 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCC-G2PnP: Streaming Grapheme-to-Phoneme and prosody with Conformer-CTC for unsegmented languages
Feb 19, 2026We propose CC-G2PnP, a streaming grapheme-to-phoneme and prosody (G2PnP) model to connect large language model and text-to-speech in a streaming manner. CC-G2PnP is based on Conformer-CTC architecture. Specifically, the input grapheme tokens are processed chunk by chunk, which enables streaming inference of phonemic and prosodic (PnP) labels. By guaranteeing minimal look-ahead size to each input token, the proposed model can consider future context in each token, which leads to stable PnP label prediction. Unlike previous streaming methods that depend on explicit word boundaries, the CTC decoder in CC-G2PnP effectively learns the alignment between graphemes and phonemes during training, making it applicable to unsegmented languages. Experiments on a Japanese dataset, which has no explicit word boundaries, show that CC-G2PnP significantly outperforms the baseline streaming G2PnP model in the accuracy of PnP label prediction.
Grapheme-Coherent Phonemic and Prosodic Annotation of Speech by Implicit and Explicit Grapheme Conditioning
Jun 05, 2025We propose a model to obtain phonemic and prosodic labels of speech that are coherent with graphemes. Unlike previous methods that simply fine-tune a pre-trained ASR model with the labels, the proposed model conditions the label generation on corresponding graphemes by two methods: 1) Add implicit grapheme conditioning through prompt encoder using pre-trained BERT features. 2) Explicitly prune the label hypotheses inconsistent with the grapheme during inference. These methods enable obtaining parallel data of speech, the labels, and graphemes, which is applicable to various downstream tasks such as text-to-speech and accent estimation from text. Experiments showed that the proposed method significantly improved the consistency between graphemes and the predicted labels. Further, experiments on accent estimation task confirmed that the created parallel data by the proposed method effectively improve the estimation accuracy.
Wavehax: Aliasing-Free Neural Waveform Synthesis Based on 2D Convolution and Harmonic Prior for Reliable Complex Spectrogram Estimation
Nov 11, 2024



Neural vocoders often struggle with aliasing in latent feature spaces, caused by time-domain nonlinear operations and resampling layers. Aliasing folds high-frequency components into the low-frequency range, making aliased and original frequency components indistinguishable and introducing two practical issues. First, aliasing complicates the waveform generation process, as the subsequent layers must address these aliasing effects, increasing the computational complexity. Second, it limits extrapolation performance, particularly in handling high fundamental frequencies, which degrades the perceptual quality of generated speech waveforms. This paper demonstrates that 1) time-domain nonlinear operations inevitably introduce aliasing but provide a strong inductive bias for harmonic generation, and 2) time-frequency-domain processing can achieve aliasing-free waveform synthesis but lacks the inductive bias for effective harmonic generation. Building on this insight, we propose Wavehax, an aliasing-free neural WAVEform generator that integrates 2D convolution and a HArmonic prior for reliable Complex Spectrogram estimation. Experimental results show that Wavehax achieves speech quality comparable to existing high-fidelity neural vocoders and exhibits exceptional robustness in scenarios requiring high fundamental frequency extrapolation, where aliasing effects become typically severe. Moreover, Wavehax requires less than 5% of the multiply-accumulate operations and model parameters compared to HiFi-GAN V1, while achieving over four times faster CPU inference speed.
Description-based Controllable Text-to-Speech with Cross-Lingual Voice Control
Sep 26, 2024We propose a novel description-based controllable text-to-speech (TTS) method with cross-lingual control capability. To address the lack of audio-description paired data in the target language, we combine a TTS model trained on the target language with a description control model trained on another language, which maps input text descriptions to the conditional features of the TTS model. These two models share disentangled timbre and style representations based on self-supervised learning (SSL), allowing for disentangled voice control, such as controlling speaking styles while retaining the original timbre. Furthermore, because the SSL-based timbre and style representations are language-agnostic, combining the TTS and description control models while sharing the same embedding space effectively enables cross-lingual control of voice characteristics. Experiments on English and Japanese TTS demonstrate that our method achieves high naturalness and controllability for both languages, even though no Japanese audio-description pairs are used.
SVDD 2024: The Inaugural Singing Voice Deepfake Detection Challenge
Aug 28, 2024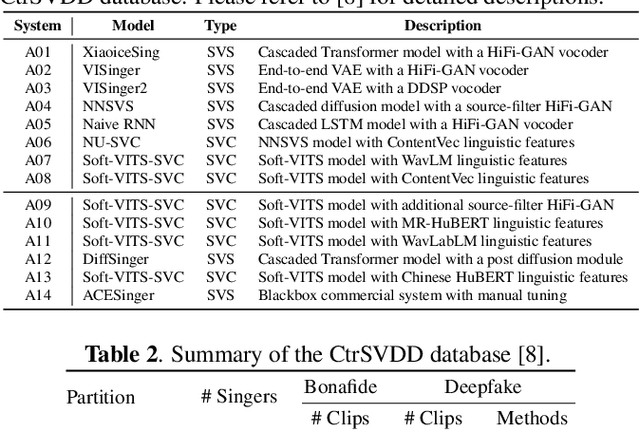
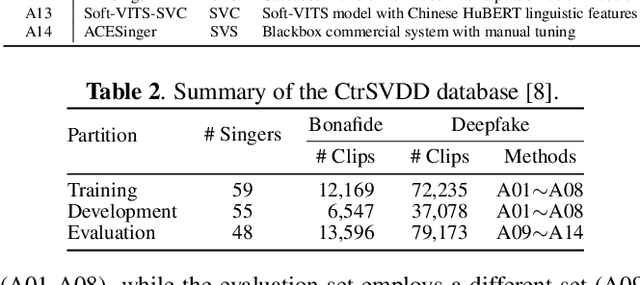
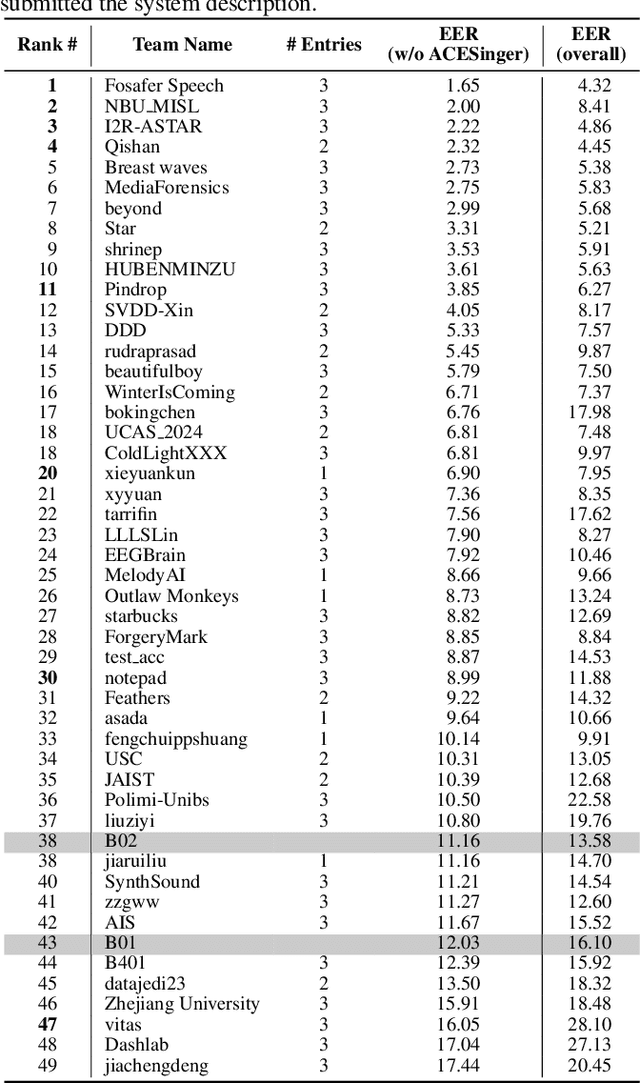
With the advancements in singing voice generation and the growing presence of AI singers on media platforms, the inaugural Singing Voice Deepfake Detection (SVDD) Challenge aims to advance research in identifying AI-generated singing voices from authentic singers. This challenge features two tracks: a controlled setting track (CtrSVDD) and an in-the-wild scenario track (WildSVDD). The CtrSVDD track utilizes publicly available singing vocal data to generate deepfakes using state-of-the-art singing voice synthesis and conversion systems. Meanwhile, the WildSVDD track expands upon the existing SingFake dataset, which includes data sourced from popular user-generated content websites. For the CtrSVDD track, we received submissions from 47 teams, with 37 surpassing our baselines and the top team achieving a 1.65% equal error rate. For the WildSVDD track, we benchmarked the baselines. This paper reviews these results, discusses key findings, and outlines future directions for SVDD research.
LibriTTS-P: A Corpus with Speaking Style and Speaker Identity Prompts for Text-to-Speech and Style Captioning
Jun 12, 2024



We introduce LibriTTS-P, a new corpus based on LibriTTS-R that includes utterance-level descriptions (i.e., prompts) of speaking style and speaker-level prompts of speaker characteristics. We employ a hybrid approach to construct prompt annotations: (1) manual annotations that capture human perceptions of speaker characteristics and (2) synthetic annotations on speaking style. Compared to existing English prompt datasets, our corpus provides more diverse prompt annotations for all speakers of LibriTTS-R. Experimental results for prompt-based controllable TTS demonstrate that the TTS model trained with LibriTTS-P achieves higher naturalness than the model using the conventional dataset. Furthermore, the results for style captioning tasks show that the model utilizing LibriTTS-P generates 2.5 times more accurate words than the model using a conventional dataset. Our corpus, LibriTTS-P, is available at https://github.com/line/LibriTTS-P.
Audio-conditioned phonemic and prosodic annotation for building text-to-speech models from unlabeled speech data
Jun 12, 2024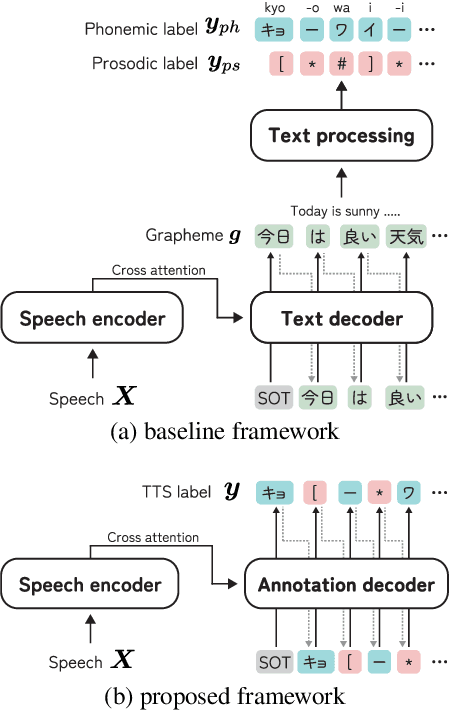
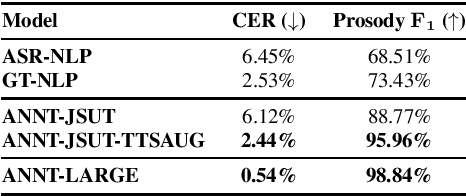
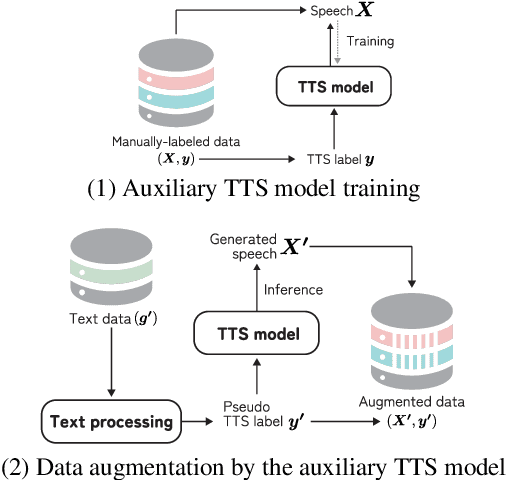

This paper proposes an audio-conditioned phonemic and prosodic annotation model for building text-to-speech (TTS) datasets from unlabeled speech samples. For creating a TTS dataset that consists of label-speech paired data, the proposed annotation model leverages an automatic speech recognition (ASR) model to obtain phonemic and prosodic labels from unlabeled speech samples. By fine-tuning a large-scale pre-trained ASR model, we can construct the annotation model using a limited amount of label-speech paired data within an existing TTS dataset. To alleviate the shortage of label-speech paired data for training the annotation model, we generate pseudo label-speech paired data using text-only corpora and an auxiliary TTS model. This TTS model is also trained with the existing TTS dataset. Experimental results show that the TTS model trained with the dataset created by the proposed annotation method can synthesize speech as naturally as the one trained with a fully-labeled dataset.
SRC4VC: Smartphone-Recorded Corpus for Voice Conversion Benchmark
Jun 11, 2024



We present SRC4VC, a new corpus containing 11 hours of speech recorded on smartphones by 100 Japanese speakers. Although high-quality multi-speaker corpora can advance voice conversion (VC) technologies, they are not always suitable for testing VC when low-quality speech recording is given as the input. To this end, we first asked 100 crowdworkers to record their voice samples using smartphones. Then, we annotated the recorded samples with speaker-wise recording-quality scores and utterance-wise perceived emotion labels. We also benchmark SRC4VC on any-to-any VC, in which we trained a multi-speaker VC model on high-quality speech and used the SRC4VC speakers' voice samples as the source in VC. The results show that the recording quality mismatch between the training and evaluation data significantly degrades the VC performance, which can be improved by applying speech enhancement to the low-quality source speech samples.
Noise-Robust Voice Conversion by Conditional Denoising Training Using Latent Variables of Recording Quality and Environment
Jun 11, 2024



We propose noise-robust voice conversion (VC) which takes into account the recording quality and environment of noisy source speech. Conventional denoising training improves the noise robustness of a VC model by learning noisy-to-clean VC process. However, the naturalness of the converted speech is limited when the noise of the source speech is unseen during the training. To this end, our proposed training conditions a VC model on two latent variables representing the recording quality and environment of the source speech. These latent variables are derived from deep neural networks pre-trained on recording quality assessment and acoustic scene classification and calculated in an utterance-wise or frame-wise manner. As a result, the trained VC model can explicitly learn information about speech degradation during the training. Objective and subjective evaluations show that our training improves the quality of the converted speech compared to the conventional training.
CtrSVDD: A Benchmark Dataset and Baseline Analysis for Controlled Singing Voice Deepfake Detection
Jun 04, 2024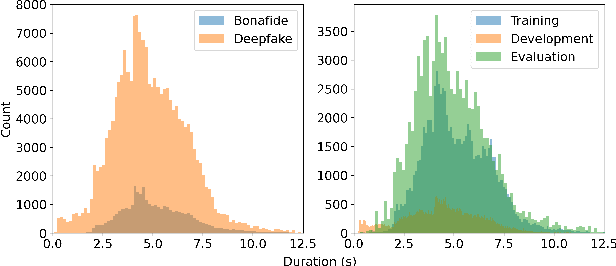
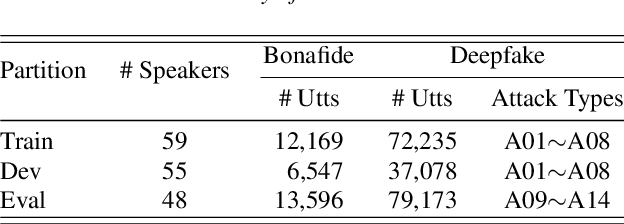
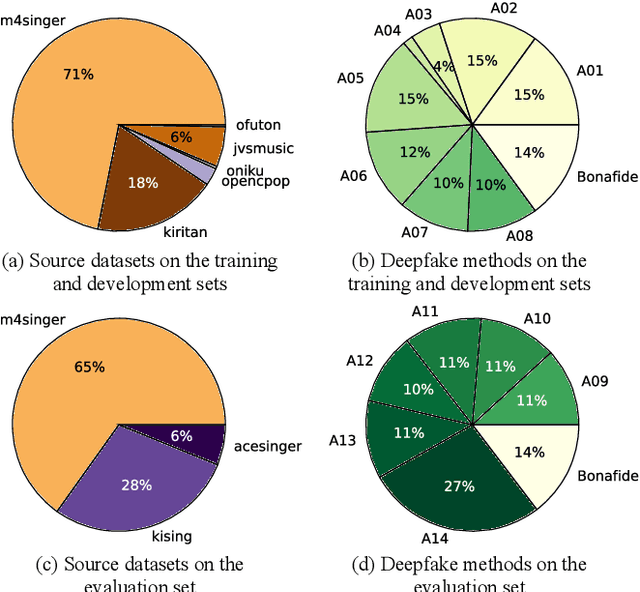

Recent singing voice synthesis and conversion advancements necessitate robust singing voice deepfake detection (SVDD) models. Current SVDD datasets face challenges due to limited controllability, diversity in deepfake methods, and licensing restrictions. Addressing these gaps, we introduce CtrSVDD, a large-scale, diverse collection of bonafide and deepfake singing vocals. These vocals are synthesized using state-of-the-art methods from publicly accessible singing voice datasets. CtrSVDD includes 47.64 hours of bonafide and 260.34 hours of deepfake singing vocals, spanning 14 deepfake methods and involving 164 singer identities. We also present a baseline system with flexible front-end features, evaluated against a structured train/dev/eval split. The experiments show the importance of feature selection and highlight a need for generalization towards deepfake methods that deviate further from training distribution. The CtrSVDD dataset and baselines are publicly accessible.