 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Token Spaces under Generator Shift in AI-Generated Music Detection
Jun 07, 2026AI-generated music detectors can appear robust on standard benchmark splits, yet their deployments require transfer to generator sources absent during training. We study this problem with source-restricted evaluation on \textsc{MoM-open}, an open reconstruction of MoM-CLAM that replaces the non-redistributable real corpus with FMA and MTG-Jamendo while preserving the fake-generator protocol. To isolate the role of representation, we introduce \textsc{CoMoE}, a compact fixed classifier for comparing heterogeneous audio token spaces while keeping the downstream architecture and training recipe unchanged. Experiments show that standard and real-source-restricted splits are nearly saturated, whereas fake-source restriction exposes large differences between token spaces: X-Codec tokens are strongest when training on Udio alone, while MERT-derived tokens are stronger when training on Suno-v3.5 alone. These results suggest that codec-style discrete token spaces should be treated as a primary experimental axis under generator shift in AI-generated music detection. Our code and data are available at https://github.com/MAAP-LAB/CoMoE.
Do speech foundation models perceive speaker similarity as humans do?
Jun 04, 2026This study presents a comparative analysis between the speaker embeddings of speech foundation models and human subjective perception of speaker similarity. Human listeners have the ability to judge speaker similarity on a continuous scale discerning how similar two voices are. In contrast, speech foundation models embed speaker characteristics into numerical representation. However, a question remains: does the numerical distance between speaker embeddings in these models truly align with the similarity perceived by humans? To address this, we conduct a comprehensive investigation using more than 40 models to compare model-derived distances with human-perceived similarity scores. Furthermore, we identify which factors in model configuration contribute most to a speaker embedding that mirrors human perception. Our findings provide insights for the development of more perceptually grounded speech foundation models.
Kinetic-Optimal Scheduling with Moment Correction for Metric-Induced Discrete Flow Matching in Zero-Shot Text-to-Speech
May 10, 2026Metric-induced discrete flow matching (MI-DFM) exploits token-latent geometry for discrete generation, but its practical use is limited by two issues: heuristic schedulers requiring hyperparameter search, and finite-step path-tracking error from its first-order continuous-time Markov chain (CTMC) solver. We address both issues. First, we derive a kinetic-optimal scheduler for prescribed scalar-parameterized probability paths, and instantiate it for MI-DFM as a training-free numerical schedule that traverses the path at constant Fisher-Rao speed. Second, we introduce a finite-step moment correction that adjusts the jump probability while preserving the CTMC jump destination distribution. We validate the resulting method, GibbsTTS, on codec-based zero-shot text-to-speech (TTS). Under controlled comparisons with a unified architecture and large-scale dataset, GibbsTTS achieves the best objective naturalness and is preferred in subjective evaluations over masked discrete generative baselines. Additionally, in comparison with the evaluated state-of-the-art TTS systems, GibbsTTS shows strong speaker similarity, achieving the highest similarity on three of four test sets and ranking second on the fourth. Project page: https://ydqmkkx.github.io/GibbsTTSProject
DialogueSidon: Recovering Full-Duplex Dialogue Tracks from In-the-Wild Dialogue Audio
Apr 13, 2026Full-duplex dialogue audio, in which each speaker is recorded on a separate track, is an important resource for spoken dialogue research, but is difficult to collect at scale. Most in-the-wild two-speaker dialogue is available only as degraded monaural mixtures, making it unsuitable for systems requiring clean speaker-wise signals. We propose DialogueSidon, a model for joint restoration and separation of degraded monaural two-speaker dialogue audio. DialogueSidon combines a variational autoencoder (VAE) operates on the speech self-supervised learning (SSL) model feature, which compresses SSL model features into a compact latent space, with a diffusion-based latent predictor that recovers speaker-wise latent representations from the degraded mixture. Experiments on English, multilingual, and in-the-wild dialogue datasets show that DialogueSidon substantially improves intelligibility and separation quality over a baseline, while also achieving much faster inference.
DecompGrind: A Decomposition Framework for Robotic Grinding via Cutting-Surface Planning and Contact-Force Adaptation
Mar 24, 2026Robotic grinding is widely used for shaping workpieces in manufacturing, but it remains difficult to automate this process efficiently. In particular, efficiently grinding workpieces of different shapes and material hardness is challenging because removal resistance varies with local contact conditions. Moreover, it is difficult to achieve accurate estimation of removal resistance and analytical modeling of shape transition, and learning-based approaches often require large amounts of training data to cover diverse processing conditions. To address these challenges, we decompose robotic grinding into two components: removal-shape planning and contact-force adaptation. Based on this formulation, we propose DecompGrind, a framework that combines Global Cutting-Surface Planning (GCSP) and Local Contact-Force Adaptation (LCFA). GCSP determines removal shapes through geometric analysis of the current and target shapes without learning, while LCFA learns a contact-force adaptation policy using bilateral control-based imitation learning during the grinding of each removal shape. This decomposition restricts learning to local contact-force adaptation, allowing the policy to be learned from a small number of demonstrations, while handling global shape transition geometrically. Experiments using a robotic grinding system and 3D-printed workpieces demonstrate efficient robotic grinding of workpieces having different shapes and material hardness while maintaining safe levels of contact force.
Reference-Free Image Quality Assessment for Virtual Try-On via Human Feedback
Mar 13, 2026Given a person image and a garment image, image-based Virtual Try-ON (VTON) synthesizes a try-on image of the person wearing the target garment. As VTON systems become increasingly important in practical applications such as fashion e-commerce, reliable evaluation of their outputs has emerged as a critical challenge. In real-world scenarios, ground-truth images of the same person wearing the target garment are typically unavailable, making reference-based evaluation impractical. Moreover, widely used distribution-level metrics such as Fréchet Inception Distance and Kernel Inception Distance measure dataset-level similarity and fail to reflect the perceptual quality of individual generated images. To address these limitations, we propose Image Quality Assessment for Virtual Try-On (VTON-IQA), a reference-free framework for human-aligned, image-level quality assessment without requiring ground-truth images. To model human perceptual judgments, we construct VTON-QBench, a large-scale human-annotated benchmark comprising 62,688 try-on images generated by 14 representative VTON models and 431,800 quality annotations collected from 13,838 qualified annotators. To the best of our knowledge, this is the largest dataset to date for human subjective evaluation in virtual try-on. Evaluating virtual try-on quality requires verifying both garment fidelity and the preservation of person-specific details. To explicitly model such interactions, we introduce an Interleaved Cross-Attention module that extends standard transformer blocks by inserting a cross-attention layer between self-attention and MLP in the latter blocks. Extensive experiments show that VTON-IQA achieves reliable human-aligned image-level quality prediction. Moreover, we conduct a comprehensive benchmark evaluation of 14 representative VTON models using VTON-IQA.
Real-Time Generation of Game Video Commentary with Multimodal LLMs: Pause-Aware Decoding Approaches
Mar 03, 2026Real-time video commentary generation provides textual descriptions of ongoing events in videos. It supports accessibility and engagement in domains such as sports, esports, and livestreaming. Commentary generation involves two essential decisions: what to say and when to say it. While recent prompting-based approaches using multimodal large language models (MLLMs) have shown strong performance in content generation, they largely ignore the timing aspect. We investigate whether in-context prompting alone can support real-time commentary generation that is both semantically relevant and well-timed. We propose two prompting-based decoding strategies: 1) a fixed-interval approach, and 2) a novel dynamic interval-based decoding approach that adjusts the next prediction timing based on the estimated duration of the previous utterance. Both methods enable pause-aware generation without any fine-tuning. Experiments on Japanese and English datasets of racing and fighting games show that the dynamic interval-based decoding can generate commentary more closely aligned with human utterance timing and content using prompting alone. We release a multilingual benchmark dataset, trained models, and implementations to support future research on real-time video commentary generation.
Geneses: Unified Generative Speech Enhancement and Separation
Jan 26, 2026Real-world audio recordings often contain multiple speakers and various degradations, which limit both the quantity and quality of speech data available for building state-of-the-art speech processing models. Although end-to-end approaches that concatenate speech enhancement (SE) and speech separation (SS) to obtain a clean speech signal for each speaker are promising, conventional SE-SS methods suffer from complex degradations beyond additive noise. To this end, we propose \textbf{Geneses}, a generative framework to achieve unified, high-quality SE--SS. Our Geneses leverages latent flow matching to estimate each speaker's clean speech features using multi-modal diffusion Transformer conditioned on self-supervised learning representation from noisy mixture. We conduct experimental evaluation using two-speaker mixtures from LibriTTS-R under two conditions: additive-noise-only and complex degradations. The results demonstrate that Geneses significantly outperforms a conventional mask-based SE--SS method across various objective metrics with high robustness against complex degradations. Audio samples are available in our demo page.
Emotional Text-To-Speech Based on Mutual-Information-Guided Emotion-Timbre Disentanglement
Oct 02, 2025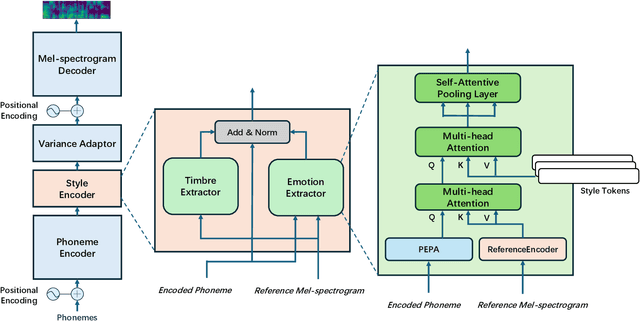
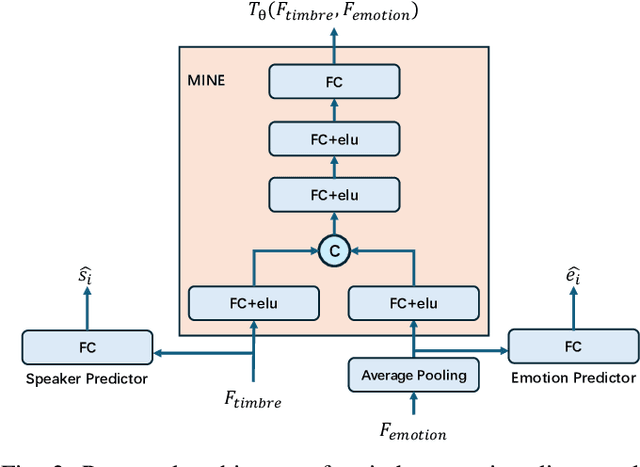
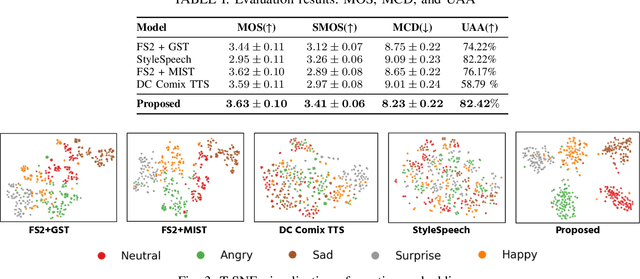
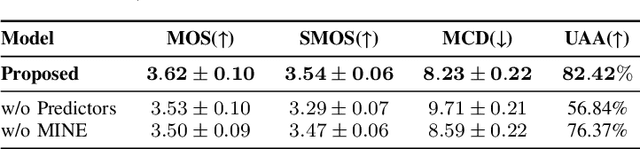
Current emotional Text-To-Speech (TTS) and style transfer methods rely on reference encoders to control global style or emotion vectors, but do not capture nuanced acoustic details of the reference speech. To this end, we propose a novel emotional TTS method that enables fine-grained phoneme-level emotion embedding prediction while disentangling intrinsic attributes of the reference speech. The proposed method employs a style disentanglement method to guide two feature extractors, reducing mutual information between timbre and emotion features, and effectively separating distinct style components from the reference speech. Experimental results demonstrate that our method outperforms baseline TTS systems in generating natural and emotionally rich speech. This work highlights the potential of disentangled and fine-grained representations in advancing the quality and flexibility of emotional TTS systems.
Static Word Embeddings for Sentence Semantic Representation
Jun 05, 2025

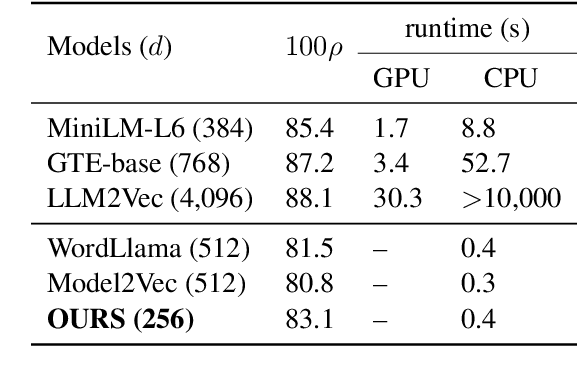

We propose new static word embeddings optimised for sentence semantic representation. We first extract word embeddings from a pre-trained Sentence Transformer, and improve them with sentence-level principal component analysis, followed by either knowledge distillation or contrastive learning. During inference, we represent sentences by simply averaging word embeddings, which requires little computational cost. We evaluate models on both monolingual and cross-lingual tasks and show that our model substantially outperforms existing static models on sentence semantic tasks, and even rivals a basic Sentence Transformer model (SimCSE) on some data sets. Lastly, we perform a variety of analyses and show that our method successfully removes word embedding components that are irrelevant to sentence semantics, and adjusts the vector norms based on the influence of words on sentence semantics.