 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSound Scene Synthesis at the DCASE 2024 Challenge
Jan 15, 2025This paper presents Task 7 at the DCASE 2024 Challenge: sound scene synthesis. Recent advances in sound synthesis and generative models have enabled the creation of realistic and diverse audio content. We introduce a standardized evaluation framework for comparing different sound scene synthesis systems, incorporating both objective and subjective metrics. The challenge attracted four submissions, which are evaluated using the Fr\'echet Audio Distance (FAD) and human perceptual ratings. Our analysis reveals significant insights into the current capabilities and limitations of sound scene synthesis systems, while also highlighting areas for future improvement in this rapidly evolving field.
Challenge on Sound Scene Synthesis: Evaluating Text-to-Audio Generation
Oct 23, 2024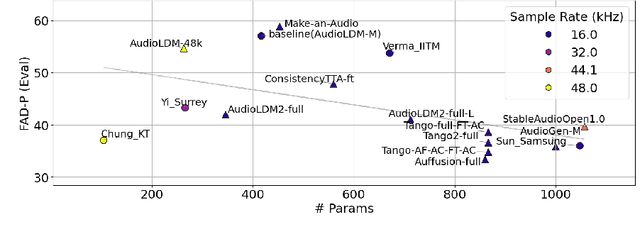
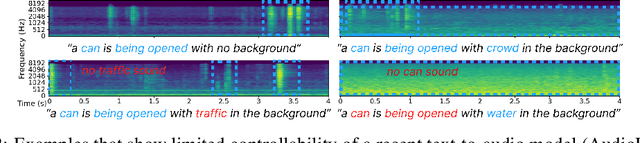
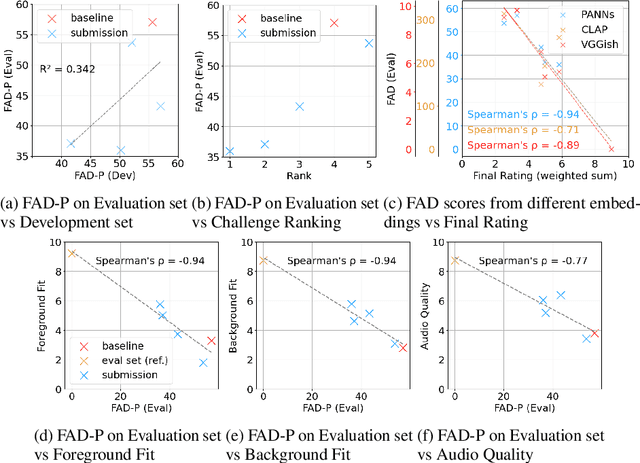
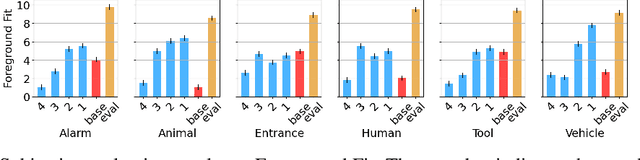
Despite significant advancements in neural text-to-audio generation, challenges persist in controllability and evaluation. This paper addresses these issues through the Sound Scene Synthesis challenge held as part of the Detection and Classification of Acoustic Scenes and Events 2024. We present an evaluation protocol combining objective metric, namely Fr\'echet Audio Distance, with perceptual assessments, utilizing a structured prompt format to enable diverse captions and effective evaluation. Our analysis reveals varying performance across sound categories and model architectures, with larger models generally excelling but innovative lightweight approaches also showing promise. The strong correlation between objective metrics and human ratings validates our evaluation approach. We discuss outcomes in terms of audio quality, controllability, and architectural considerations for text-to-audio synthesizers, providing direction for future research.
Construction and Analysis of Impression Caption Dataset for Environmental Sounds
Oct 20, 2024Some datasets with the described content and order of occurrence of sounds have been released for conversion between environmental sound and text. However, there are very few texts that include information on the impressions humans feel, such as "sharp" and "gorgeous," when they hear environmental sounds. In this study, we constructed a dataset with impression captions for environmental sounds that describe the impressions humans have when hearing these sounds. We used ChatGPT to generate impression captions and selected the most appropriate captions for sound by humans. Our dataset consists of 3,600 impression captions for environmental sounds. To evaluate the appropriateness of impression captions for environmental sounds, we conducted subjective and objective evaluations. From our evaluation results, we indicate that appropriate impression captions for environmental sounds can be generated.
Correlation of Fréchet Audio Distance With Human Perception of Environmental Audio Is Embedding Dependant
Mar 26, 2024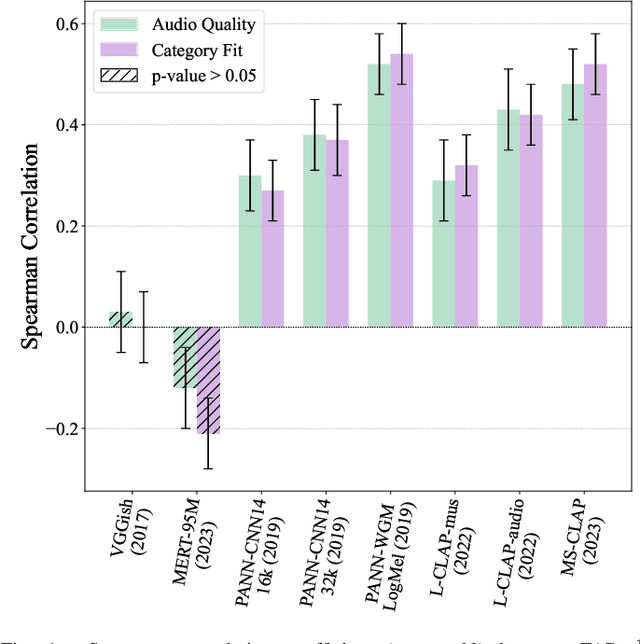
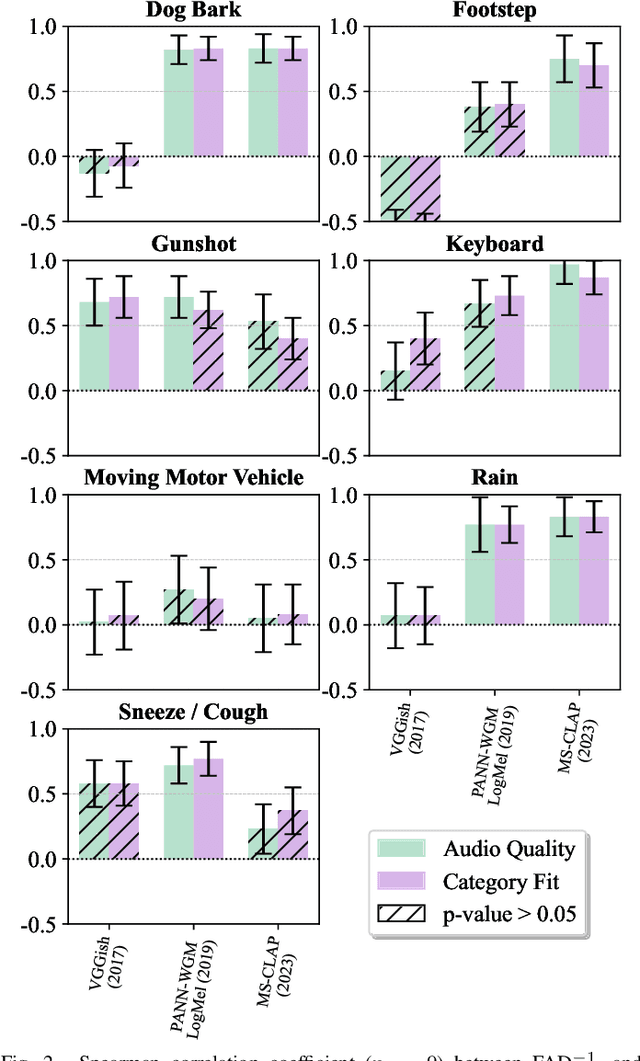
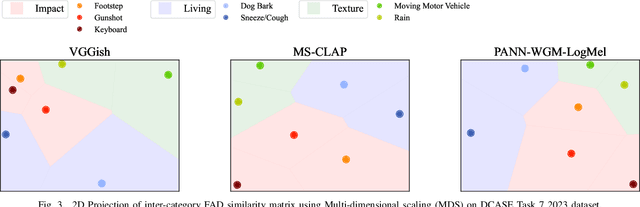
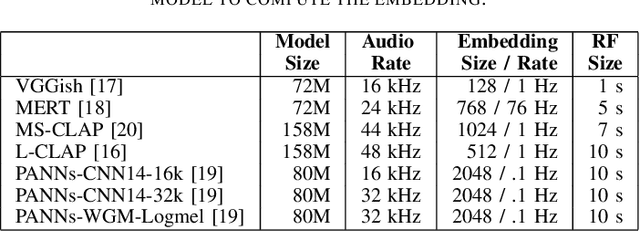
This paper explores whether considering alternative domain-specific embeddings to calculate the Fr\'echet Audio Distance (FAD) metric can help the FAD to correlate better with perceptual ratings of environmental sounds. We used embeddings from VGGish, PANNs, MS-CLAP, L-CLAP, and MERT, which are tailored for either music or environmental sound evaluation. The FAD scores were calculated for sounds from the DCASE 2023 Task 7 dataset. Using perceptual data from the same task, we find that PANNs-WGM-LogMel produces the best correlation between FAD scores and perceptual ratings of both audio quality and perceived fit with a Spearman correlation higher than 0.5. We also find that music-specific embeddings resulted in significantly lower results. Interestingly, VGGish, the embedding used for the original Fr\'echet calculation, yielded a correlation below 0.1. These results underscore the critical importance of the choice of embedding for the FAD metric design.
CAPTDURE: Captioned Sound Dataset of Single Sources
May 28, 2023



In conventional studies on environmental sound separation and synthesis using captions, datasets consisting of multiple-source sounds with their captions were used for model training. However, when we collect the captions for multiple-source sound, it is not easy to collect detailed captions for each sound source, such as the number of sound occurrences and timbre. Therefore, it is difficult to extract only the single-source target sound by the model-training method using a conventional captioned sound dataset. In this work, we constructed a dataset with captions for a single-source sound named CAPTDURE, which can be used in various tasks such as environmental sound separation and synthesis. Our dataset consists of 1,044 sounds and 4,902 captions. We evaluated the performance of environmental sound extraction using our dataset. The experimental results show that the captions for single-source sounds are effective in extracting only the single-source target sound from the mixture sound.
Environmental sound conversion from vocal imitations and sound event labels
Apr 29, 2023



One way of expressing an environmental sound is using vocal imitations, which involve the process of replicating or mimicking the rhythms and pitches of sounds by voice. We can effectively express the features of environmental sounds, such as rhythms and pitches, using vocal imitations, which cannot be expressed by conventional input information, such as sound event labels, images, and texts, in an environmental sound synthesis model. Therefore, using vocal imitations as input for environmental sound synthesis will enable us to control the pitches and rhythms of sounds and generate diverse sounds. In this paper, we thus propose a framework for environmental sound conversion from vocal imitations to generate diverse sounds. We also propose a method of environmental sound synthesis from vocal imitations and sound event labels. Using sound event labels is expected to control the sound event class of the synthesized sound, which cannot be controlled by only vocal imitations. Our objective and subjective experimental results show that vocal imitations effectively control the pitches and rhythms of sounds and generate diverse sounds.
Foley Sound Synthesis at the DCASE 2023 Challenge
Apr 26, 2023


The addition of Foley sound effects during post-production is a common technique used to enhance the perceived acoustic properties of multimedia content. Traditionally, Foley sound has been produced by human Foley artists, which involves manual recording and mixing of sound. However, recent advances in sound synthesis and generative models have generated interest in machine-assisted or automatic Foley synthesis techniques. To promote further research in this area, we have organized a challenge in DCASE 2023: Task 7 - Foley Sound Synthesis. Our challenge aims to provide a standardized evaluation framework that is both rigorous and efficient, allowing for the evaluation of different Foley synthesis systems. Through this challenge, we hope to encourage active participation from the research community and advance the state-of-the-art in automatic Foley synthesis. In this technical report, we provide a detailed overview of the Foley sound synthesis challenge, including task definition, dataset, baseline, evaluation scheme and criteria, and discussion.
Visual onoma-to-wave: environmental sound synthesis from visual onomatopoeias and sound-source images
Oct 17, 2022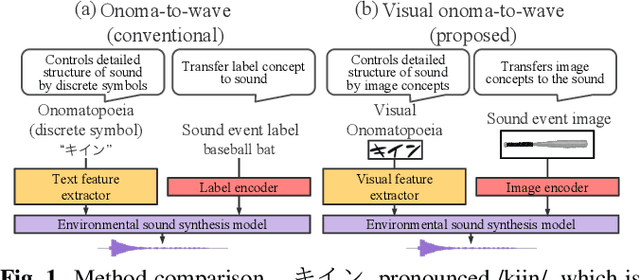
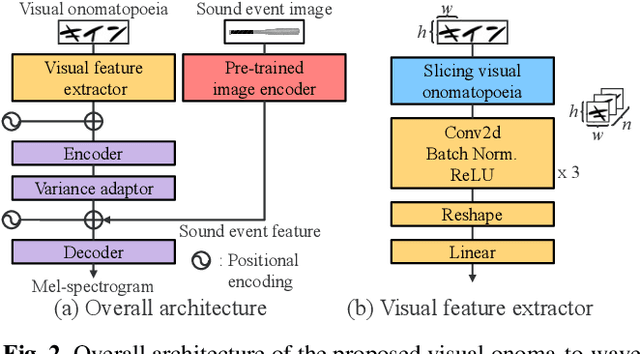

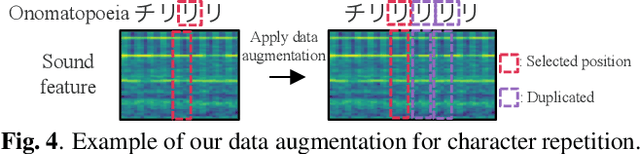
We propose a method for synthesizing environmental sounds from visually represented onomatopoeias and sound sources. An onomatopoeia is a word that imitates a sound structure, i.e., the text representation of sound. From this perspective, onoma-to-wave has been proposed to synthesize environmental sounds from the desired onomatopoeia texts. Onomatopoeias have another representation: visual-text representations of sounds in comics, advertisements, and virtual reality. A visual onomatopoeia (visual text of onomatopoeia) contains rich information that is not present in the text, such as a long-short duration of the image, so the use of this representation is expected to synthesize diverse sounds. Therefore, we propose visual onoma-to-wave for environmental sound synthesis from visual onomatopoeia. The method can transfer visual concepts of the visual text and sound-source image to the synthesized sound. We also propose a data augmentation method focusing on the repetition of onomatopoeias to enhance the performance of our method. An experimental evaluation shows that the methods can synthesize diverse environmental sounds from visual text and sound-source images.
How Should We Evaluate Synthesized Environmental Sounds
Aug 16, 2022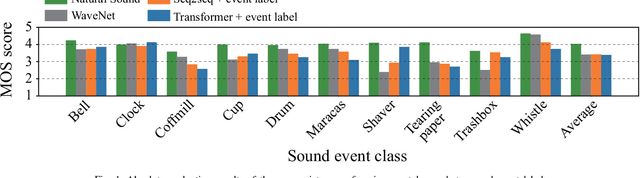
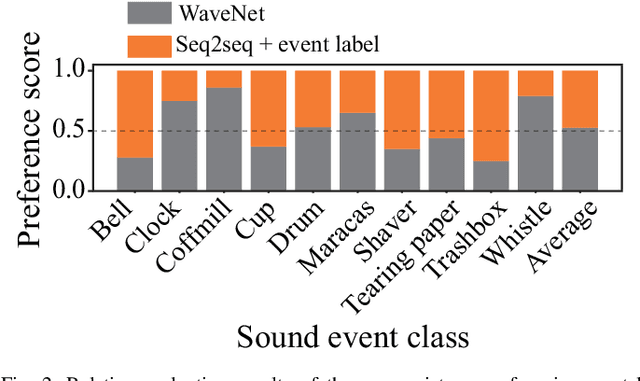
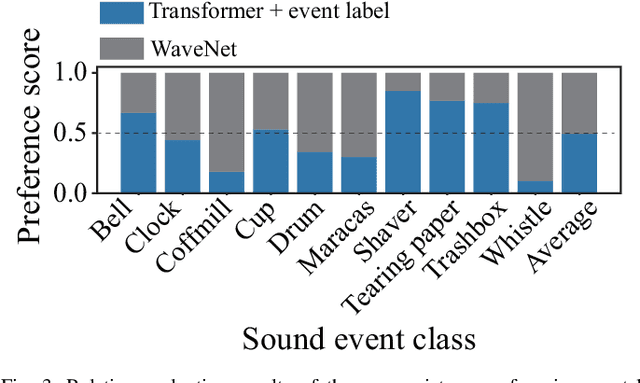
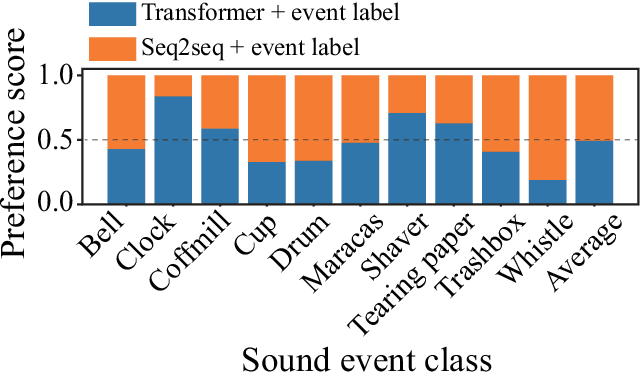
Although several methods of environmental sound synthesis have been proposed, there has been no discussion on how synthesized environmental sounds should be evaluated. Only either subjective or objective evaluations have been conducted in conventional evaluations, and it is not clear what type of evaluation should be carried out. In this paper, we investigate how to evaluate synthesized environmental sounds. We also propose a subjective evaluation methodology to evaluate whether the synthesized sound appropriately represents the information input to the environmental sound synthesis system. In our experiments, we compare the proposed and conventional evaluation methods and show that the results of subjective evaluations tended to differ from those of objective evaluations. From these results, we conclude that it is necessary to conduct not only objective evaluation but also subjective evaluation.
Environmental Sound Extraction Using Onomatopoeia
Dec 02, 2021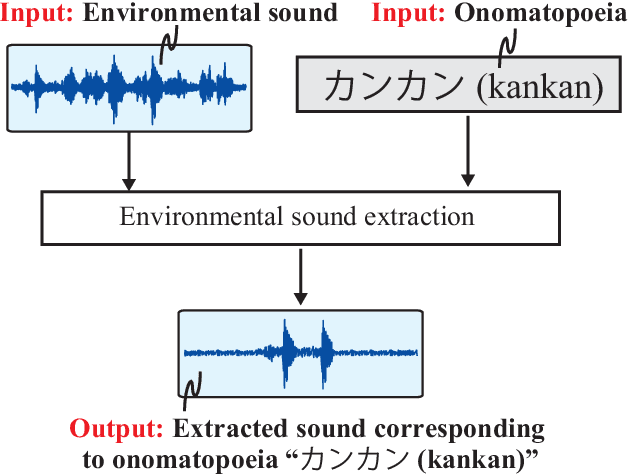
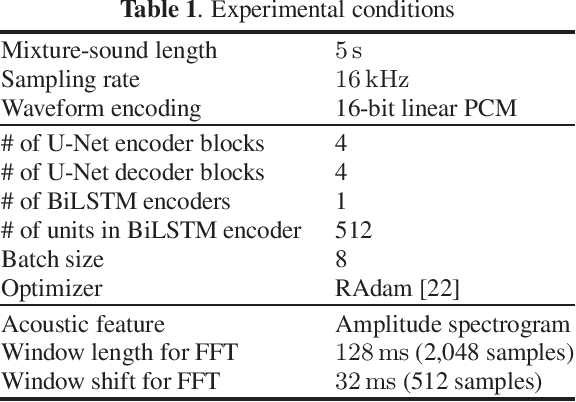
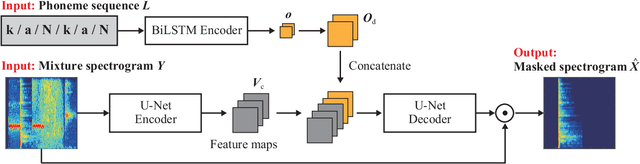
Onomatopoeia, which is a character sequence that phonetically imitates a sound, is effective in expressing characteristics of sound such as duration, pitch, and timbre. We propose an environmental-sound-extraction method using onomatopoeia to specify the target sound to be extracted. With this method, we estimate a time-frequency mask from an input mixture spectrogram and onomatopoeia by using U-Net architecture then extract the corresponding target sound by masking the spectrogram. Experimental results indicate that the proposed method can extract only the target sound corresponding to onomatopoeia and performs better than conventional methods that use sound-event classes to specify the target sound.