 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTuneJury: An Open Metric for Improving Music Generation Preference Alignment
Jun 15, 2026We introduce TuneJury, an open, instance-level pairwise reward model for text-to-music that predicts a music preference score from a text prompt and an audio clip. The released checkpoint is trained on publicly available human-preference labels covering arena-style (A vs. B) votes, metric-alignment preference pairs, crowdsourced pairwise comparisons, and expert aesthetic ratings. The predicted score margin between two clips is well calibrated on our held-out test split, supporting data filtering via a simple score threshold. TuneJury generalizes to both held-out test pairs and out-of-distribution benchmarks, remaining competitive with prior baselines on the latter. For generators released after training, we introduce anchor calibration, a post-hoc, per-system Bradley-Terry calibration that recovers agreement at substantially better data efficiency than from-scratch retraining. The same frozen reward drives consistent reward-axis gains across three downstream applications: inference-time best-of-N selection, DITTO-style latent optimization, and expert-iteration post-training. TuneJury is available at https://github.com/yonghyunk1m/TuneJury.
AdaTT: Text-Guided Instrument Timbre Transfer with Target-Adaptive Structural Control
Jun 14, 2026This paper addresses timbral ambiguity in instrument timbre transfer under fine-grained structural conditions. We argue this issue stems from instrument-specific expressive details in these conditions, which conflict with the target timbral properties. For example, imposing a violin's pitch-dominant vibrato contours onto a flute, which naturally exhibits loudness-dominant vibrato, impairs timbral fidelity. We propose AdaTT, a target-adaptive system that ensures high timbral fidelity across diverse timbre transfer scenarios within the ControlNet scheme. It selectively scales the frame-wise influence of pitch and loudness controls via text prompts to match the target instrument's identity. We also present a semi-automatic data construction pipeline to teach the model which expressive details to transform or preserve. Results show AdaTT achieves superior timbral fidelity and naturalness while retaining score-level content. Audio samples are available at https://dabinkim0.github.io/adatt/.
RLDX-1 Technical Report
May 05, 2026While Vision-Language-Action models (VLAs) have shown remarkable progress toward human-like generalist robotic policies through the versatile intelligence (i.e. broad scene understanding and language-conditioned generalization) inherited from pre-trained Vision-Language Models, they still struggle with complex real-world tasks requiring broader functional capabilities (e.g. motion awareness, memory-aware decision making, and physical sensing). To address this, we introduce RLDX-1, a general-purpose robotic policy for dexterous manipulation built on the Multi-Stream Action Transformer (MSAT), an architecture that unifies these capabilities by integrating heterogeneous modalities through modality-specific streams with cross-modal joint self-attention. RLDX-1 further combines this architecture with system-level design choices, including synthesizing training data for rare manipulation scenarios, learning procedures specialized for human-like manipulation, and inference optimizations for real-time deployment. Through empirical evaluation, we show that RLDX-1 consistently outperforms recent frontier VLAs (e.g. $π_{0.5}$ and GR00T N1.6) across both simulation benchmarks and real-world tasks that require broad functional capabilities beyond general versatility. In particular, RLDX-1 shows superiority in ALLEX humanoid tasks by achieving success rates of 86.8% while $π_{0.5}$ and GR00T N1.6 achieve around 40%, highlighting the ability of RLDX-1 to control a high-DoF humanoid robot under diverse functional demands. Together, these results position RLDX-1 as a promising step toward reliable VLAs for complex, contact-rich, and dynamic real-world dexterous manipulation.
AgentLens: Adaptive Visual Modalities for Human-Agent Interaction in Mobile GUI Agents
Apr 22, 2026Mobile GUI agents can automate smartphone tasks by interacting directly with app interfaces, but how they should communicate with users during execution remains underexplored. Existing systems rely on two extremes: foreground execution, which maximizes transparency but prevents multitasking, and background execution, which supports multitasking but provides little visual awareness. Through iterative formative studies, we found that users prefer a hybrid model with just-in-time visual interaction, but the most effective visualization modality depends on the task. Motivated by this, we present AgentLens, a mobile GUI agent that adaptively uses three visual modalities during human-agent interaction: Full UI, Partial UI, and GenUI. AgentLens extends a standard mobile agent with adaptive communication actions and uses Virtual Display to enable background execution with selective visual overlays. In a controlled study with 21 participants, AgentLens was preferred by 85.7% of participants and achieved the highest usability (1.94 Overall PSSUQ) and adoption-intent (6.43/7).
UNMIXX: Untangling Highly Correlated Singing Voices Mixtures
Jan 19, 2026We introduce UNMIXX, a novel framework for multiple singing voices separation (MSVS). While related to speech separation, MSVS faces unique challenges: data scarcity and the highly correlated nature of singing voices mixture. To address these issues, we propose UNMIXX with three key components: (1) musically informed mixing strategy to construct highly correlated, music-like mixtures, (2) cross-source attention that drives representations of two singers apart via reverse attention, and (3) magnitude penalty loss penalizing erroneously assigned interfering energy. UNMIXX not only addresses data scarcity by simulating realistic training data, but also excels at separating highly correlated mixtures through cross-source interactions at both the architectural and loss levels. Our extensive experiments demonstrate that UNMIXX greatly enhances performance, with SDRi gains exceeding 2.2 dB over prior work.
KAD: No More FAD! An Effective and Efficient Evaluation Metric for Audio Generation
Feb 21, 2025Although being widely adopted for evaluating generated audio signals, the Fr\'echet Audio Distance (FAD) suffers from significant limitations, including reliance on Gaussian assumptions, sensitivity to sample size, and high computational complexity. As an alternative, we introduce the Kernel Audio Distance (KAD), a novel, distribution-free, unbiased, and computationally efficient metric based on Maximum Mean Discrepancy (MMD). Through analysis and empirical validation, we demonstrate KAD's advantages: (1) faster convergence with smaller sample sizes, enabling reliable evaluation with limited data; (2) lower computational cost, with scalable GPU acceleration; and (3) stronger alignment with human perceptual judgments. By leveraging advanced embeddings and characteristic kernels, KAD captures nuanced differences between real and generated audio. Open-sourced in the kadtk toolkit, KAD provides an efficient, reliable, and perceptually aligned benchmark for evaluating generative audio models.
Sound Scene Synthesis at the DCASE 2024 Challenge
Jan 15, 2025This paper presents Task 7 at the DCASE 2024 Challenge: sound scene synthesis. Recent advances in sound synthesis and generative models have enabled the creation of realistic and diverse audio content. We introduce a standardized evaluation framework for comparing different sound scene synthesis systems, incorporating both objective and subjective metrics. The challenge attracted four submissions, which are evaluated using the Fr\'echet Audio Distance (FAD) and human perceptual ratings. Our analysis reveals significant insights into the current capabilities and limitations of sound scene synthesis systems, while also highlighting areas for future improvement in this rapidly evolving field.
Challenge on Sound Scene Synthesis: Evaluating Text-to-Audio Generation
Oct 23, 2024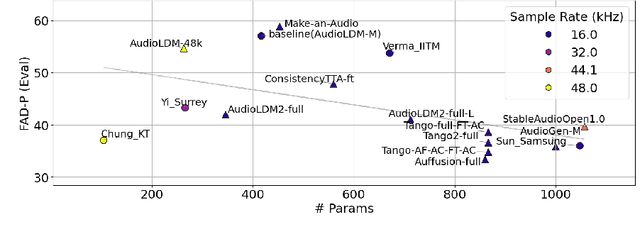
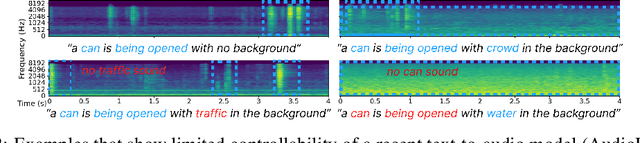
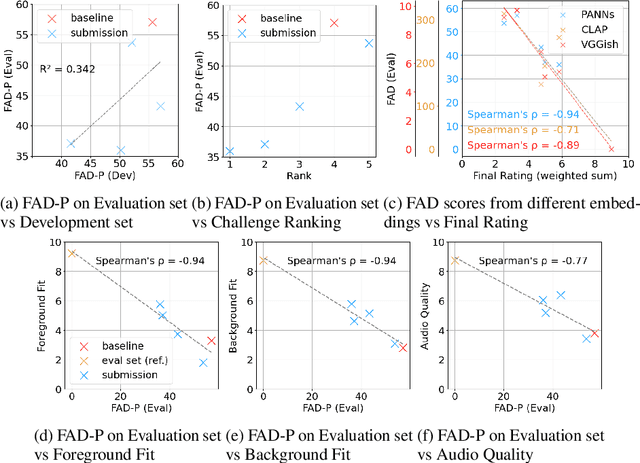
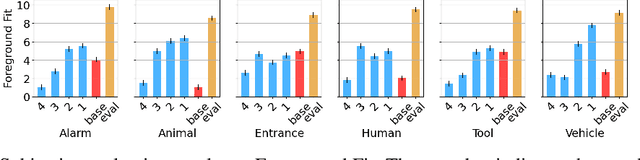
Despite significant advancements in neural text-to-audio generation, challenges persist in controllability and evaluation. This paper addresses these issues through the Sound Scene Synthesis challenge held as part of the Detection and Classification of Acoustic Scenes and Events 2024. We present an evaluation protocol combining objective metric, namely Fr\'echet Audio Distance, with perceptual assessments, utilizing a structured prompt format to enable diverse captions and effective evaluation. Our analysis reveals varying performance across sound categories and model architectures, with larger models generally excelling but innovative lightweight approaches also showing promise. The strong correlation between objective metrics and human ratings validates our evaluation approach. We discuss outcomes in terms of audio quality, controllability, and architectural considerations for text-to-audio synthesizers, providing direction for future research.
Video-Foley: Two-Stage Video-To-Sound Generation via Temporal Event Condition For Foley Sound
Aug 21, 2024



Foley sound synthesis is crucial for multimedia production, enhancing user experience by synchronizing audio and video both temporally and semantically. Recent studies on automating this labor-intensive process through video-to-sound generation face significant challenges. Systems lacking explicit temporal features suffer from poor controllability and alignment, while timestamp-based models require costly and subjective human annotation. We propose Video-Foley, a video-to-sound system using Root Mean Square (RMS) as a temporal event condition with semantic timbre prompts (audio or text). RMS, a frame-level intensity envelope feature closely related to audio semantics, ensures high controllability and synchronization. The annotation-free self-supervised learning framework consists of two stages, Video2RMS and RMS2Sound, incorporating novel ideas including RMS discretization and RMS-ControlNet with a pretrained text-to-audio model. Our extensive evaluation shows that Video-Foley achieves state-of-the-art performance in audio-visual alignment and controllability for sound timing, intensity, timbre, and nuance. Code, model weights, and demonstrations are available on the accompanying website. (https://jnwnlee.github.io/video-foley-demo)
CONMOD: Controllable Neural Frame-based Modulation Effects
Jun 20, 2024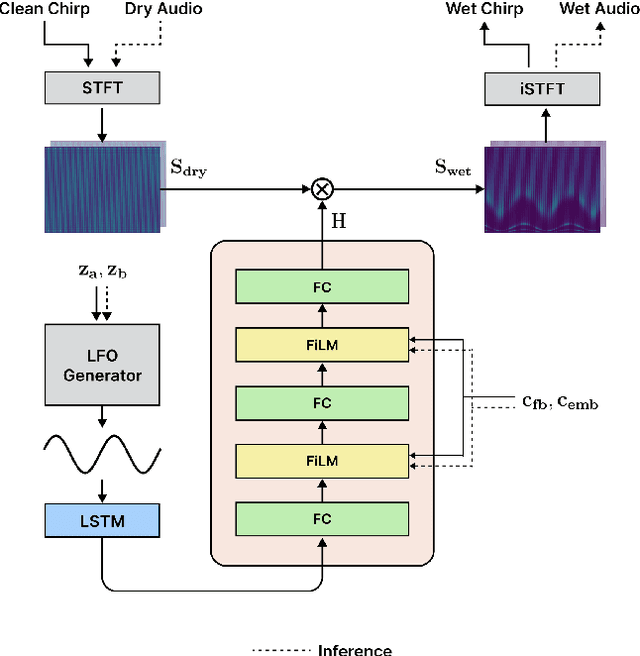

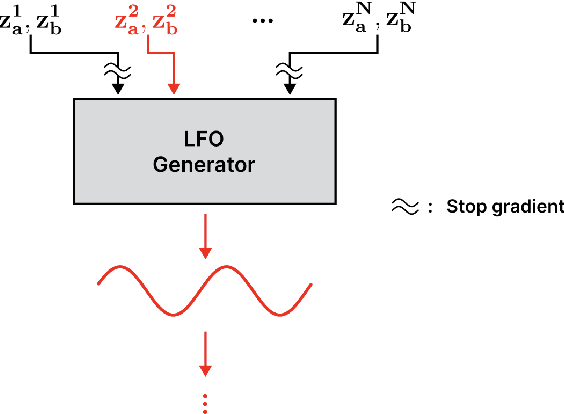
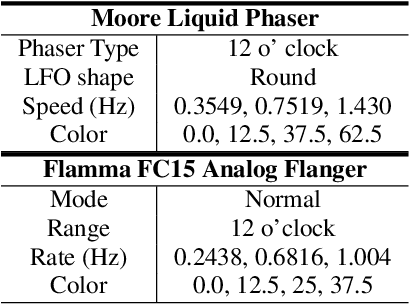
Deep learning models have seen widespread use in modelling LFO-driven audio effects, such as phaser and flanger. Although existing neural architectures exhibit high-quality emulation of individual effects, they do not possess the capability to manipulate the output via control parameters. To address this issue, we introduce Controllable Neural Frame-based Modulation Effects (CONMOD), a single black-box model which emulates various LFO-driven effects in a frame-wise manner, offering control over LFO frequency and feedback parameters. Additionally, the model is capable of learning the continuous embedding space of two distinct phaser effects, enabling us to steer between effects and achieve creative outputs. Our model outperforms previous work while possessing both controllability and universality, presenting opportunities to enhance creativity in modern LFO-driven audio effects.