 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColor-based Emotion Representation for Speech Emotion Recognition
Feb 18, 2026Speech emotion recognition (SER) has traditionally relied on categorical or dimensional labels. However, this technique is limited in representing both the diversity and interpretability of emotions. To overcome this limitation, we focus on color attributes, such as hue, saturation, and value, to represent emotions as continuous and interpretable scores. We annotated an emotional speech corpus with color attributes via crowdsourcing and analyzed them. Moreover, we built regression models for color attributes in SER using machine learning and deep learning, and explored the multitask learning of color attribute regression and emotion classification. As a result, we demonstrated the relationship between color attributes and emotions in speech, and successfully developed color attribute regression models for SER. We also showed that multitask learning improved the performance of each task.
Construction and Analysis of Impression Caption Dataset for Environmental Sounds
Oct 20, 2024Some datasets with the described content and order of occurrence of sounds have been released for conversion between environmental sound and text. However, there are very few texts that include information on the impressions humans feel, such as "sharp" and "gorgeous," when they hear environmental sounds. In this study, we constructed a dataset with impression captions for environmental sounds that describe the impressions humans have when hearing these sounds. We used ChatGPT to generate impression captions and selected the most appropriate captions for sound by humans. Our dataset consists of 3,600 impression captions for environmental sounds. To evaluate the appropriateness of impression captions for environmental sounds, we conducted subjective and objective evaluations. From our evaluation results, we indicate that appropriate impression captions for environmental sounds can be generated.
RISC: A Corpus for Shout Type Classification and Shout Intensity Prediction
Jun 07, 2023The detection of shouted speech is crucial in audio surveillance and monitoring. Although it is desirable for a security system to be able to identify emergencies, existing corpora provide only a binary label (i.e., shouted or normal) for each speech sample, making it difficult to predict the shout intensity. Furthermore, most corpora comprise only utterances typical of hazardous situations, meaning that classifiers cannot learn to discriminate such utterances from shouts typical of less hazardous situations, such as cheers. Thus, this paper presents a novel research source, the RItsumeikan Shout Corpus (RISC), which contains wide variety types of shouted speech samples collected in recording experiments. Each shouted speech sample in RISC has a shout type and is also assigned shout intensity ratings via a crowdsourcing service. We also present a comprehensive performance comparison among deep learning approaches for speech type classification tasks and a shout intensity prediction task. The results show that feature learning based on the spectral and cepstral domains achieves high performance, no matter which network architecture is used. The results also demonstrate that shout type classification and intensity prediction are still challenging tasks, and RISC is expected to contribute to further development in this research area.
Environmental sound conversion from vocal imitations and sound event labels
Apr 29, 2023



One way of expressing an environmental sound is using vocal imitations, which involve the process of replicating or mimicking the rhythms and pitches of sounds by voice. We can effectively express the features of environmental sounds, such as rhythms and pitches, using vocal imitations, which cannot be expressed by conventional input information, such as sound event labels, images, and texts, in an environmental sound synthesis model. Therefore, using vocal imitations as input for environmental sound synthesis will enable us to control the pitches and rhythms of sounds and generate diverse sounds. In this paper, we thus propose a framework for environmental sound conversion from vocal imitations to generate diverse sounds. We also propose a method of environmental sound synthesis from vocal imitations and sound event labels. Using sound event labels is expected to control the sound event class of the synthesized sound, which cannot be controlled by only vocal imitations. Our objective and subjective experimental results show that vocal imitations effectively control the pitches and rhythms of sounds and generate diverse sounds.
How Should We Evaluate Synthesized Environmental Sounds
Aug 16, 2022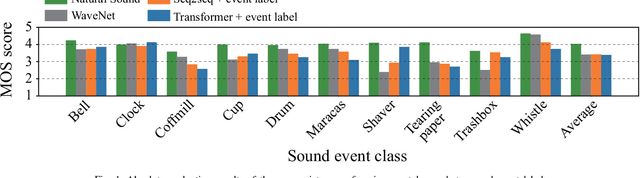
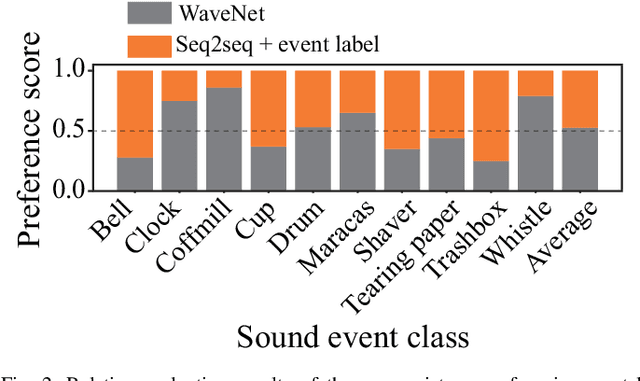
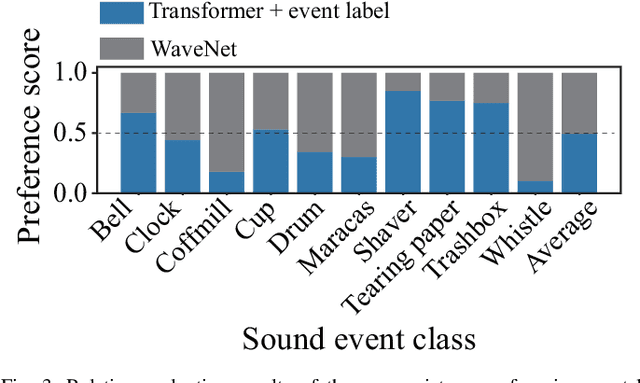
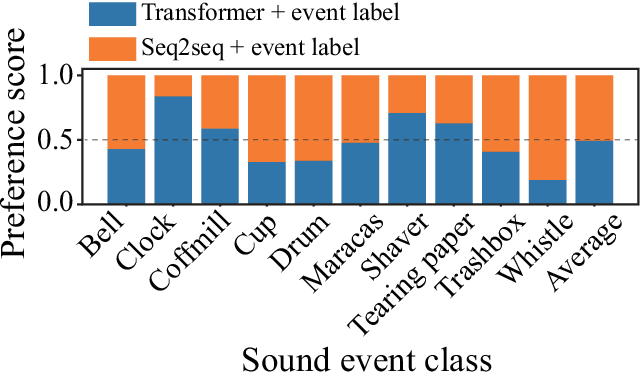
Although several methods of environmental sound synthesis have been proposed, there has been no discussion on how synthesized environmental sounds should be evaluated. Only either subjective or objective evaluations have been conducted in conventional evaluations, and it is not clear what type of evaluation should be carried out. In this paper, we investigate how to evaluate synthesized environmental sounds. We also propose a subjective evaluation methodology to evaluate whether the synthesized sound appropriately represents the information input to the environmental sound synthesis system. In our experiments, we compare the proposed and conventional evaluation methods and show that the results of subjective evaluations tended to differ from those of objective evaluations. From these results, we conclude that it is necessary to conduct not only objective evaluation but also subjective evaluation.
Onoma-to-wave: Environmental sound synthesis from onomatopoeic words
Feb 11, 2021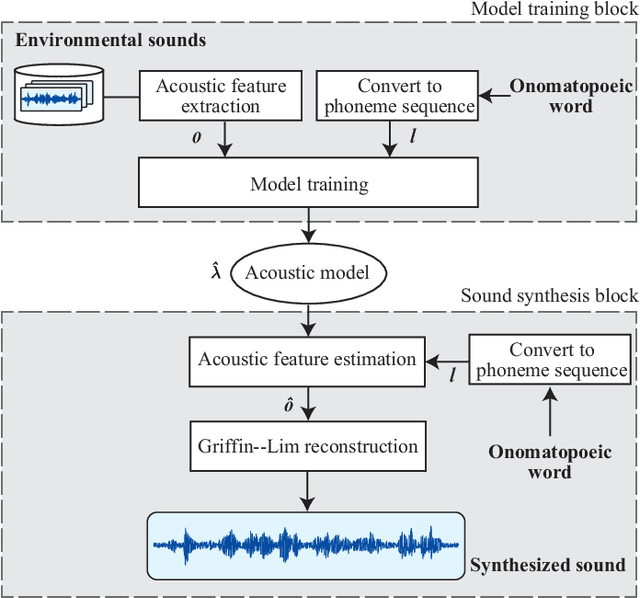
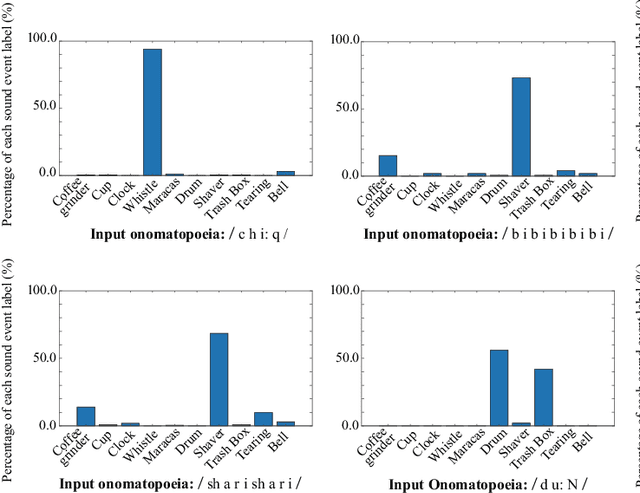
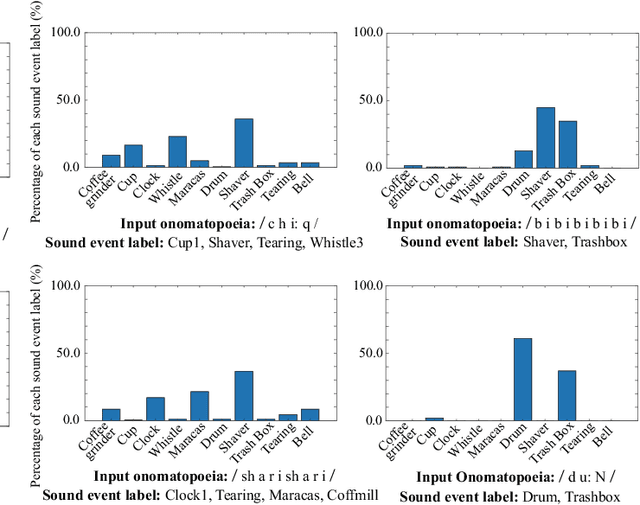
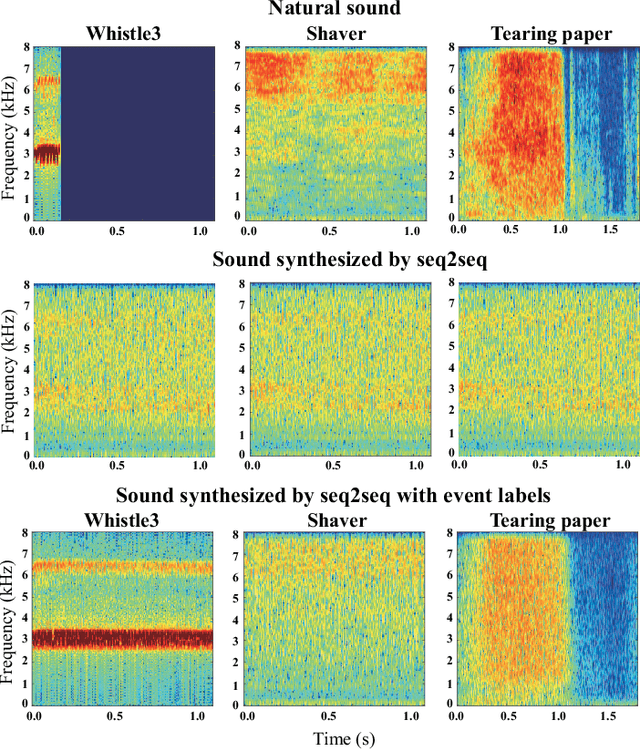
In this paper, we propose a new framework for environmental sound synthesis using onomatopoeic words and sound event labels. The conventional method of environmental sound synthesis, in which only sound event labels are used, cannot finely control the time-frequency structural features of synthesized sounds, such as sound duration, timbre, and pitch. There are various ways to express environmental sound other than sound event labels, such as the use of onomatopoeic words. An onomatopoeic word, which is a character sequence for phonetically imitating a sound, has been shown to be effective for describing the phonetic feature of sounds. We believe that environmental sound synthesis using onomatopoeic words will enable us to control the fine time-frequency structural features of synthesized sounds, such as sound duration, timbre, and pitch. In this paper, we thus propose environmental sound synthesis from onomatopoeic words on the basis of a sequence-to-sequence framework. To convert onomatopoeic words to environmental sound, we use a sequence-to-sequence framework. We also propose a method of environmental sound synthesis using onomatopoeic words and sound event labels to control the fine time-frequency structure and frequency property of synthesized sounds. Our subjective experiments show that the proposed method achieves the same level of sound quality as the conventional method using WaveNet. Moreover, our methods are better than the conventional method in terms of the expressiveness of synthesized sounds to onomatopoeic words.