 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCC-G2PnP: Streaming Grapheme-to-Phoneme and prosody with Conformer-CTC for unsegmented languages
Feb 19, 2026We propose CC-G2PnP, a streaming grapheme-to-phoneme and prosody (G2PnP) model to connect large language model and text-to-speech in a streaming manner. CC-G2PnP is based on Conformer-CTC architecture. Specifically, the input grapheme tokens are processed chunk by chunk, which enables streaming inference of phonemic and prosodic (PnP) labels. By guaranteeing minimal look-ahead size to each input token, the proposed model can consider future context in each token, which leads to stable PnP label prediction. Unlike previous streaming methods that depend on explicit word boundaries, the CTC decoder in CC-G2PnP effectively learns the alignment between graphemes and phonemes during training, making it applicable to unsegmented languages. Experiments on a Japanese dataset, which has no explicit word boundaries, show that CC-G2PnP significantly outperforms the baseline streaming G2PnP model in the accuracy of PnP label prediction.
Wave-Trainer-Fit: Neural Vocoder with Trainable Prior and Fixed-Point Iteration towards High-Quality Speech Generation from SSL features
Feb 05, 2026We propose WaveTrainerFit, a neural vocoder that performs high-quality waveform generation from data-driven features such as SSL features. WaveTrainerFit builds upon the WaveFit vocoder, which integrates diffusion model and generative adversarial network. Furthermore, the proposed method incorporates the following key improvements: 1. By introducing trainable priors, the inference process starts from noise close to the target speech instead of Gaussian noise. 2. Reference-aware gain adjustment is performed by imposing constraints on the trainable prior to matching the speech energy. These improvements are expected to reduce the complexity of waveform modeling from data-driven features, enabling high-quality waveform generation with fewer inference steps. Through experiments, we showed that WaveTrainerFit can generate highly natural waveforms with improved speaker similarity from data-driven features, while requiring fewer iterations than WaveFit. Moreover, we showed that the proposed method works robustly with respect to the depth at which SSL features are extracted. Code and pre-trained models are available from https://github.com/line/WaveTrainerFit.
SLASH: Self-Supervised Speech Pitch Estimation Leveraging DSP-derived Absolute Pitch
Jul 23, 2025We present SLASH, a pitch estimation method of speech signals based on self-supervised learning (SSL). To enhance the performance of conventional SSL-based approaches that primarily depend on the relative pitch difference derived from pitch shifting, our method incorporates absolute pitch values by 1) introducing a prior pitch distribution derived from digital signal processing (DSP), and 2) optimizing absolute pitch through gradient descent with a loss between the target and differentiable DSP-derived spectrograms. To stabilize the optimization, a novel spectrogram generation method is used that skips complicated waveform generation. In addition, the aperiodic components in speech are accurately predicted through differentiable DSP, enhancing the method's applicability to speech signal processing. Experimental results showed that the proposed method outperformed both baseline DSP and SSL-based pitch estimation methods, attributed to the effective integration of SSL and DSP.
Grapheme-Coherent Phonemic and Prosodic Annotation of Speech by Implicit and Explicit Grapheme Conditioning
Jun 05, 2025We propose a model to obtain phonemic and prosodic labels of speech that are coherent with graphemes. Unlike previous methods that simply fine-tune a pre-trained ASR model with the labels, the proposed model conditions the label generation on corresponding graphemes by two methods: 1) Add implicit grapheme conditioning through prompt encoder using pre-trained BERT features. 2) Explicitly prune the label hypotheses inconsistent with the grapheme during inference. These methods enable obtaining parallel data of speech, the labels, and graphemes, which is applicable to various downstream tasks such as text-to-speech and accent estimation from text. Experiments showed that the proposed method significantly improved the consistency between graphemes and the predicted labels. Further, experiments on accent estimation task confirmed that the created parallel data by the proposed method effectively improve the estimation accuracy.
Description-based Controllable Text-to-Speech with Cross-Lingual Voice Control
Sep 26, 2024We propose a novel description-based controllable text-to-speech (TTS) method with cross-lingual control capability. To address the lack of audio-description paired data in the target language, we combine a TTS model trained on the target language with a description control model trained on another language, which maps input text descriptions to the conditional features of the TTS model. These two models share disentangled timbre and style representations based on self-supervised learning (SSL), allowing for disentangled voice control, such as controlling speaking styles while retaining the original timbre. Furthermore, because the SSL-based timbre and style representations are language-agnostic, combining the TTS and description control models while sharing the same embedding space effectively enables cross-lingual control of voice characteristics. Experiments on English and Japanese TTS demonstrate that our method achieves high naturalness and controllability for both languages, even though no Japanese audio-description pairs are used.
Universal Score-based Speech Enhancement with High Content Preservation
Jun 18, 2024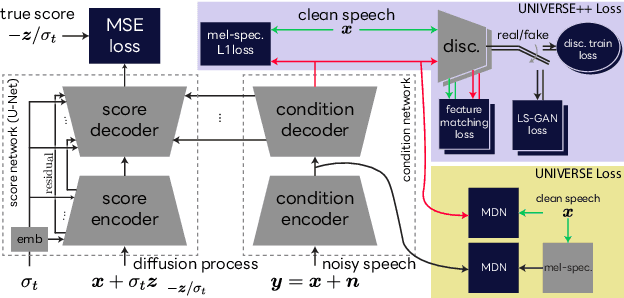
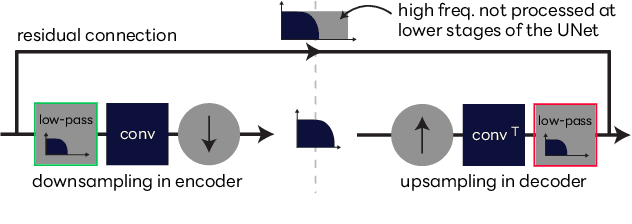
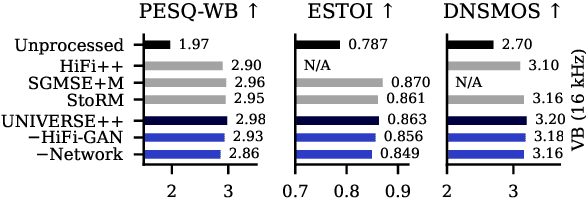
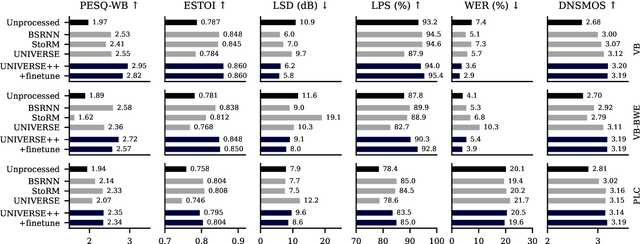
We propose UNIVERSE++, a universal speech enhancement method based on score-based diffusion and adversarial training. Specifically, we improve the existing UNIVERSE model that decouples clean speech feature extraction and diffusion. Our contributions are three-fold. First, we make several modifications to the network architecture, improving training stability and final performance. Second, we introduce an adversarial loss to promote learning high quality speech features. Third, we propose a low-rank adaptation scheme with a phoneme fidelity loss to improve content preservation in the enhanced speech. In the experiments, we train a universal enhancement model on a large scale dataset of speech degraded by noise, reverberation, and various distortions. The results on multiple public benchmark datasets demonstrate that UNIVERSE++ compares favorably to both discriminative and generative baselines for a wide range of qualitative and intelligibility metrics.
LibriTTS-P: A Corpus with Speaking Style and Speaker Identity Prompts for Text-to-Speech and Style Captioning
Jun 12, 2024



We introduce LibriTTS-P, a new corpus based on LibriTTS-R that includes utterance-level descriptions (i.e., prompts) of speaking style and speaker-level prompts of speaker characteristics. We employ a hybrid approach to construct prompt annotations: (1) manual annotations that capture human perceptions of speaker characteristics and (2) synthetic annotations on speaking style. Compared to existing English prompt datasets, our corpus provides more diverse prompt annotations for all speakers of LibriTTS-R. Experimental results for prompt-based controllable TTS demonstrate that the TTS model trained with LibriTTS-P achieves higher naturalness than the model using the conventional dataset. Furthermore, the results for style captioning tasks show that the model utilizing LibriTTS-P generates 2.5 times more accurate words than the model using a conventional dataset. Our corpus, LibriTTS-P, is available at https://github.com/line/LibriTTS-P.
Audio-conditioned phonemic and prosodic annotation for building text-to-speech models from unlabeled speech data
Jun 12, 2024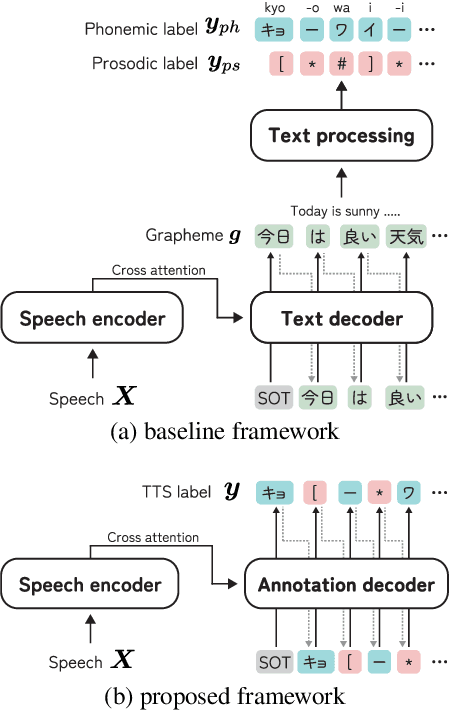
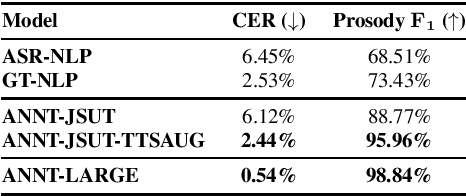
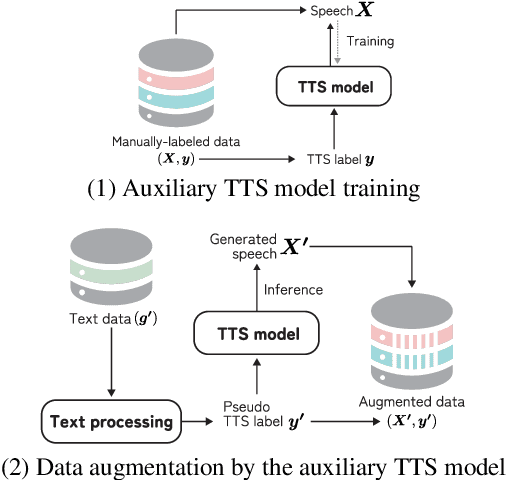

This paper proposes an audio-conditioned phonemic and prosodic annotation model for building text-to-speech (TTS) datasets from unlabeled speech samples. For creating a TTS dataset that consists of label-speech paired data, the proposed annotation model leverages an automatic speech recognition (ASR) model to obtain phonemic and prosodic labels from unlabeled speech samples. By fine-tuning a large-scale pre-trained ASR model, we can construct the annotation model using a limited amount of label-speech paired data within an existing TTS dataset. To alleviate the shortage of label-speech paired data for training the annotation model, we generate pseudo label-speech paired data using text-only corpora and an auxiliary TTS model. This TTS model is also trained with the existing TTS dataset. Experimental results show that the TTS model trained with the dataset created by the proposed annotation method can synthesize speech as naturally as the one trained with a fully-labeled dataset.
PromptTTS++: Controlling Speaker Identity in Prompt-Based Text-to-Speech Using Natural Language Descriptions
Sep 15, 2023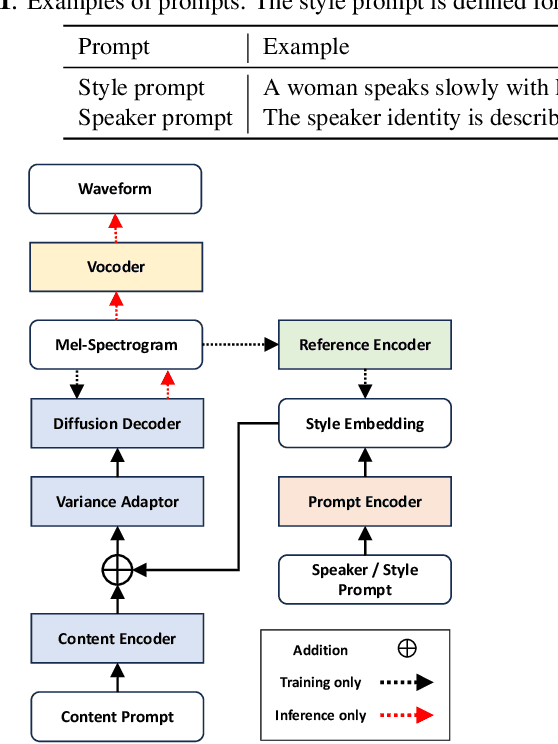
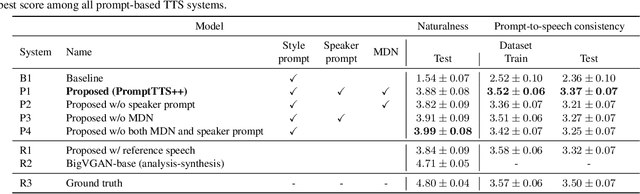
We propose PromptTTS++, a prompt-based text-to-speech (TTS) synthesis system that allows control over speaker identity using natural language descriptions. To control speaker identity within the prompt-based TTS framework, we introduce the concept of speaker prompt, which describes voice characteristics (e.g., gender-neutral, young, old, and muffled) designed to be approximately independent of speaking style. Since there is no large-scale dataset containing speaker prompts, we first construct a dataset based on the LibriTTS-R corpus with manually annotated speaker prompts. We then employ a diffusion-based acoustic model with mixture density networks to model diverse speaker factors in the training data. Unlike previous studies that rely on style prompts describing only a limited aspect of speaker individuality, such as pitch, speaking speed, and energy, our method utilizes an additional speaker prompt to effectively learn the mapping from natural language descriptions to the acoustic features of diverse speakers. Our subjective evaluation results show that the proposed method can better control speaker characteristics than the methods without the speaker prompt. Audio samples are available at https://reppy4620.github.io/demo.promptttspp/.
Lightweight and High-Fidelity End-to-End Text-to-Speech with Multi-Band Generation and Inverse Short-Time Fourier Transform
Oct 28, 2022
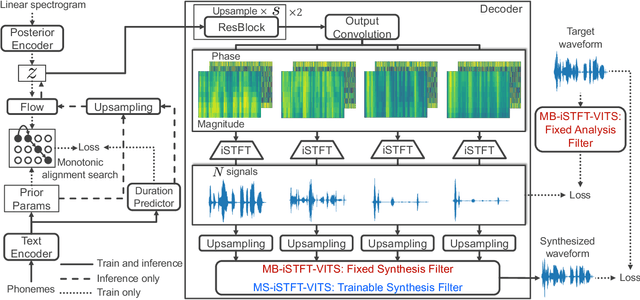

We propose a lightweight end-to-end text-to-speech model using multi-band generation and inverse short-time Fourier transform. Our model is based on VITS, a high-quality end-to-end text-to-speech model, but adopts two changes for more efficient inference: 1) the most computationally expensive component is partially replaced with a simple inverse short-time Fourier transform, and 2) multi-band generation, with fixed or trainable synthesis filters, is used to generate waveforms. Unlike conventional lightweight models, which employ optimization or knowledge distillation separately to train two cascaded components, our method enjoys the full benefits of end-to-end optimization. Experimental results show that our model synthesized speech as natural as that synthesized by VITS, while achieving a real-time factor of 0.066 on an Intel Core i7 CPU, 4.1 times faster than VITS. Moreover, a smaller version of the model significantly outperformed a lightweight baseline model with respect to both naturalness and inference speed. Code and audio samples are available from https://github.com/MasayaKawamura/MB-iSTFT-VITS.