 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSchödinger Bridge Type Diffusion Models as an Extension of Variational Autoencoders
Dec 24, 2024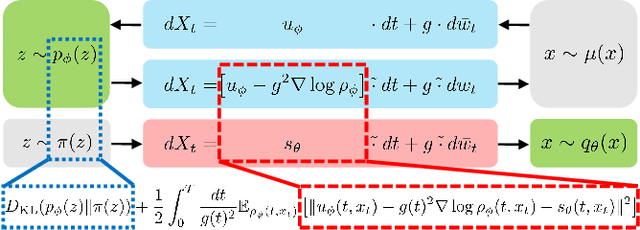
Generative diffusion models use time-forward and backward stochastic differential equations to connect the data and prior distributions. While conventional diffusion models (e.g., score-based models) only learn the backward process, more flexible frameworks have been proposed to also learn the forward process by employing the Schr\"odinger bridge (SB). However, due to the complexity of the mathematical structure behind SB-type models, we can not easily give an intuitive understanding of their objective function. In this work, we propose a unified framework to construct diffusion models by reinterpreting the SB-type models as an extension of variational autoencoders. In this context, the data processing inequality plays a crucial role. As a result, we find that the objective function consists of the prior loss and drift matching parts.
PromptTTS++: Controlling Speaker Identity in Prompt-Based Text-to-Speech Using Natural Language Descriptions
Sep 15, 2023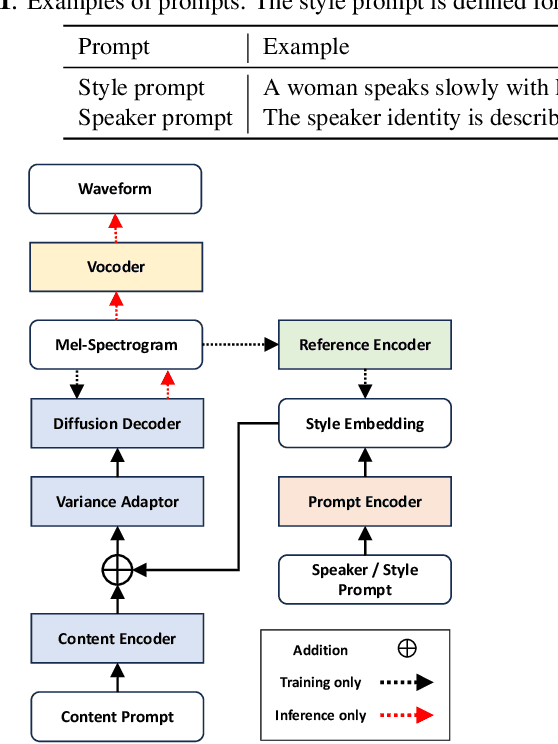
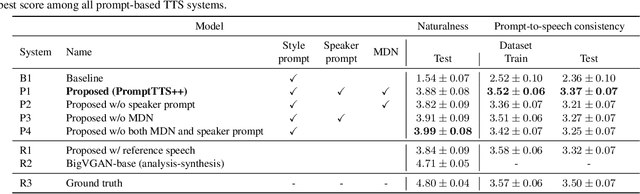
We propose PromptTTS++, a prompt-based text-to-speech (TTS) synthesis system that allows control over speaker identity using natural language descriptions. To control speaker identity within the prompt-based TTS framework, we introduce the concept of speaker prompt, which describes voice characteristics (e.g., gender-neutral, young, old, and muffled) designed to be approximately independent of speaking style. Since there is no large-scale dataset containing speaker prompts, we first construct a dataset based on the LibriTTS-R corpus with manually annotated speaker prompts. We then employ a diffusion-based acoustic model with mixture density networks to model diverse speaker factors in the training data. Unlike previous studies that rely on style prompts describing only a limited aspect of speaker individuality, such as pitch, speaking speed, and energy, our method utilizes an additional speaker prompt to effectively learn the mapping from natural language descriptions to the acoustic features of diverse speakers. Our subjective evaluation results show that the proposed method can better control speaker characteristics than the methods without the speaker prompt. Audio samples are available at https://reppy4620.github.io/demo.promptttspp/.