping Speech Recognition: JHU Chime-5 Challenge System
May 17, 2024This paper summarizes our acoustic modeling efforts in the Johns Hopkins University speech recognition system for the CHiME-5 challenge to recognize highly-overlapped dinner party speech recorded by multiple microphone arrays. We explore data augmentation approaches, neural network architectures, front-end speech dereverberation, beamforming and robust i-vector extraction with comparisons of our in-house implementations and publicly available tools. We finally achieved a word error rate of 69.4% on the development set, which is a 11.7% absolute improvement over the previous baseline of 81.1%, and release this improved baseline with refined techniques/tools as an advanced CHiME-5 recipe.
* Published in: ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)