 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMusic Tagging with Classifier Group Chains
Jan 09, 2025



We propose music tagging with classifier chains that model the interplay of music tags. Most conventional methods estimate multiple tags independently by treating them as multiple independent binary classification problems. This treatment overlooks the conditional dependencies among music tags, leading to suboptimal tagging performance. Unlike most music taggers, the proposed method sequentially estimates each tag based on the idea of the classifier chains. Beyond the naive classifier chains, the proposed method groups the multiple tags by category, such as genre, and performs chains by unit of groups, which we call \textit{classifier group chains}. Our method allows the modeling of the dependence between tag groups. We evaluate the effectiveness of the proposed method for music tagging performance through music tagging experiments using the MTG-Jamendo dataset. Furthermore, we investigate the effective order of chains for music tagging.
LibriTTS-P: A Corpus with Speaking Style and Speaker Identity Prompts for Text-to-Speech and Style Captioning
Jun 12, 2024



We introduce LibriTTS-P, a new corpus based on LibriTTS-R that includes utterance-level descriptions (i.e., prompts) of speaking style and speaker-level prompts of speaker characteristics. We employ a hybrid approach to construct prompt annotations: (1) manual annotations that capture human perceptions of speaker characteristics and (2) synthetic annotations on speaking style. Compared to existing English prompt datasets, our corpus provides more diverse prompt annotations for all speakers of LibriTTS-R. Experimental results for prompt-based controllable TTS demonstrate that the TTS model trained with LibriTTS-P achieves higher naturalness than the model using the conventional dataset. Furthermore, the results for style captioning tasks show that the model utilizing LibriTTS-P generates 2.5 times more accurate words than the model using a conventional dataset. Our corpus, LibriTTS-P, is available at https://github.com/line/LibriTTS-P.
Multichannel Audio Source Separation with Independent Deeply Learned Matrix Analysis Using Product of Source Models
Sep 02, 2021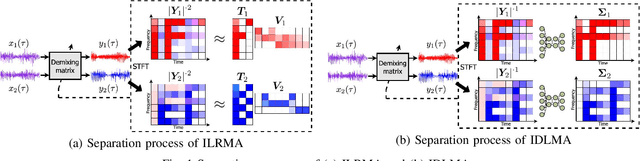
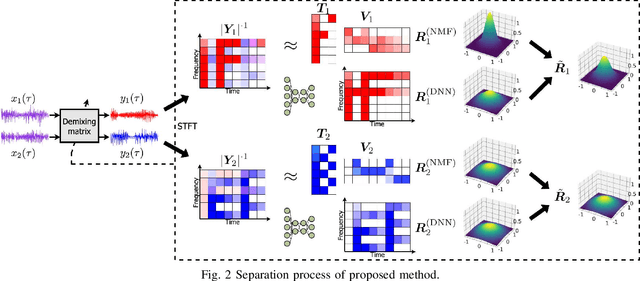
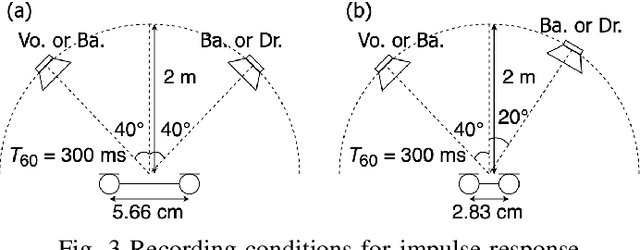
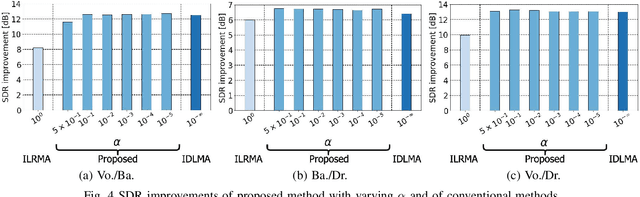
Independent deeply learned matrix analysis (IDLMA) is one of the state-of-the-art multichannel audio source separation methods using the source power estimation based on deep neural networks (DNNs). The DNN-based power estimation works well for sounds having timbres similar to the DNN training data. However, the sounds to which IDLMA is applied do not always have such timbres, and the timbral mismatch causes the performance degradation of IDLMA. To tackle this problem, we focus on a blind source separation counterpart of IDLMA, independent low-rank matrix analysis. It uses nonnegative matrix factorization (NMF) as the source model, which can capture source spectral components that only appear in the target mixture, using the low-rank structure of the source spectrogram as a clue. We thus extend the DNN-based source model to encompass the NMF-based source model on the basis of the product-of-expert concept, which we call the product of source models (PoSM). For the proposed PoSM-based IDLMA, we derive a computationally efficient parameter estimation algorithm based on an optimization principle called the majorization-minimization algorithm. Experimental evaluations show the effectiveness of the proposed method.
Empirical Bayesian Independent Deeply Learned Matrix Analysis For Multichannel Audio Source Separation
Jun 07, 2021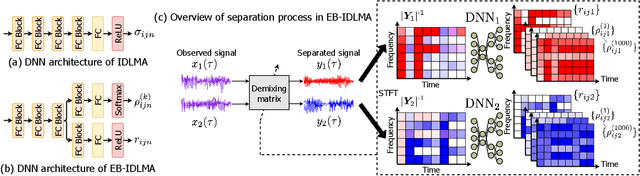
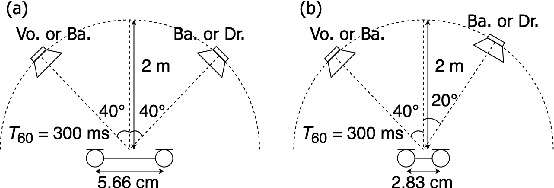
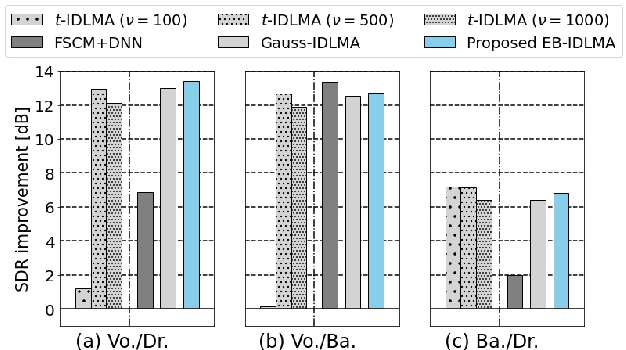
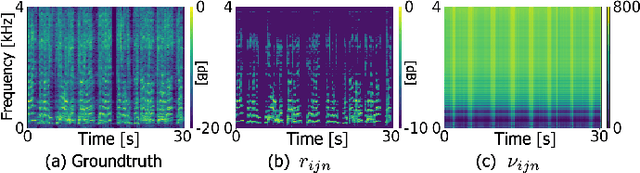
Independent deeply learned matrix analysis (IDLMA) is one of the state-of-the-art supervised multichannel audio source separation methods. It blindly estimates the demixing filters on the basis of source independence, using the source model estimated by the deep neural network (DNN). However, since the ratios of the source to interferer signals vary widely among time-frequency (TF) slots, it is difficult to obtain reliable estimated power spectrograms of sources at all TF slots. In this paper, we propose an IDLMA extension, empirical Bayesian IDLMA (EB-IDLMA), by introducing a prior distribution of source power spectrograms and treating the source power spectrograms as latent random variables. This treatment allows us to implicitly consider the reliability of the estimated source power spectrograms for the estimation of demixing filters through the hyperparameters of the prior distribution estimated by the DNN. Experimental evaluations show the effectiveness of EB-IDLMA and the importance of introducing the reliability of the estimated source power spectrograms.