 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneses: Unified Generative Speech Enhancement and Separation
Jan 26, 2026Real-world audio recordings often contain multiple speakers and various degradations, which limit both the quantity and quality of speech data available for building state-of-the-art speech processing models. Although end-to-end approaches that concatenate speech enhancement (SE) and speech separation (SS) to obtain a clean speech signal for each speaker are promising, conventional SE-SS methods suffer from complex degradations beyond additive noise. To this end, we propose \textbf{Geneses}, a generative framework to achieve unified, high-quality SE--SS. Our Geneses leverages latent flow matching to estimate each speaker's clean speech features using multi-modal diffusion Transformer conditioned on self-supervised learning representation from noisy mixture. We conduct experimental evaluation using two-speaker mixtures from LibriTTS-R under two conditions: additive-noise-only and complex degradations. The results demonstrate that Geneses significantly outperforms a conventional mask-based SE--SS method across various objective metrics with high robustness against complex degradations. Audio samples are available in our demo page.
Emotional Text-To-Speech Based on Mutual-Information-Guided Emotion-Timbre Disentanglement
Oct 02, 2025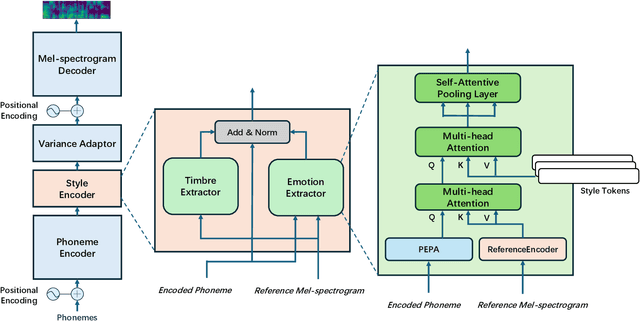
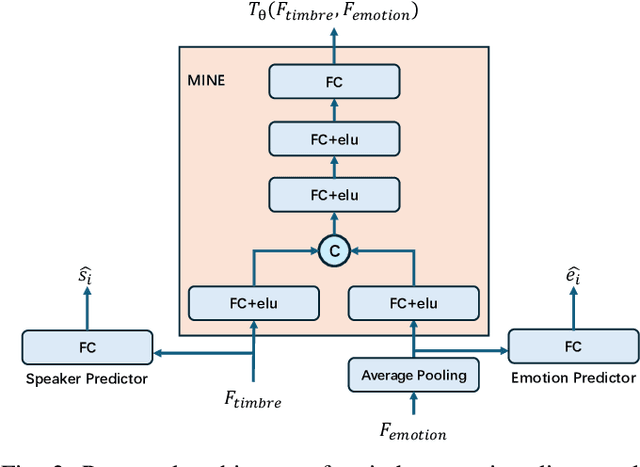
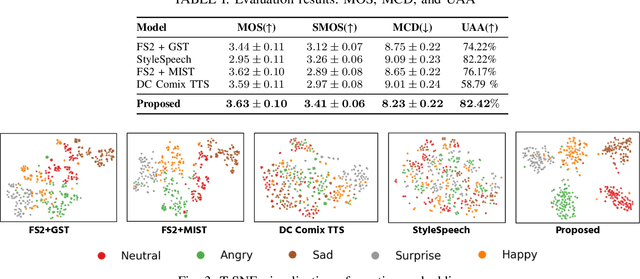
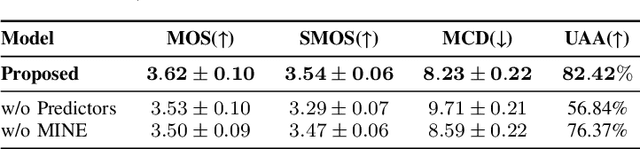
Current emotional Text-To-Speech (TTS) and style transfer methods rely on reference encoders to control global style or emotion vectors, but do not capture nuanced acoustic details of the reference speech. To this end, we propose a novel emotional TTS method that enables fine-grained phoneme-level emotion embedding prediction while disentangling intrinsic attributes of the reference speech. The proposed method employs a style disentanglement method to guide two feature extractors, reducing mutual information between timbre and emotion features, and effectively separating distinct style components from the reference speech. Experimental results demonstrate that our method outperforms baseline TTS systems in generating natural and emotionally rich speech. This work highlights the potential of disentangled and fine-grained representations in advancing the quality and flexibility of emotional TTS systems.
Shallow Flow Matching for Coarse-to-Fine Text-to-Speech Synthesis
May 18, 2025We propose a shallow flow matching (SFM) mechanism to enhance flow matching (FM)-based text-to-speech (TTS) models within a coarse-to-fine generation paradigm. SFM constructs intermediate states along the FM paths using coarse output representations. During training, we introduce an orthogonal projection method to adaptively determine the temporal position of these states, and apply a principled construction strategy based on a single-segment piecewise flow. The SFM inference starts from the intermediate state rather than pure noise and focuses computation on the latter stages of the FM paths. We integrate SFM into multiple TTS models with a lightweight SFM head. Experiments show that SFM consistently improves the naturalness of synthesized speech in both objective and subjective evaluations, while significantly reducing inference when using adaptive-step ODE solvers. Demo and codes are available at https://ydqmkkx.github.io/SFMDemo/.
Causal Speech Enhancement with Predicting Semantics based on Quantized Self-supervised Learning Features
Dec 26, 2024Real-time speech enhancement (SE) is essential to online speech communication. Causal SE models use only the previous context while predicting future information, such as phoneme continuation, may help performing causal SE. The phonetic information is often represented by quantizing latent features of self-supervised learning (SSL) models. This work is the first to incorporate SSL features with causality into an SE model. The causal SSL features are encoded and combined with spectrogram features using feature-wise linear modulation to estimate a mask for enhancing the noisy input speech. Simultaneously, we quantize the causal SSL features using vector quantization to represent phonetic characteristics as semantic tokens. The model not only encodes SSL features but also predicts the future semantic tokens in multi-task learning (MTL). The experimental results using VoiceBank + DEMAND dataset show that our proposed method achieves 2.88 in PESQ, especially with semantic prediction MTL, in which we confirm that the semantic prediction played an important role in causal SE.
DNN-based ensemble singing voice synthesis with interactions between singers
Sep 16, 2024



We propose a singing voice synthesis (SVS) method for a more unified ensemble singing voice by modeling interactions between singers. Most existing SVS methods aim to synthesize a solo voice, and do not consider interactions between singers, i.e., adjusting one's own voice to the others' voices. Since the production of ensemble voices from solo singing voices ignores the interactions, it can degrade the unity of the vocal ensemble. Therefore, we propose a SVS that reproduces the interactions. It is based on an architecture that uses musical scores of multiple voice parts, and loss functions that simulate the interactions' effect to acoustic features. Experimental results show that our methods improve the unity of the vocal ensemble.
The T05 System for The VoiceMOS Challenge 2024: Transfer Learning from Deep Image Classifier to Naturalness MOS Prediction of High-Quality Synthetic Speech
Sep 14, 2024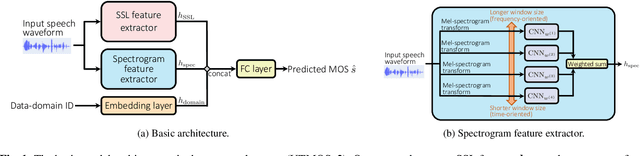
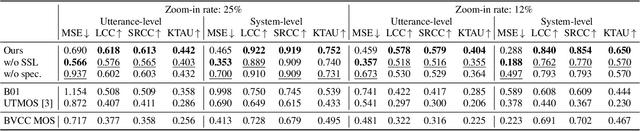

We present our system (denoted as T05) for the VoiceMOS Challenge (VMC) 2024. Our system was designed for the VMC 2024 Track 1, which focused on the accurate prediction of naturalness mean opinion score (MOS) for high-quality synthetic speech. In addition to a pretrained self-supervised learning (SSL)-based speech feature extractor, our system incorporates a pretrained image feature extractor to capture the difference of synthetic speech observed in speech spectrograms. We first separately train two MOS predictors that use either of an SSL-based or spectrogram-based feature. Then, we fine-tune the two predictors for better MOS prediction using the fusion of two extracted features. In the VMC 2024 Track 1, our T05 system achieved first place in 7 out of 16 evaluation metrics and second place in the remaining 9 metrics, with a significant difference compared to those ranked third and below. We also report the results of our ablation study to investigate essential factors of our system.
Cross-Dialect Text-To-Speech in Pitch-Accent Language Incorporating Multi-Dialect Phoneme-Level BERT
Sep 11, 2024We explore cross-dialect text-to-speech (CD-TTS), a task to synthesize learned speakers' voices in non-native dialects, especially in pitch-accent languages. CD-TTS is important for developing voice agents that naturally communicate with people across regions. We present a novel TTS model comprising three sub-modules to perform competitively at this task. We first train a backbone TTS model to synthesize dialect speech from a text conditioned on phoneme-level accent latent variables (ALVs) extracted from speech by a reference encoder. Then, we train an ALV predictor to predict ALVs tailored to a target dialect from input text leveraging our novel multi-dialect phoneme-level BERT. We conduct multi-dialect TTS experiments and evaluate the effectiveness of our model by comparing it with a baseline derived from conventional dialect TTS methods. The results show that our model improves the dialectal naturalness of synthetic speech in CD-TTS.
BigCodec: Pushing the Limits of Low-Bitrate Neural Speech Codec
Sep 09, 2024



We present BigCodec, a low-bitrate neural speech codec. While recent neural speech codecs have shown impressive progress, their performance significantly deteriorates at low bitrates (around 1 kbps). Although a low bitrate inherently restricts performance, other factors, such as model capacity, also hinder further improvements. To address this problem, we scale up the model size to 159M parameters that is more than 10 times larger than popular codecs with about 10M parameters. Besides, we integrate sequential models into traditional convolutional architectures to better capture temporal dependency and adopt low-dimensional vector quantization to ensure a high code utilization. Comprehensive objective and subjective evaluations show that BigCodec, with a bitrate of 1.04 kbps, significantly outperforms several existing low-bitrate codecs. Furthermore, BigCodec achieves objective performance comparable to popular codecs operating at 4-6 times higher bitrates, and even delivers better subjective perceptual quality than the ground truth.
SaSLaW: Dialogue Speech Corpus with Audio-visual Egocentric Information Toward Environment-adaptive Dialogue Speech Synthesis
Aug 13, 2024This paper presents SaSLaW, a spontaneous dialogue speech corpus containing synchronous recordings of what speakers speak, listen to, and watch. Humans consider the diverse environmental factors and then control the features of their utterances in face-to-face voice communications. Spoken dialogue systems capable of this adaptation to these audio environments enable natural and seamless communications. SaSLaW was developed to model human-speech adjustment for audio environments via first-person audio-visual perceptions in spontaneous dialogues. We propose the construction methodology of SaSLaW and display the analysis result of the corpus. We additionally conducted an experiment to develop text-to-speech models using SaSLaW and evaluate their performance of adaptations to audio environments. The results indicate that models incorporating hearing-audio data output more plausible speech tailored to diverse audio environments than the vanilla text-to-speech model.
J-CHAT: Japanese Large-scale Spoken Dialogue Corpus for Spoken Dialogue Language Modeling
Jul 22, 2024



Spoken dialogue plays a crucial role in human-AI interactions, necessitating dialogue-oriented spoken language models (SLMs). To develop versatile SLMs, large-scale and diverse speech datasets are essential. Additionally, to ensure hiqh-quality speech generation, the data must be spontaneous like in-wild data and must be acoustically clean with noise removed. Despite the critical need, no open-source corpus meeting all these criteria has been available. This study addresses this gap by constructing and releasing a large-scale spoken dialogue corpus, named Japanese Corpus for Human-AI Talks (J-CHAT), which is publicly accessible. Furthermore, this paper presents a language-independent method for corpus construction and describes experiments on dialogue generation using SLMs trained on J-CHAT. Experimental results indicate that the collected data from multiple domains by our method improve the naturalness and meaningfulness of dialogue generation.